2. LLM 基础与生成机制
1. 大语言模型(LLM)基础:自回归生成、Tokenization 与指令微调
VLA 模型的 "大脑":理解 LLM 如何处理序列、生成输出,以及如何将动作也当作语言来预测。
阅读指南
本章内容较多,按重要性分为两个部分:
- Part A(必读):1-3 + 8——LLM 的核心原理,理解后续章节的基础
- Part B(核心):4-5——指令微调和动作 token 化,VLA 的关键
Part A(必读)
2. VLA 中 LLM 的角色
2.1 为什么 VLA 需要 LLM?
VLA(Vision-Language-Action)的核心思想是:把机器人控制问题转化为序列生成问题。
传统机器人控制:
状态 → [控制算法] → 动作
需要手工设计状态表示和控制策略
VLA 的思路:
图像 + 语言指令 → [LLM] → 动作序列
利用 LLM 强大的序列建模能力
LLM 在 VLA 中承担的功能:
| 功能 | 说明 |
|---|---|
| 指令理解 | 理解 "把红色方块放到蓝色盘子里" 这样的自然语言指令 |
| 视觉推理 | 结合视觉特征,理解当前场景(物体位置、状态) |
| 动作生成 | 输出机器人应该执行的动作序列 |
| 常识推理 | 利用预训练知识进行推理(如:杯子要正着放) |
2.2 VLA 中 LLM 的输入输出
输入:[视觉 Token] + [语言 Token]
↓
LLM
↓
输出:[动作 Token] 或 [连续动作值]
具体例子:
输入:<img_1><img_2>...<img_256> Pick up the red block
输出:<action_1><action_2>...<action_7> (7-DoF 机械臂动作)
3. 自回归生成原理
3.1 什么是自回归(Autoregressive)生成?
核心思想:一个 token 一个 token 地生成,每次生成都依赖于之前生成的所有 token。
数学表达:
直观理解:
生成句子 "I love cats"
Step 1: P("I" | <BOS>) → 生成 "I"
Step 2: P("love" | "I") → 生成 "love"
Step 3: P("cats" | "I love") → 生成 "cats"
Step 4: P(<EOS> | "I love cats") → 结束
3.2 Causal Mask:保证自回归性质
在 Transformer 中,Self-Attention 默认会让每个位置看到所有位置。要实现自回归,需要用 Causal Mask(因果掩码) 来阻止看到未来信息。
位置 1 位置 2 位置 3 位置 4
Causal Mask: 位置 1 [ 0 -∞ -∞ -∞ ]
位置 2 [ 0 0 -∞ -∞ ]
位置 3 [ 0 0 0 -∞ ]
位置 4 [ 0 0 0 0 ]
0 = 可以看到
-∞ = 看不到(softmax 后变成 0)
代码实现:
import torch
import torch.nn as nn
def create_causal_mask(seq_len: int, device: torch.device) -> torch.Tensor:
"""创建因果掩码(上三角为 -inf,阻止每个位置看到其后的 token)"""
mask = torch.triu(torch.ones(seq_len, seq_len, device=device), diagonal=1)
mask = mask.masked_fill(mask == 1, float('-inf'))
return mask # (seq_len, seq_len)
def causal_attention(Q, K, V, mask=None):
"""带因果掩码的注意力计算"""
d_k = Q.shape[-1]
# (B, H, L, L):计算每对位置的相关性分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)
if mask is not None:
scores = scores + mask # -inf 位置在 softmax 后趋近于 0,相当于屏蔽未来信息
attn_weights = torch.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, V)
return output
3.3 Prefill 与 Decode 阶段
LLM 推理分为两个阶段:
阶段 1:Prefill(预填充)
处理所有输入 token,一次性并行计算
输入:[视觉token] + [语言token]
输出:所有位置的 KV Cache(供 Decode 阶段复用)
阶段 2:Decode(解码)
一个 token 一个 token 地生成输出
每步只处理 1 个新 token,复用已有 KV Cache
直到生成 EOS 或达到最大长度
关键区别:Prefill 是批量并行的(快),Decode 是逐步串行的(慢,是推理延迟的主要来源)。从硬件利用角度看,Prefill 阶段是计算密集型——需要对所有输入 token 做大量矩阵乘法,GPU 算力是瓶颈;Decode 阶段则是访存密集型——每步只处理 1 个新 token,但需要从显存中读取整个 KV Cache 来计算注意力,显存带宽成为瓶颈。这也是为什么长序列生成时 Decode 阶段的延迟远高于 Prefill。
3.4 KV Cache:加速自回归生成
问题:每生成一个 token,都要重新计算之前所有 token 的注意力?
解决方案:缓存之前的 Key 和 Value,新 token 只需要计算自己的 K、V 并追加。
不用 KV Cache(慢):
Step 1: 计算 [t1] 的 K,V
Step 2: 计算 [t1, t2] 的 K,V(t1 重复计算了!)
Step 3: 计算 [t1, t2, t3] 的 K,V(t1, t2 重复计算了!)
用 KV Cache(快):
Step 1: 计算 [t1] 的 K,V,存入 cache
Step 2: 计算 [t2] 的 K,V,拼接到 cache
Step 3: 计算 [t3] 的 K,V,拼接到 cache
核心思想(伪代码):
# KV Cache 核心逻辑(概念示意)
cache_k, cache_v = [], [] # 每层维护一个缓存
for new_token in decode_loop:
# 只对新 token 计算 K、V
k_new = linear_k(new_token) # (B, 1, head_dim)
v_new = linear_v(new_token) # (B, 1, head_dim)
# 将新 K、V 追加到历史缓存中(避免重复计算)
cache_k = torch.cat([cache_k, k_new], dim=1) # (B, seq+1, head_dim)
cache_v = torch.cat([cache_v, v_new], dim=1)
# 用完整缓存做注意力,只输出新 token 对应的位置
output = attention(q=linear_q(new_token), k=cache_k, v=cache_v)
值得注意的是,KV Cache 的显存开销与序列长度成正比——每多生成一个 token,就要多缓存一组 K、V 向量(每层、每个注意力头各一份)。对于长上下文场景(如数千 token 的输入),KV Cache 可能占据数 GB 显存,成为部署时的主要显存瓶颈。工程上常用 PagedAttention、量化 KV Cache 等技术来缓解这一问题。
4. Tokenization:从文本到数字
4.1 为什么需要 Tokenization?
LLM 无法直接处理文本,需要将文本转换为数字序列:
"Hello world" → Tokenizer → [15496, 995] → Embedding → 向量序列
4.2 主流 Tokenization 方法
| 方法 | 代表 | 原理 | 词表大小 |
|---|---|---|---|
| BPE | GPT-2, LLaMA | 基于频率合并字符对 | 32K-128K |
| WordPiece | BERT | 基于似然合并 | 30K |
| Unigram | T5, SentencePiece | 基于概率剪枝 | 32K |
| SentencePiece | LLaMA, Mistral | BPE/Unigram 的实现 | 可配置 |
4.3 BPE(Byte Pair Encoding)详解
训练过程:
初始:将所有文本拆成单字符
词表 = {'a', 'b', 'c', ..., 'z', ' ', ...}
迭代合并最频繁的相邻对:
Round 1: 't' + 'h' → 'th' (假设 "th" 出现最多)
Round 2: 'th' + 'e' → 'the'
Round 3: 'i' + 'n' → 'in'
...
直到词表达到目标大小(如 32000)
编码过程:
输入: "the cat"
查找最长匹配的 token:
"the" → 在词表中 → token_id = 1234
" " → token_id = 220
"cat" → 在词表中 → token_id = 5678
输出: [1234, 220, 5678]
4.4 使用 HuggingFace Tokenizer
from transformers import AutoTokenizer
# 加载 LLaMA 的 tokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
# 编码(文本 → token ids)
tokens = tokenizer.encode("Pick up the red block")
print(tokens) # [1, 29875, ...] 对应 <s>, Pick, up, the, red, block
# 解码(token ids → 文本)
print(tokenizer.decode(tokens)) # "<s> Pick up the red block"
编码和解码是互逆操作。实际使用中,批量编码可通过 tokenizer(texts, padding=True, return_tensors="pt") 完成,会自动处理 padding 和 attention mask。
4.5 特殊 Token
# 常见特殊 token 及其 ID
print(tokenizer.bos_token, tokenizer.bos_token_id) # <s> 1 —— 句子开始
print(tokenizer.eos_token, tokenizer.eos_token_id) # </s> 2 —— 句子结束
除 BOS/EOS 外,不同模型还会定义 pad_token(填充)和 unk_token(未知 token)等特殊标记,具体取决于模型的 tokenizer 配置。
4.6 VLA 中的 Tokenization 考量
在 VLA 中,除了文本,还需要处理视觉 token 和动作 token:
完整输入序列:
[BOS] [IMG_1] [IMG_2] ... [IMG_N] [TEXT_1] [TEXT_2] ... [TEXT_M] [ACT_1] [ACT_2] ...
三种 token 的来源:
1. 视觉 token:图像经过视觉编码器 + 投影层得到
2. 文本 token:通过标准 tokenizer 编码
3. 动作 token:动作值离散化后得到(见 5. 指令微调)
Part B(核心)
5. 指令微调(Instruction Tuning)
5.1 从预训练到指令遵循
预训练 LLM 的问题:只会"续写",不会"遵循指令"
预训练模型输入:
"What is the capital of France?"
预训练模型输出:
"What is the capital of Germany? What is the capital of Spain?..."
(它只是在续写类似的问题,而不是回答问题)
指令微调后:
输入:"What is the capital of France?"
输出:"The capital of France is Paris."
5.2 SFT(Supervised Fine-Tuning)
核心思想:用(指令, 回复)对来微调模型
训练数据格式:
{
"instruction": "Translate the following to French",
"input": "Hello, how are you?",
"output": "Bonjour, comment allez-vous?"
}
转换为训练序列:
<s> [INST] Translate the following to French: Hello, how are you? [/INST]
Bonjour, comment allez-vous? </s>
损失函数:只在 response 部分计算交叉熵损失
def compute_sft_loss(logits, labels, response_mask):
"""
SFT 损失:只在回复部分计算
logits: (B, L, V) 模型对每个位置、每个词表 token 的预测分布
labels: (B, L) 目标 token ID
response_mask: (B, L) 1 表示回复部分,0 表示指令部分
"""
# 移位对齐:logits[t] 用来预测 labels[t+1]
shift_logits = logits[..., :-1, :].contiguous() # (B, L-1, V)
shift_labels = labels[..., 1:].contiguous() # (B, L-1)
shift_mask = response_mask[..., 1:].contiguous()
# 逐 token 计算交叉熵,不做 reduction,保留每个位置的 loss
loss_fct = nn.CrossEntropyLoss(reduction='none')
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), # (B*(L-1), V)
shift_labels.view(-1) # (B*(L-1),)
)
loss = loss.view(shift_labels.shape) # (B, L-1)
# 只在 response 部分计算平均损失,指令部分不监督
loss = (loss * shift_mask).sum() / shift_mask.sum()
return loss
5.3 对话模板(Chat Template)
不同模型有不同的对话格式:
# LLaMA 2 Chat 格式
llama2_template = """<s>[INST] <<SYS>>
{system_message}
<</SYS>>
{user_message} [/INST] {assistant_message} </s>"""
# Mistral 格式
mistral_template = """<s>[INST] {user_message} [/INST] {assistant_message}</s>"""
# ChatML 格式 (Qwen, etc.)
chatml_template = """<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{user_message}<|im_end|>
<|im_start|>assistant
{assistant_message}<|im_end|>"""
5.4 RLHF(Reinforcement Learning from Human Feedback)
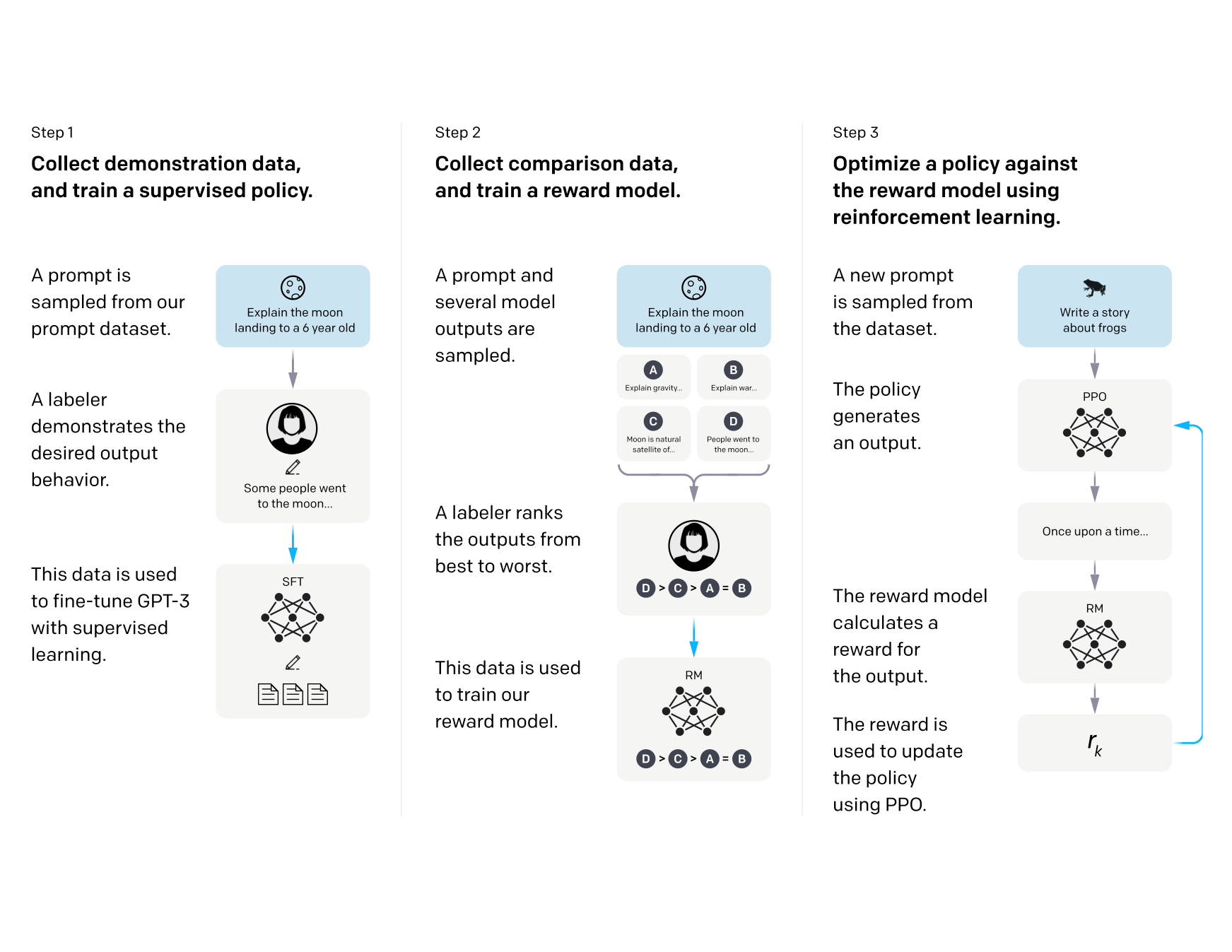
SFT 之后,通常还会用 RLHF 进一步对齐人类偏好:
RLHF 流程:
1. SFT:用高质量数据微调
2. 训练 Reward Model:学习人类偏好
3. PPO 强化学习:用 reward 信号优化策略
简化理解:
- SFT 学会"能"回答问题
- RLHF 学会"好好"回答问题
5.5 VLA 中的指令微调
VLA 的 SFT 数据格式:
# VLA 训练样本
{
"image": "path/to/image.jpg", # 视觉输入
"instruction": "Pick up the red block", # 语言指令
"actions": [0.1, -0.2, 0.05, 0.0, 0.0, 0.1, 1.0] # 7-DoF 动作
}
# 转换为序列
# [IMG_TOKENS] + [TEXT_TOKENS] + [ACTION_TOKENS]
# 损失只在 [ACTION_TOKENS] 部分计算
VLA 训练数据格式与普通 LLM 的区别
普通 LLM 的训练序列只包含文本 token;VLA 的序列则由三类异构 token 拼接而成:视觉 token(由图像编码器提取后投影到语言空间)、文本 token(自然语言指令)和动作 token(连续动作值离散化后的 ID)。三类 token 在同一条序列中按顺序排列:[IMG_1...IMG_N] [TEXT_1...TEXT_M] [ACT_1...ACT_K]。损失函数只在动作 token 部分计算,视觉和语言部分不参与监督——这与普通 SFT 中"只在 response 部分计算损失"的思路完全一致,只是 response 从文字变成了动作。这种设计让 LLM 骨干网络天然复用,同时将机器人控制问题转化为标准的 next-token 预测。
6. VLA 的核心思想:动作即语言 Token
6.1 动作 Token 化的动机
关键洞察:既然 LLM 擅长预测下一个 token,为什么不把机器人动作也变成 token 来预测?
传统思路:LLM 输出一个连续向量,再回归成动作
缺点:回归任务与 LLM 预训练目标不一致
VLA 思路:把动作离散化成 token,LLM 直接预测动作 token
优点:复用 LLM 的序列建模能力
6.2 动作空间介绍
机器人动作空间通常是多维连续空间:
| 动作类型 | 维度 | 说明 |
|---|---|---|
| 末端执行器位置 | 3 | (x, y, z) 空间坐标 |
| 末端执行器姿态 | 3-4 | (roll, pitch, yaw) 或四元数 |
| 夹爪开合 | 1 | 0=闭合, 1=张开 |
| 总计(7-DoF) | 7 | 常见的机械臂动作空间 |
一个动作向量示例:
action = [
0.05, # delta_x: 向右移动 5cm
-0.02, # delta_y: 向后移动 2cm
0.10, # delta_z: 向上移动 10cm
0.0, # delta_roll
0.0, # delta_pitch
-0.1, # delta_yaw: 绕 z 轴旋转
1.0 # gripper: 张开
]
6.3 动作离散化(Action Discretization)
方法 1:均匀分桶(Uniform Binning)
RT-2 采用的方法,将每个动作维度均匀离散化:
def discretize_action(action, num_bins=256, action_min=-1.0, action_max=1.0):
"""
将连续动作离散化为 token ID
action: (action_dim,) 连续动作值,例如 7-DoF
num_bins: 每个维度的离散桶数,越大精度越高
返回: (action_dim,) 离散 token ID,范围 [0, num_bins-1]
"""
# 裁剪到有效范围,防止越界
action = np.clip(action, action_min, action_max)
# 归一化到 [0, 1]
normalized = (action - action_min) / (action_max - action_min)
# 映射到 [0, num_bins-1] 并取整
discrete = (normalized * (num_bins - 1)).astype(np.int32)
return discrete
def undiscretize_action(discrete, num_bins=256, action_min=-1.0, action_max=1.0):
"""
将离散 token 还原为连续动作(discretize_action 的逆操作)
"""
normalized = discrete.astype(np.float32) / (num_bins - 1) # [0, 1]
action = normalized * (action_max - action_min) + action_min
return action
# 示例
action = np.array([0.05, -0.02, 0.10, 0.0, 0.0, -0.1, 1.0])
discrete = discretize_action(action, num_bins=256, action_min=-1, action_max=1)
print(discrete) # 例如: [141, 123, 166, 128, 128, 115, 255]
方法 2:K-Means 聚类
对历史动作数据进行聚类,用聚类中心作为离散动作:
from sklearn.cluster import KMeans
class KMeansActionTokenizer:
"""基于 K-Means 的动作离散化:用聚类中心代替均匀分桶,更贴合实际数据分布"""
def __init__(self, n_clusters=512):
self.n_clusters = n_clusters
self.kmeans = None
def fit(self, actions):
"""
actions: (N, action_dim) 历史动作数据,用于拟合聚类中心
"""
self.kmeans = KMeans(n_clusters=self.n_clusters, random_state=42)
self.kmeans.fit(actions)
def encode(self, action):
"""连续动作 → 最近聚类中心的 ID(离散 token)"""
return self.kmeans.predict(action.reshape(1, -1))[0]
def decode(self, token_id):
"""离散 token → 聚类中心(还原为近似连续动作)"""
return self.kmeans.cluster_centers_[token_id]
6.4 将动作 Token 加入词表
class VLATokenizer:
"""
VLA 的 Tokenizer:在原文本词表后追加动作 token 空间。
核心设计:为每个动作维度分配独立的 token 区间,避免不同维度的 bin 相互混淆。
例如(256 bins,7 维):
dim_0 → token [32000, 32255]
dim_1 → token [32256, 32511]
...
dim_6 → token [33536, 33791]
"""
def __init__(self, text_tokenizer, num_action_bins=256, action_dim=7):
self.text_tokenizer = text_tokenizer
self.num_action_bins = num_action_bins
self.action_dim = action_dim
# 动作 token 从文本词表末尾开始编号
self.action_token_start = len(text_tokenizer)
def encode_action(self, action):
"""
action: (action_dim,) 连续动作
返回: (action_dim,) 动作 token IDs
"""
discrete = discretize_action(action, self.num_action_bins)
token_ids = []
for dim_idx, bin_idx in enumerate(discrete):
# 每个维度有独立的 token 区间,偏移量 = dim_idx × num_bins
token_id = self.action_token_start + dim_idx * self.num_action_bins + bin_idx
token_ids.append(token_id)
return token_ids
def decode_action(self, token_ids):
"""
token_ids: (action_dim,) 动作 token IDs
返回: (action_dim,) 连续动作
"""
discrete = []
for dim_idx, token_id in enumerate(token_ids):
# 逆推 bin_idx:减去基础偏移和维度偏移
bin_idx = token_id - self.action_token_start - dim_idx * self.num_action_bins
discrete.append(bin_idx)
action = undiscretize_action(np.array(discrete), self.num_action_bins)
return action
6.5 RT-2 的动作 Token 化方案

RT-2 的一个关键设计决策是复用已有的数字文本 token("0"~"255")来表示动作,而不是新增专用 token。这样做的好处是无需修改词表大小和 Embedding 层,可以直接在冻结的 VLM 上微调;同时,预训练阶段模型已经见过大量数字文本,对数字的语义有一定理解,降低了从零学习动作表示的难度。代价是动作 token 与普通数字文本共享同一表示空间,模型需要仅靠上下文来区分"这是一个动作值"还是"这是一段普通数字"。
RT-2 的具体实现细节:
RT-2 动作 token 设计:
1. 每个动作维度用 256 bins 离散化
2. 动作维度:7 (x, y, z, roll, pitch, yaw, gripper)
3. 总共需要 7 × 256 = 1792 个新 token
新 token 的文本表示:
bin 0 → "0"
bin 1 → "1"
...
bin 255 → "255"
输出序列示例:
"128 140 100 128 128 115 255"
↓ 解析
[128, 140, 100, 128, 128, 115, 255]
↓ 反离散化
[0.0, 0.1, -0.2, 0.0, 0.0, -0.1, 1.0]
def generate_action_rt2(model, tokenizer, image_features, instruction):
"""
RT-2 风格:直接生成动作数字的文本表示,再解析为连续值
"""
# 构建提示词,引导模型输出动作序列
prompt = f"Instruction: {instruction}\nAction:"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# 自回归生成 7 个离散动作值(数字字符串)
outputs = model.generate(
input_ids,
image_features=image_features,
max_new_tokens=7 * 4, # 每个数字最多 4 个字符(如 "255 ")
num_beams=1, # 贪婪解码,保证动作确定性
)
# 解析输出字符串中的 7 个整数
output_text = tokenizer.decode(outputs[0])
action_str = output_text.split("Action:")[-1].strip()
action_bins = [int(x) for x in action_str.split()[:7]]
# 将离散 bin 反映射为连续动作值
action = undiscretize_action(np.array(action_bins))
return action
6.6 OpenVLA 的动作 Token 化方案
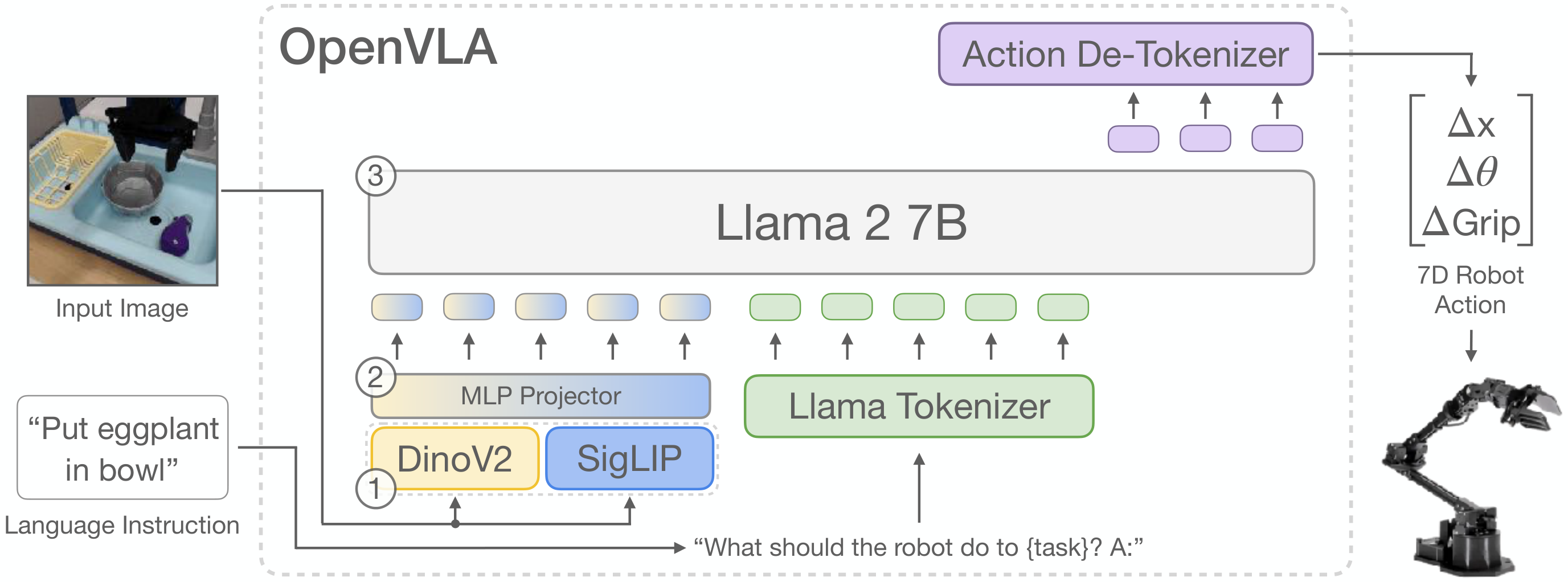
OpenVLA 对 RT-2 的改进:为动作 token 分配专门的词表空间
相比 RT-2 复用数字文本 token,专用动作 token 的优势在于:模型可以为动作学到独立的 Embedding 表示,不会与原有词表中数字的语义产生冲突(例如"128"在文本中可能表示一个数量,但在动作中表示某个维度的中间值)。这让模型更容易区分"正在输出动作"和"正在输出文字",训练收敛也更稳定。
class OpenVLAActionTokenizer:
"""
OpenVLA 的动作 token 化:添加 256 个专用特殊 token 代替复用数字文本 token,
避免与原有词表语义冲突,也让模型更容易区分"动作输出"和"文字输出"。
"""
def __init__(self, base_tokenizer, num_bins=256):
# 添加 256 个专属动作 token:<action_0> ~ <action_255>
special_tokens = [f"<action_{i}>" for i in range(num_bins)]
base_tokenizer.add_special_tokens({'additional_special_tokens': special_tokens})
self.tokenizer = base_tokenizer
# 预先查好每个动作 token 对应的 ID,推理时直接使用
self.action_token_ids = [
base_tokenizer.convert_tokens_to_ids(f"<action_{i}>")
for i in range(num_bins)
]
def encode_action(self, action, action_min, action_max):
"""将 7-DoF 连续动作编码为 7 个专属动作 token ID"""
action = np.clip(action, action_min, action_max)
normalized = (action - action_min) / (action_max - action_min) # [0, 1]
bins = (normalized * 255).astype(np.int32) # [0, 255]
# 将每维的 bin 映射到对应的专属 token ID
token_ids = [self.action_token_ids[b] for b in bins]
return token_ids
6.7 离散化 vs 连续输出
| 方法 | 代表模型 | 优点 | 缺点 |
|---|---|---|---|
| 离散化(Token) | RT-2, OpenVLA | 复用 LLM 能力,训练简单 | 精度受限于桶数 |
| 连续回归 | Octo, 部分方法 | 精度高 | 需要额外的回归头 |
| Diffusion Head | π0 | 处理多模态分布 | 推理速度慢 |
9. 总结
9.1 核心知识速查
| 概念 | 一句话总结 |
|---|---|
| 自回归生成 | 依次生成 token,每个 token 依赖之前所有 token |
| Causal Mask | 上三角掩码,防止看到未来信息 |
| KV Cache | 缓存历史 K/V,避免重复计算 |
| Tokenization | 文本 → token ID 的转换,主流用 BPE |
| SFT | 用(指令,回复)对监督微调 LLM |
| 动作 Token 化 | 把连续动作离散化为 token,让 LLM 直接预测 |
| 贪婪解码 | VLA 推理中最常用,保证动作确定性 |
| LoRA | 参数高效微调,VLA 训练中常用 |
9.2 VLA 中 LLM 的核心要点
1. 输入构成:[视觉 Token] + [语言 Token]
2. 输出目标:预测 [动作 Token]
3. 训练方式:SFT,只在动作部分计算损失
4. 推理方式:贪婪解码,确保动作确定性
5. 微调方法:LoRA,参数高效
10. 参考资料
- Attention Is All You Need - Transformer
- Language Models are Few-Shot Learners - GPT-3
- LLaMA: Open and Efficient Foundation Language Models
- Training language models to follow instructions with human feedback - InstructGPT
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- OpenVLA: An Open-Source Vision-Language-Action Model
- LoRA: Low-Rank Adaptation of Large Language Models
- HuggingFace Transformers 文档
- HuggingFace PEFT 文档