5. 多模态融合与 VLM
本章围绕一条清晰主线展开:视觉特征如何进入 LLM,并最终支持 VLA 的动作决策。阅读时可以按“问题定义 → 架构实现 → 对齐方法 → 工程落地”四步推进。
1. 问题定义:VLM 在解决什么
1.1 什么是多模态模型?
多模态模型能够同时理解和处理多种类型的数据,例如文本、图像、音频和视频。
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 图像 │ │ 文本 │ │ 音频 │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
▼ ▼ ▼
┌──────────────────────────────────────┐
│ 多模态模型 (MLLM) │
│ (Multimodal Large Language Model) │
└──────────────────────────────────────┘
│
▼
理解 + 生成(文本回复、图像描述等)
1.2 发展历程
| 年份 | 里程碑 | 核心创新 |
|---|---|---|
| 2021 | CLIP | 图文对比学习 |
| 2022 | Flamingo | 视觉语言少样本学习 |
| 2023 | LLaVA | 视觉指令微调 |
| 2023 | GPT-4V | 商业化多模态 |
| 2024 | LLaVA-NeXT | 高分辨率理解 |
1.3 CLIP 在 VLM 中的关键作用
CLIP 的训练原理和对比学习细节已经在前一章讲过,这里只保留从 VLM 构建角度最重要的两点:
-
patch token 保留了空间信息:CLIP ViT 输出的不只是一个全局向量,而是每个图像 patch 对应一个 token,例如 256 个 patch 就是 256 个向量。这些 patch token 携带“哪里有什么”的空间信息,对于需要定位物体的任务很重要。
-
特征维度与 LLM 不匹配:CLIP 输出的视觉特征维度可能是 1024,而 LLM 的隐藏维度可能是 4096。两者还处于不同的语义空间中,所以需要投影层来做桥接。
CLIP ViT 输出 投影层 LLM 输入
(B, 256, 1024) → Linear/MLP → (B, 256, 4096)
视觉 token 可被 LLM 理解的格式
1.4 从 VLM 到 VLA 的接口问题
VLM 的核心问题不是“看见图像”本身,而是把图像转成语言模型可消费的序列表示:
- 视觉特征如何进入文本序列。
- 图像 token 的数量如何控制。
- 视觉信息如何和语言指令对齐。
- 这种表示如何进一步映射到动作空间。
这四个问题会贯穿后面的架构、对齐和 VLA 章节。
2. 主流 VLM 架构与训练范式
2.1 LLaVA:视觉指令微调
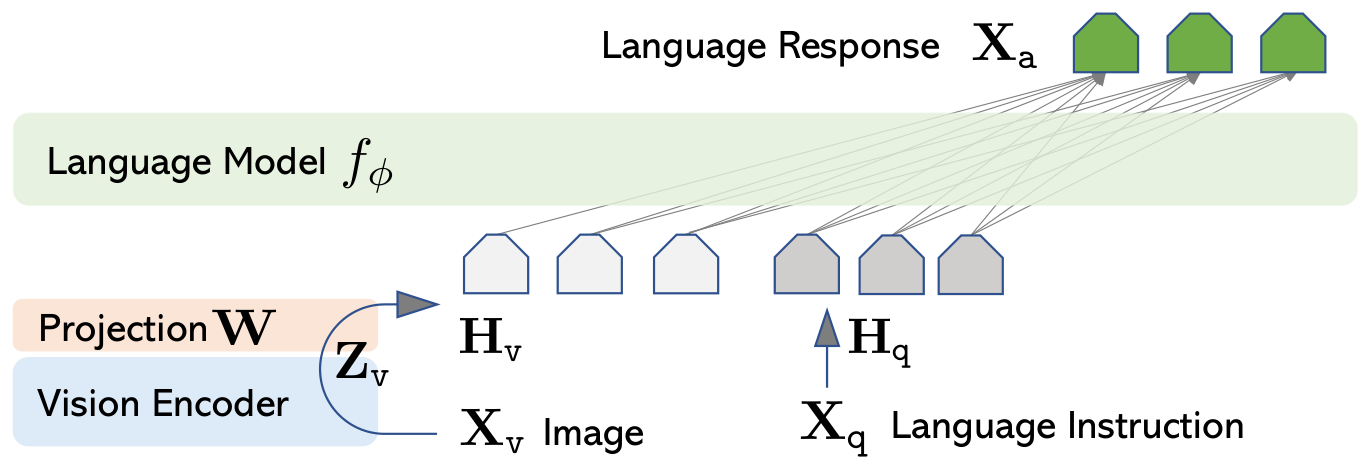
2.1.1 核心思想
LLaVA (Large Language and Vision Assistant) 将视觉能力注入 LLM,实现图像理解与对话。
┌─────────┐ ┌─────────────────┐
│ 图像 │ │ 用户问题 │
└────┬────┘ └────────┬────────┘
│ │
▼ │
┌─────────────┐ │
│ CLIP ViT │ │
│ (冻结) │ │
└─────────────┘ │
│ │
▼ │
┌─────────────┐ │
│ 投影层 │ │
│ (可训练) │ │
└─────────────┘ │
│ │
└──────────────┬───────────────────┘
│
▼
┌───────────────┐
│ LLM (LLaMA) │
│ (可训练) │
└───────────────┘
│
▼
回答/描述
2.1.2 架构详解
LLaVA 的核心操作是序列拼接:把投影后的视觉特征和文本 embedding 直接拼接成一个统一的序列,再整体送入 LLM。LLM 使用统一的自注意力机制处理这个混合序列,视觉 token 和文本 token 可以互相关注,模型无需额外的跨模态模块即可实现视觉与语言的深度交互。
class LLaVA(nn.Module):
"""LLaVA 模型实现"""
def __init__(
self,
vision_encoder,
language_model,
vision_hidden_size=1024,
llm_hidden_size=4096,
):
super().__init__()
self.vision_encoder = vision_encoder
for param in self.vision_encoder.parameters():
param.requires_grad = False
self.mm_projector = nn.Sequential(
nn.Linear(vision_hidden_size, llm_hidden_size),
nn.GELU(),
nn.Linear(llm_hidden_size, llm_hidden_size),
)
self.language_model = language_model
def encode_images(self, images):
"""提取视觉特征"""
# 用冻结的视觉编码器提取 patch 特征,再通过可训练投影层对齐 LLM 维度
with torch.no_grad():
image_features = self.vision_encoder.forward_features(images)
image_features = self.mm_projector(image_features)
return image_features
def forward(self, images, input_ids, attention_mask, labels=None):
image_features = self.encode_images(images)
text_embeds = self.language_model.get_input_embeddings()(input_ids)
# 把视觉 token 拼接到文本 token 前面,组成统一的多模态输入序列
inputs_embeds = torch.cat([image_features, text_embeds], dim=1)
# 为视觉 token 添加全 1 的 mask,保证不被屏蔽
image_attention = torch.ones(
image_features.shape[:2], device=attention_mask.device
)
attention_mask = torch.cat([image_attention, attention_mask], dim=1)
outputs = self.language_model(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
labels=labels,
)
return outputs
为什么"序列拼接"这种简单方式就能实现跨模态融合? 关键在于 Transformer 的自注意力机制天然允许序列中任意两个位置互相交互——视觉 token 和文本 token 被放在同一个序列中后,LLM 的每一层自注意力都在同时做"视觉内部交互""文本内部交互"和"跨模态交互",不需要额外设计专门的融合模块。换句话说,LLM 本身就是一个强大的融合器,只要视觉特征被正确投影到 LLM 的语义空间,自注意力就能自动完成跨模态信息整合。这种极简设计不仅训练高效,而且对下游任务的适配成本很低,这也是 Early Fusion 在 VLA 中占主导地位的根本原因。
2.1.3 训练流程
为什么要分两阶段,而不是直接端到端训练?
视觉 token 和语言 token 来自完全不同的编码空间——CLIP 输出的视觉特征对 LLM 来说是"外星语言",直接混合训练会让 LLM 难以收敛。因此必须分阶段解耦:Stage 1 单独训练投影层,强迫它把视觉特征映射到 LLM 能理解的语义空间,相当于先学"翻译";Stage 2 在投影层已经学会"翻译"的基础上,再让 LLM 整体适应视觉输入,学习视觉问答能力,相当于再练习"用外语对话"。这种渐进式训练既稳定收敛,又节省计算资源。
两阶段训练:
阶段 1:预训练(特征对齐)
├── 数据:图像-文本对(CC3M 等)
├── 冻结:Vision Encoder + LLM
├── 训练:只训练 Projector
└── 目标:让 LLM 看懂视觉 token
阶段 2:微调(指令跟随)
├── 数据:视觉指令数据(LLaVA-Instruct)
├── 冻结:Vision Encoder
├── 训练:Projector + LLM(全参数或 LoRA)
└── 目标:学会根据图像回答问题
# Stage 1:只训练 projector
for param in clip_model.parameters():
param.requires_grad = False
for param in llm.parameters():
param.requires_grad = False
# projector 参数默认 requires_grad = True
# Stage 2:训练 projector + LLM(可选用 LoRA)
for param in clip_model.parameters():
param.requires_grad = False
# LLM 用 LoRA 微调
llm = get_peft_model(llm, lora_config)
# projector 继续训练
2.1.4 视觉指令数据示例
{
"image": "image_001.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\n这张图片里有什么?"
},
{
"from": "gpt",
"value": "这张图片显示了一只橙色的猫正在阳光明媚的窗台上睡觉..."
},
{
"from": "human",
"value": "猫看起来多大了?"
},
{
"from": "gpt",
"value": "从图片来看,这只猫看起来是一只成年猫,大约 2-5 岁..."
}
]
}
2.2 视觉 Token 处理策略
视觉 token 数量是 VLM 工程化的核心问题。LLM 的自注意力计算复杂度是 O(n²),而视觉 token 通常占输入序列的 50%-80%——一张 224×224 的图像经 ViT 编码后产生 196 个 patch token,高分辨率图像切片后可达上千个。这意味着视觉 token 数量直接决定了推理延迟和显存占用。在机器人部署场景中,这个问题更加突出:10Hz 的控制频率意味着每步决策只有 100ms,留给模型推理的时间极其有限,因此压缩视觉 token 数量是 VLA 工程化的关键瓶颈。
2.2.1 直接投影(LLaVA)
图像 patch: [P1, P2, ..., P576] (24×24 patches)
↓ 投影
视觉 token: [V1, V2, ..., V576] (与文本 token 维度相同)
↓ 拼接
输入序列: [V1, V2, ..., V576, T1, T2, ..., Tn]
问题:视觉 token 数量多,占用大量上下文长度。
2.2.2 Perceiver Resampler(Flamingo)
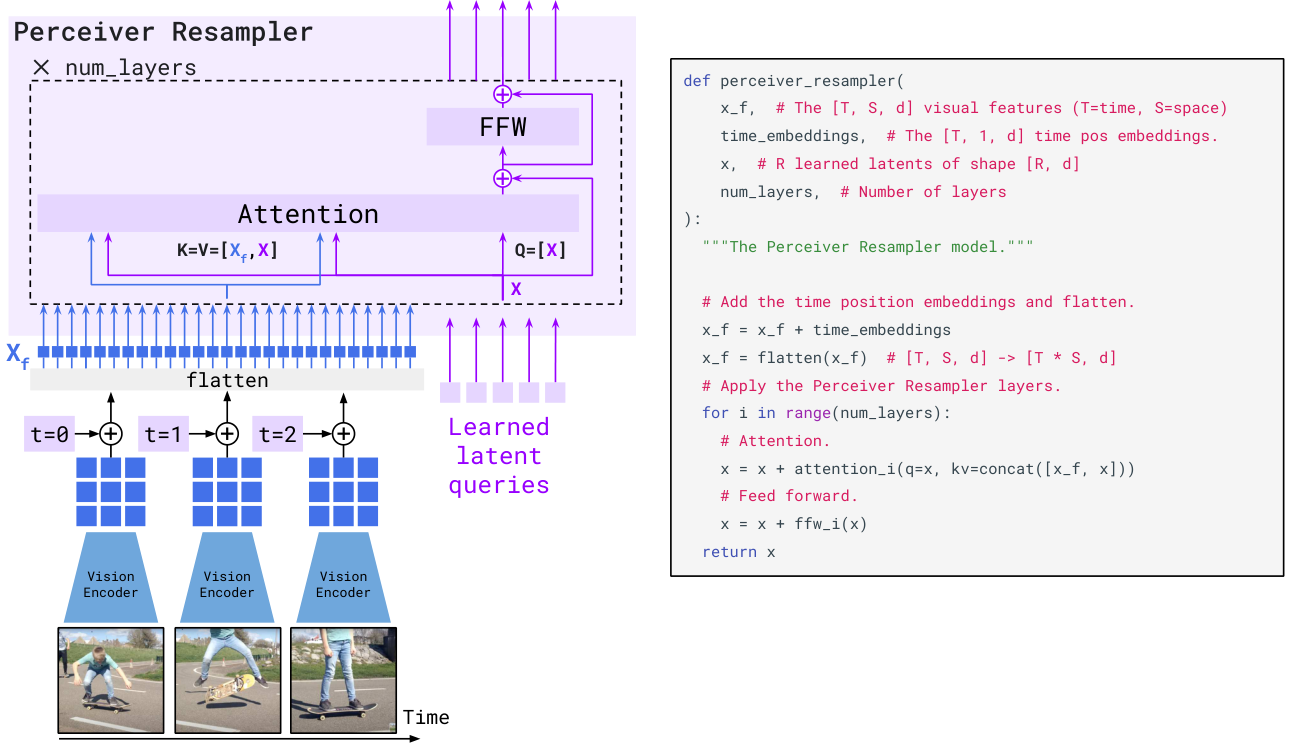
Perceiver Resampler 解决的核心问题不是“如何提取视觉特征”,而是“如何把可变长度视觉序列压到固定 token 预算”。在多帧输入场景下,视觉 token 会随帧数和分辨率线性增长,如果直接全部拼进 LLM,会迅速触发上下文长度和延迟瓶颈。
核心直觉:维护一组固定数量的可学习 latent queries(例如 64 个),让这些 query 反复通过交叉注意力从海量视觉 token 中“读取”信息。无论输入是 256 个还是 2000 个视觉 token,输出都固定为 R 个 token。
数据流(含 shape):
输入视觉特征: x_f ∈ R^(B, T, S, D) 或 R^(B, N_img, D)
T: 时间帧数,S: 每帧 patch 数,N_img = T×S
flatten 后: x_f ∈ R^(B, N_img, D)
可学习 query: q_0 ∈ R^(B, R, D) (R 为固定 query 数)
第 l 层:
q_l = q_(l-1) + CrossAttn(Q=q_(l-1), K=x_f, V=x_f)
q_l = q_l + FFN(q_l)
输出: q_L ∈ R^(B, R, D)
下面是一个可直接映射上述流程的最小实现:
class PerceiverResampler(nn.Module):
"""将可变数量视觉 token 压缩为固定数量 R"""
def __init__(
self,
dim=1024,
num_queries=64,
num_heads=16,
num_layers=6,
):
super().__init__()
# 固定数量的可学习 query,作为压缩后的视觉表示槽位
self.queries = nn.Parameter(torch.randn(num_queries, dim))
# 每层用交叉注意力让 query 从视觉 token 中读取信息
self.cross_attn = nn.ModuleList([
nn.MultiheadAttention(dim, num_heads, batch_first=True)
for _ in range(num_layers)
])
# 每层后接前馈网络,增强非线性表达
self.ffn = nn.ModuleList([
nn.Sequential(
nn.Linear(dim, 4 * dim),
nn.GELU(),
nn.Linear(4 * dim, dim),
)
for _ in range(num_layers)
])
self.norm1 = nn.ModuleList([nn.LayerNorm(dim) for _ in range(num_layers)])
self.norm2 = nn.ModuleList([nn.LayerNorm(dim) for _ in range(num_layers)])
def forward(self, visual_features):
# 支持 (B, T, S, D) 或 (B, N_img, D)
if visual_features.dim() == 4:
B, T, S, D = visual_features.shape
visual_features = visual_features.view(B, T * S, D)
B = visual_features.size(0)
queries = self.queries.unsqueeze(0).expand(B, -1, -1)
for i in range(len(self.cross_attn)):
# query 作为 Q,视觉 token 作为 K/V,读取关键信息
q = self.norm1[i](queries)
attn_out, _ = self.cross_attn[i](q, visual_features, visual_features)
# 残差连接:注意力更新 + FFN 更新
queries = queries + attn_out
queries = queries + self.ffn[i](self.norm2[i](queries))
return queries
2.2.3 Q-Former(BLIP-2)
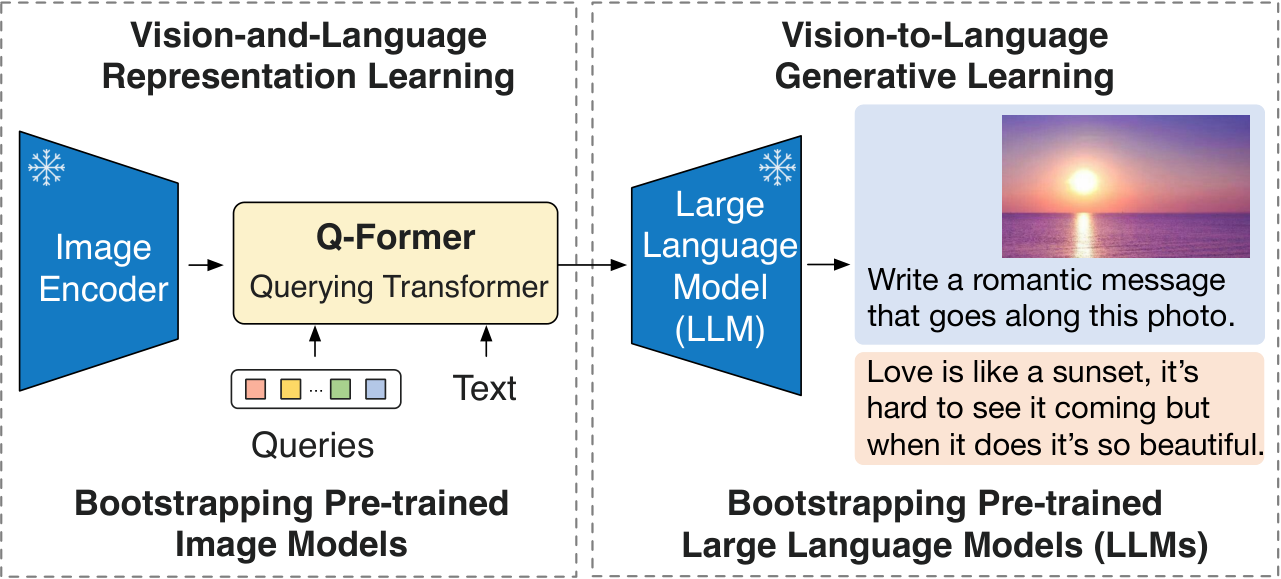
Q-Former 的核心思路是:用固定数量(如 32 个)的可学习 Query token,通过交叉注意力机制从视觉编码器输出的大量 patch token 中"提问"并提取最相关的信息。每个 Query 先在自身之间做自注意力交互,再通过交叉注意力从视觉特征中读取信息,经过多层迭代后,这些 Query 就浓缩了图像的关键语义。这种设计将视觉 token 数从数百个压缩到几十个,大幅降低了送入 LLM 的序列长度。详细的 Q-Former 实现见 Section 3.10.2。
为避免和 Perceiver Resampler 混淆,可用下表快速区分:
| 方法 | 查询来源 | 交互方式 | 输出 token 数 | 典型优势 |
|---|---|---|---|---|
| Perceiver Resampler | learned latents(固定 R) | query 直接读视觉特征,可叠层 | 固定 R(如 64) | 结构简洁,易做固定预算压缩 |
| Q-Former | learned queries(固定 Q) | Query 自注意力 + 跨注意力 | 固定 Q(如 32) | 查询内部建模更强,语义提炼更细 |
2.3 高分辨率图像处理
2.3.1 问题
标准 ViT 输入分辨率固定,例如 224×224。高分辨率图像如果直接缩放,会丢失细节。
2.3.2 解决方案
高分辨率处理的目标是同时满足两件事:
- 保留细节;2) 控制 token 预算。
主流做法通常是图像切片或多尺度融合,前者强调局部细节覆盖,后者强调粗细粒度互补。
2.3.2.1 图像切片(LLaVA-NeXT)
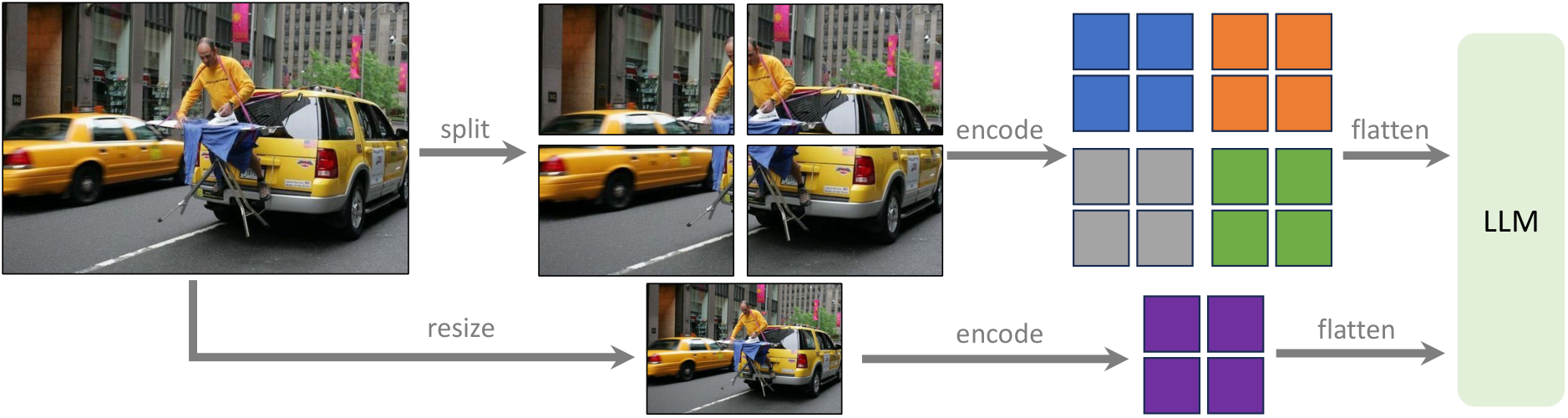
图像切片的本质是把“单张高分辨率输入”变成“多个标准分辨率子图输入”,这样不改 ViT 结构也能读取局部细节。
但如果只看局部 patch,会丢失全局语义,所以实践中常额外加入一张缩略图(thumbnail)作为全局上下文。
def dynamic_preprocess(image, max_num=6, image_size=336):
"""将高分辨率图像切成多个子图"""
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# 候选网格比例:按原图宽高比选择最匹配的切分方式
target_ratios = [(1, 1), (1, 2), (2, 1), (2, 2), (1, 3), (3, 1)]
best_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios)
patches = []
# 按选中的网格切图,并统一缩放到视觉编码器输入尺寸
for i in range(best_ratio[0]):
for j in range(best_ratio[1]):
patch = crop_and_resize(image, i, j, image_size)
patches.append(patch)
# 额外保留一张全局缩略图,补充整体语义
thumbnail = resize(image, image_size)
patches.append(thumbnail)
return patches
2.3.2.2 多尺度特征(InternVL)
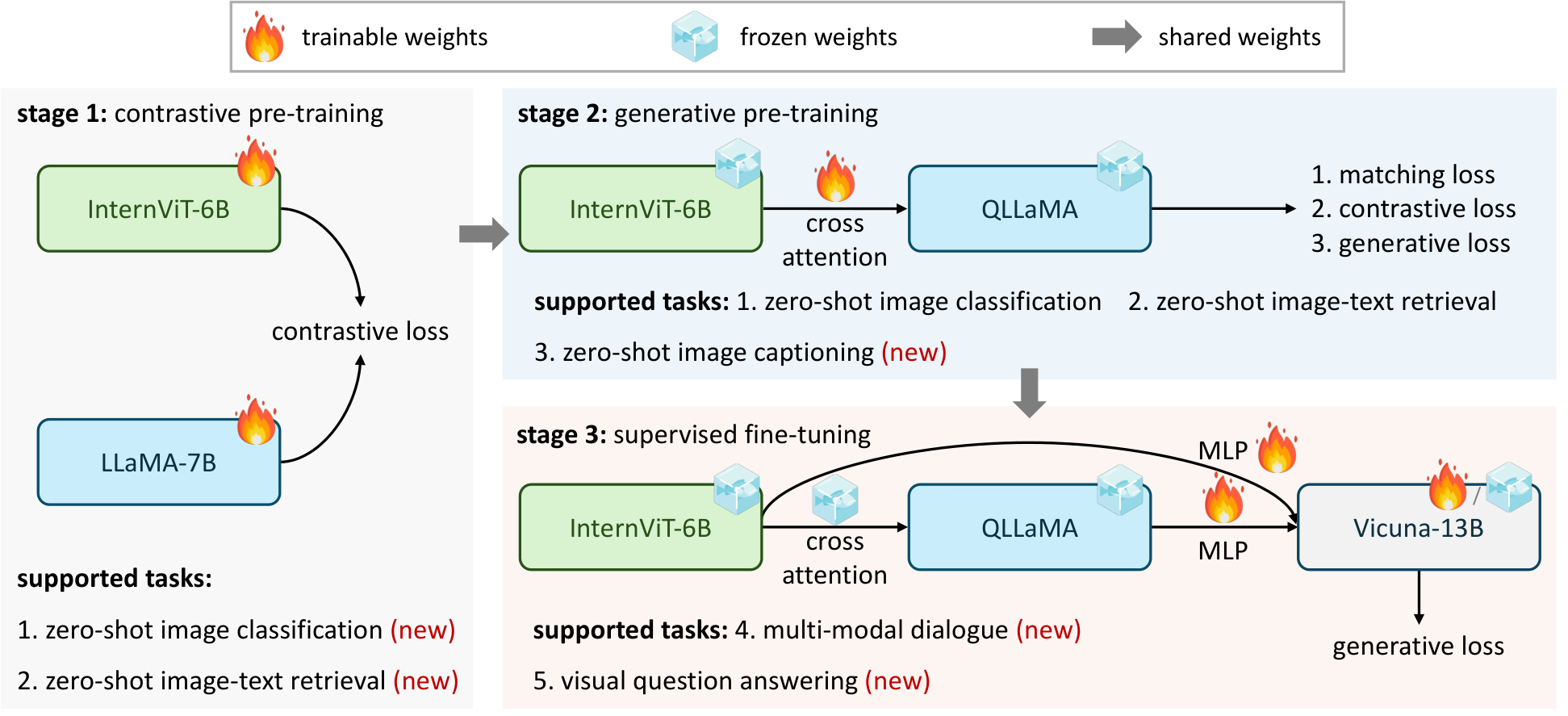
上图主要展示 InternVL 的训练流程(分阶段对齐与生成)。在推理阶段,多尺度特征方法关心的是:同一张图在不同分辨率下提取特征,再融合成统一视觉表示。两者关系是:训练阶段学会跨尺度对齐,推理阶段利用这种对齐能力做稳健融合。
高分辨率图像 (448×448)
│
├────────────────┐
│ │
下采样到 224 原始 448
│ │
ViT 编码 ViT 编码
│ │
粗粒度特征 细粒度特征
│ │
└───── 融合 ─────┘
│
多尺度视觉 token
Qwen-VL 等模型也采用了类似的位置感知适配器设计来处理高分辨率输入。
2.4 训练数据与策略
2.4.1 预训练数据
| 数据集 | 规模 | 类型 |
|---|---|---|
| LAION-5B | 50 亿对 | 图文对 |
| COYO-700M | 7 亿对 | 图文对 |
| CC3M/CC12M | 300 万/1200 万 | 图文对 |
| WebLI | 100 亿对 | 多语言图文 |
2.4.2 指令微调数据
| 数据集 | 规模 | 特点 |
|---|---|---|
| LLaVA-Instruct | 158K | GPT-4 生成 |
| ShareGPT4V | 1.2M | 高质量描述 |
| ALLaVA | 715K | 多样化任务 |
两阶段训练的数据选择逻辑与训练目标紧密对应:Stage 1(预训练对齐)使用大规模、弱标注的图文对数据(如 CC3M、LAION 子集),目的是让投影层在海量样本中学会将视觉特征映射到 LLM 的语义空间,此阶段数据量大但质量要求不高。Stage 2(指令微调)则切换到小规模、高质量的视觉指令数据(如 LLaVA-Instruct),这些数据通常由 GPT-4 生成或人工标注,包含多轮对话和复杂推理,目的是让模型学会根据视觉内容进行精确的问答和推理。数据质量在 Stage 2 远比数据量重要。
完整的多模态模型代码示例见 Section 4.3。
3. 跨模态对齐与融合方法
用一个直觉类比来理解跨模态对齐的本质:视觉编码器和 LLM 各自在不同的"语言"中描述世界——CLIP 用视觉向量说"这是一只猫",LLaMA 用文本向量说"cat",两者说的是同一件事,但彼此听不懂。对齐就是学习一个"翻译器"(投影层),把视觉编码器的"语言"翻译成 LLM 能理解的"语言"。但这个翻译不只是简单的维度变换,还需要让翻译后的视觉特征落在 LLM 文本嵌入的分布范围内——如果投影后的向量在数值范围或方向上偏离 LLM 的正常输入分布,LLM 会把这些视觉 token 当作"乱码"忽略,导致视觉信息完全失效。
3.1 跨模态对齐是什么?
核心问题:视觉特征和文本特征来自不同的预训练模型,它们的语义空间不一致。
CLIP 视觉特征:
"猫"的图像 → 视觉向量 v_cat
LLaMA 文本特征:
"cat" → 文本向量 t_cat
问题:v_cat 和 t_cat 在不同的向量空间中!
- 维度不同(1024 vs 4096)
- 语义方向不同
- 直接拼接 LLM 无法理解
3.2 对齐的层次
Level 1: 维度对齐
- 通过投影层将视觉维度映射到 LLM 维度
- 最基础的对齐
Level 2: 分布对齐
- 让投影后的视觉特征分布接近 LLM 文本嵌入的分布
- 通过对比学习或匹配损失实现
Level 3: 语义对齐
- 让“猫的图像”特征接近“cat”的文本特征
- 需要图文对数据训练
3.3 对齐方法一:对比学习(CLIP 风格)
如果视觉编码器本身就是 CLIP,它已经和文本对齐了。但 CLIP 的文本编码器和 LLM 不同,所以仍需要进一步对齐。
对比学习对齐的原理已在第 4 章(CLIP)中详细介绍。在 VLM 的预训练阶段,投影层通过类似的对比损失学习将视觉特征映射到 LLM 可理解的语义空间。
3.4 对齐方法二:重建损失
重建损失的思路更直接:给定图像的视觉特征,让 LLM 自回归地生成对应的文本描述,用标准的语言建模损失(cross-entropy)来训练投影层。这种方式不需要显式的对比样本对,而是通过”看图说话”的任务隐式地迫使投影层输出 LLM 能理解的视觉表示。LLaVA 的 Stage 1 预训练本质上就是这种重建损失驱动的对齐。
3.5 CLIP 视觉特征可以迁移到 LLM 的原因
关键洞察:虽然 CLIP 文本编码器不是 LLM,但它们都在海量文本上训练过,因此语义结构并不完全陌生。
CLIP 视觉特征的性质:
- 已经包含了丰富的语义信息(“这是一只猫”)
- 特征空间有语义结构(相似概念距离近)
投影层的作用:
- 学习从 CLIP 语义空间到 LLM 语义空间的映射
- 这个映射相对简单,因为两者都有类似的语义结构
类比:
- CLIP 空间 ≈ 中文描述
- LLM 空间 ≈ 英文描述
- 投影层 ≈ 翻译器
3.6 融合策略总览
┌─────────────────────────────────────────────────────────────────────┐
│ 融合策略对比 │
├─────────────────┬──────────────────────┬────────────────────────────┤
│ Early Fusion │ Late Fusion │ Cross-Attention │
│ (早期融合) │ (晚期融合) │ (交叉注意力) │
├─────────────────┼──────────────────────┼────────────────────────────┤
│ │ │ │
│ Image Text │ Image Text │ Image Text │
│ ↓ ↓ │ ↓ ↓ │ ↓ ↓ │
│ [concat] │ Encoder Encoder │ Encoder Encoder │
│ ↓ │ ↓ ↓ │ ↓ ↓ │
│ Encoder │ [concat/merge] │ └──Cross-Attn──┘ │
│ ↓ │ ↓ │ ↓ │
│ Output │ Output │ Output │
├─────────────────┼──────────────────────┼────────────────────────────┤
│ LLaVA, OpenVLA │ 少数方法 │ Flamingo, BLIP-2 │
└─────────────────┴──────────────────────┴────────────────────────────┘
三种融合方式的本质区别不只是结构不同,而是"视觉信息在什么时机、以什么粒度参与语言建模"的根本差异。Early Fusion 将视觉 token 直接拼入输入序列,视觉信息从 LLM 的第一层就参与自注意力计算,交互最充分,但视觉 token 数量不可压缩,序列长度直接受限于 patch 数。Cross-Attention 将视觉特征作为外部记忆,在 LLM 的每一层都可以通过交叉注意力查询,视觉信息不占用主干序列长度,但需要额外的注意力层。Q-Former 则先用可学习 Query 将视觉信息压缩到少量 token 中再注入 LLM,牺牲部分空间细节换取显著的效率提升。理解这三者的本质差异,是根据具体任务场景做出正确选型的前提。
3.7 Early Fusion(早期融合)
核心思想:在输入层将视觉和文本 token 拼接,然后一起送入 LLM。
class EarlyFusion(nn.Module):
"""早期融合:在输入层拼接"""
def __init__(self, vision_encoder, projector, llm):
super().__init__()
# 视觉编码器:提取 patch 级视觉特征
self.vision_encoder = vision_encoder
# 投影层:把视觉维度映射到 LLM 维度
self.projector = projector
# 语言模型主干:处理拼接后的多模态序列
self.llm = llm
def forward(self, images, text_embeds):
# 视觉编码并去掉 CLS token,保留 patch token
image_features = self.vision_encoder(images).last_hidden_state[:, 1:, :]
# 视觉特征映射到与文本 embedding 相同维度
image_embeds = self.projector(image_features)
# Early Fusion:在 token 维拼接视觉和文本
combined = torch.cat([image_embeds, text_embeds], dim=1)
# 将融合后的序列送入 LLM
outputs = self.llm(inputs_embeds=combined)
return outputs
优点:简单直接,复用 LLM 的自注意力,让视觉和文本充分交互,训练效率高。
缺点:视觉 token 数量多时,序列较长,计算量随 token 数二次增长。
3.8 Late Fusion(晚期融合)
核心思想:视觉和文本分别编码到最后,再合并。视觉编码器和文本编码器各自独立处理输入,最终通过一个融合层(如拼接、加权求和或浅层注意力)将两路特征合并后输出。
特点:交互较少、实现简单,但在 VLM/VLA 中不常用。
3.9 Cross-Attention(交叉注意力)
核心思想:在 LLM 的特定层插入交叉注意力,让文本关注视觉特征。
class CrossAttentionLayer(nn.Module):
"""交叉注意力层:文本 attend 到图像"""
def __init__(self, d_model, n_heads):
super().__init__()
# Q 来自文本,K/V 来自图像特征
self.cross_attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
# 对注意力输出做归一化,稳定训练
self.norm = nn.LayerNorm(d_model)
# 可学习门控,控制视觉信息注入强度
self.gate = nn.Parameter(torch.zeros(1))
def forward(self, text_hidden, image_features):
attn_output, _ = self.cross_attn(
query=text_hidden,
key=image_features,
value=image_features,
)
# 残差注入:文本主干 + 门控后的视觉增量
output = text_hidden + torch.tanh(self.gate) * self.norm(attn_output)
return output
class FlamingoStyleLLM(nn.Module):
"""Flamingo 风格:在 LLM 层间插入交叉注意力"""
def __init__(self, llm, cross_attn_layers, insert_every=4):
super().__init__()
# 原始 LLM 层
self.llm = llm
# 预先构建的 cross-attn 层列表
self.cross_attn_layers = nn.ModuleList(cross_attn_layers)
# 每隔多少层插入一次 cross-attn
self.insert_every = insert_every
def forward(self, text_embeds, image_features):
hidden = text_embeds
cross_attn_idx = 0
for i, layer in enumerate(self.llm.layers):
# 先走标准 LLM 层
hidden = layer(hidden)
if (i + 1) % self.insert_every == 0:
# 周期性注入视觉信息
hidden = self.cross_attn_layers[cross_attn_idx](hidden, image_features)
cross_attn_idx += 1
return hidden
优点:视觉信息不占用序列长度,生成时可以灵活关注视觉信息,适合多图像输入。
缺点:需要修改 LLM 架构,训练更复杂。
3.10 Adapter 与 Q-Former
3.10.1 Adapter:轻量级适配
Adapter 采用经典的 bottleneck 结构:先通过一个降维线性层将特征压缩到低维空间,经过非线性激活后再通过升维线性层恢复原始维度,最后加上残差连接。这种设计参数量极少(通常只有原模型的 1%-5%),可以在冻结主干模型的同时高效地适配新任务或新模态。
3.10.2 Q-Former:压缩视觉 token
这部分拆成两个小模块:Q-Former 主体 和 单层 Block,更容易看清数据流。
class QFormer(nn.Module):
"""输入很多视觉 token,输出少量 query token"""
def __init__(self, num_query_tokens=32, vision_dim=1024, hidden_dim=768, num_layers=6):
super().__init__()
# 可学习 query:固定长度的视觉摘要槽位
self.query_tokens = nn.Parameter(torch.zeros(1, num_query_tokens, hidden_dim))
nn.init.normal_(self.query_tokens, std=0.02)
# 堆叠多个 Q-Former block 逐步提炼视觉信息
self.layers = nn.ModuleList([QFormerBlock(hidden_dim, vision_dim) for _ in range(num_layers)])
self.norm = nn.LayerNorm(hidden_dim)
def forward(self, image_features):
# image_features: (B, N_img, D_v)
B = image_features.size(0)
# 把同一组 query 扩展到 batch 维
queries = self.query_tokens.expand(B, -1, -1)
for blk in self.layers:
# 每层先 query 内部交互,再读取图像特征
queries = blk(queries, image_features)
# 输出固定数量的压缩视觉 token
return self.norm(queries)
class QFormerBlock(nn.Module):
"""单层结构:Query 先自注意力,再跨注意力读取图像信息"""
def __init__(self, hidden_dim, vision_dim, num_heads=12):
super().__init__()
# Query 内部建模(token-token 交互)
self.self_attn = nn.MultiheadAttention(hidden_dim, num_heads, batch_first=True)
# Query 从视觉 token 中读取信息
self.cross_attn = nn.MultiheadAttention(
hidden_dim, num_heads, kdim=vision_dim, vdim=vision_dim, batch_first=True
)
# 前馈网络,增强非线性表达
self.ffn = nn.Sequential(
nn.Linear(hidden_dim, 4 * hidden_dim), nn.GELU(), nn.Linear(4 * hidden_dim, hidden_dim)
)
self.n1 = nn.LayerNorm(hidden_dim)
self.n2 = nn.LayerNorm(hidden_dim)
self.n3 = nn.LayerNorm(hidden_dim)
def forward(self, q, img):
# Pre-Norm + 残差:先在 query 内部聚合
q = q + self.self_attn(self.n1(q), self.n1(q), self.n1(q))[0]
# Pre-Norm + 残差:再从图像特征中读取关键信息
q = q + self.cross_attn(self.n2(q), img, img)[0]
# 前馈层更新
q = q + self.ffn(self.n3(q))
return q
Q-Former 的优势:输入 256 个视觉 patch token,输出 32 个压缩后的视觉 token,压缩比大,适合减少送入 LLM 的 token 数量。
3.10.3 VLA 中的 Adapter 使用
Prismatic VLM 的投影层本质上与 LLaVA 的两层 MLP Projector 相同(Linear → GELU → Linear),具体实现可参考 Section 2.1.2 中的 mm_projector。
3.11 融合方式选择指南
三种主流融合范式各有适用场景,选型时需要在结构复杂度、推理速度、对齐质量之间做出权衡:
Linear Projector(如 LLaVA) 结构最简单,仅用两层 MLP 将视觉特征线性映射到 LLM 维度,训练效率高,工程实现成本低。适合大规模预训练、或对推理速度和部署成本要求较高的场景。缺点是视觉 token 数量固定(与 patch 数一一对应),无法动态压缩,当图像分辨率高时上下文会很长。
Cross-Attention(如 Flamingo) 视觉 token 不插入主干序列,而是通过交叉注意力层注入 LLM 各层,视觉信息在整个生成过程中持续影响每一层的文本表示。适合视觉信息非常丰富、需要细粒度图文交互的场景(如多图像、视频理解)。缺点是需要修改 LLM 原始架构,引入额外的注意力层,训练和推理计算量更高。
Q-Former(如 BLIP-2) 用固定数量的可学习 Query token 通过交叉注意力从视觉特征中提取最相关信息,大幅压缩视觉 token 数(例如从 256 个 patch 压缩到 32 个 Query 输出)。适合视觉 token 过多、显存或延迟受限的场景。缺点是固定数量的 Query 可能丢失部分空间细节,对需要精确定位的任务不友好。
VLA 工程实践建议:视觉 token 数直接决定推理速度和显存占用,在机器人部署场景中实时性至关重要。推荐优先选择 Projector 方案(结构简单、易于调试)或 Q-Former 风格的压缩方案(大幅减少 token 数);Cross-Attention 方案计算开销较大,不适合资源受限的机载推理场景。
4. 面向 VLA 的多图像与工程实践
从 VLM 到 VLA,融合层面的变化远不止"加一个动作输出头"。首先,输入从单帧静态图像变成了时序多帧(通常 2-6 帧),视觉 token 数量成倍增长,对注意力计算和显存的压力急剧上升。其次,输出从自由形式的文本变成了需要精确数值的动作量(如关节角度、末端位移),对融合后特征的信息保留能力要求更高——文本生成容忍一定的模糊性,但动作预测中 1mm 的偏差就可能导致抓取失败。这意味着 VLA 的融合模块必须在"高效压缩"和"精确保留"之间找到更好的平衡。
4.1 VLA 的数据流与核心地位
摄像头图像 自然语言指令
│ │
▼ ▼
┌─────────────┐ ┌───────────┐
│ 视觉编码器 │ │ Tokenizer │
│ (CLIP/SigLIP)│ │ │
└─────────────┘ └───────────┘
│ │
▼ ▼
视觉特征 文本 Token
(B, N_img, D_v) (B, N_txt)
│ │
├────────────────────────────┤
│ ↓ 多模态融合 │ ← 本节的核心内容
│ ┌─────────────────────┐ │
│ │ 融合后的序列 │ │
│ │ [IMG] [IMG]...[TXT] │ │
│ └─────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────┐ │
│ │ LLM │ │
│ └───────────────┘ │
│ │ │
│ ▼ │
│ 动作预测输出 │
└────────────────────────────┘
多模态融合要解决的核心问题:
- 维度对齐:视觉特征维度(如 1024)与 LLM 嵌入维度(如 4096)不同。
- 语义对齐:让 LLM 真正“理解”视觉特征的含义。
- 位置融合:如何将视觉 token 和文本 token 组合成可训练序列。
4.2 多图像输入:时序视觉
4.2.1 多图像输入的必要性
单图像输入:
只能看到当前时刻的场景
无法感知运动、变化
多图像输入(时序):
可以看到过去几帧
感知物体运动方向和速度
更好地预测动作
4.2.2 多图像处理方式
4.2.2.1 帧拼接(Frame Concatenation)
帧拼接的思路最直接:每帧独立编码,再把所有帧的视觉 token 串成一个长序列。
优点是实现简单、与单帧模型兼容;缺点是 token 数会随帧数线性增长。
# 帧拼接核心逻辑:每帧独立编码后串接为一个长序列
images_flat = images.view(B * T, C, H, W) # 多帧展平为 batch
features = vision_encoder(images_flat)[:, 1:, :] # 每帧独立编码,去 CLS
features = projector(features) # 投影到 LLM 维度
features = features.view(B, T * N, D) # 串接:2 帧 × 256 patch = 512 个视觉 token
shape 追踪:
- 输入:
images为(B, T, C, H, W)。 - 编码前展平:
(B*T, C, H, W),复用单帧视觉编码器。 - 投影后重排:
(B, T*N, D),作为统一视觉前缀拼接到文本前。
4.2.2.2 时序编码(Temporal Encoding)
时序编码是在帧拼接基础上的增强:不仅给模型“看多帧”,还显式告诉模型“这是第几帧”。
如果不加时序编码,多帧 token 在自注意力中可能被当作无序集合。
# 时序编码核心逻辑:在帧拼接基础上,为每帧加上可学习的时序位置编码
temporal_embed = nn.Parameter(torch.zeros(1, max_frames, 1, D)) # 每帧一个时序向量
all_features = []
for t in range(T):
features = projector(vision_encoder(images[:, t])[:, 1:, :]) # 单帧编码 + 投影
features = features + temporal_embed[:, t, :, :] # 加时序位置编码,区分帧顺序
all_features.append(features)
combined = torch.cat(all_features, dim=1) # 串接所有帧的 token
shape 追踪:
- 第
t帧特征:(B, N, D)。 - 时序编码:
temporal_embed[:, t]广播后仍为(B, N, D)。 - 最终拼接:
combined为(B, T*N, D)。
常见坑:
max_frames < T时会索引越界,训练前需统一帧数策略。- 时序编码只加在训练,推理忘记加,导致时序建模失效。
4.2.3 VLA 中的典型配置
| 模型 | 输入帧数 | 处理方式 |
|---|---|---|
| RT-2 | 1-6 帧 | 帧拼接 |
| OpenVLA | 1 帧 | 单帧(简化) |
| Octo | 2 帧 | 带时序编码 |
| pi0 | 1+ 帧 | 动态帧数 |
4.3 完整 VLA 多模态融合示例
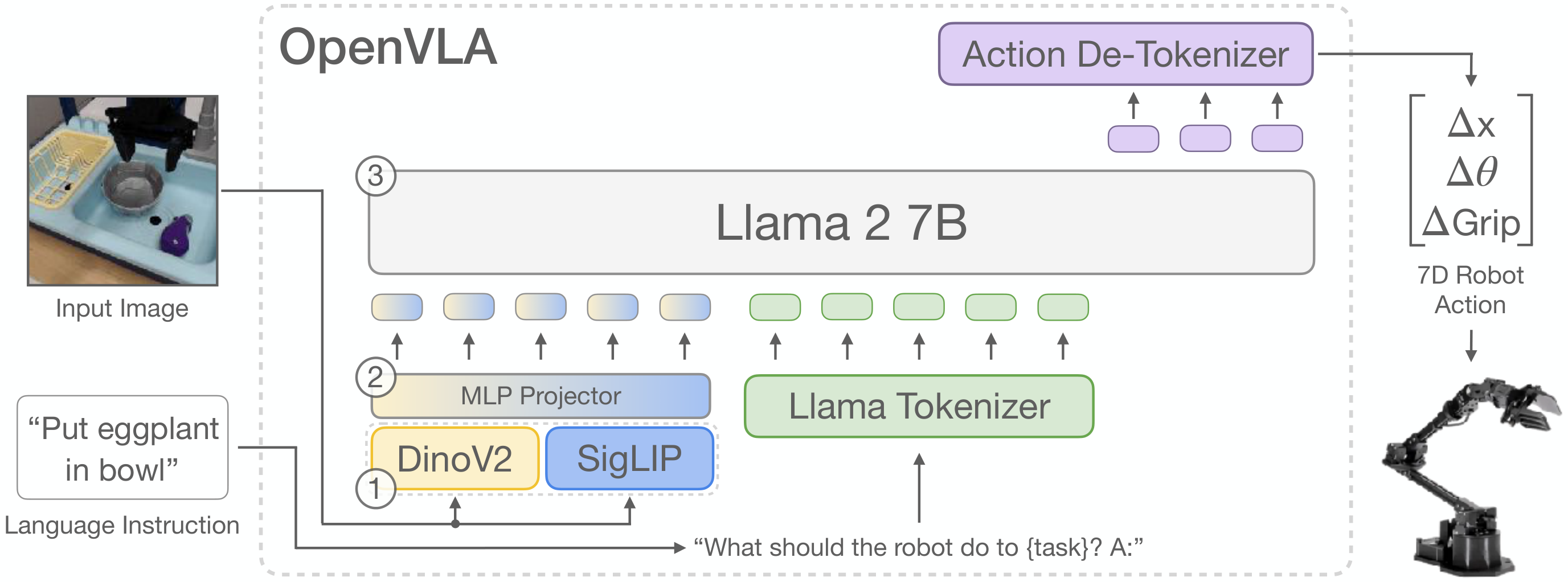
原始代码实现很完整,但篇幅较大。这里保留最核心的数据流,拆成 3 个子模块。先给出整体接口:
- 输入:图像(单帧或多帧)+ 文本指令 token。
- 中间表示:融合后的多模态 embedding 序列。
- 输出:动作 token(再反量化为连续动作)。
子模块 A:视觉编码 + 投影(支持单帧/多帧)
class VLAEncoder(nn.Module):
def __init__(self, vision_encoder, projector):
super().__init__()
# 视觉主干:提取图像 patch 特征
self.vision_encoder = vision_encoder
# 投影层:对齐到 LLM hidden size
self.projector = projector
@torch.no_grad()
def forward(self, images):
# 单帧: (B, C, H, W);多帧: (B, T, C, H, W)
is_multi_frame = images.dim() == 5
if is_multi_frame:
B, T, C, H, W = images.shape
# 多帧展平为 batch,复用单帧视觉编码路径
images = images.view(B * T, C, H, W)
# 取 patch token(去 CLS)并映射到 LLM 维度
feats = self.vision_encoder(images).last_hidden_state[:, 1:, :] # 去 CLS
feats = self.projector(feats)
if not is_multi_frame: # 单帧路径
return feats
# 多帧路径:将每帧 token 串接为一个长序列
return feats.view(B, -1, feats.size(-1))
子模块 A 的职责:
- 输入:
images为(B,C,H,W)或(B,T,C,H,W)。 - 输出:视觉 token
(B,N_img,D)。 - 作用:统一单帧/多帧路径,向后续融合模块提供标准化视觉前缀。
子模块 B:动作离散化(连续动作与 token 互转)
def actions_to_bins(actions, num_bins, action_min=-1.0, action_max=1.0):
# 连续动作先裁剪到有效范围,再量化到离散 bin
x = actions.clamp(action_min, action_max)
x = (x - action_min) / (action_max - action_min)
return (x * (num_bins - 1)).long()
def bins_to_actions(bins, num_bins, action_min=-1.0, action_max=1.0):
# 离散 bin 反量化回连续动作区间
x = bins.float() / (num_bins - 1)
return x * (action_max - action_min) + action_min
子模块 B 的职责:
- 训练期:把连续动作监督信号映射为离散 token 标签。
- 推理期:把模型生成的离散 token 还原为控制器可执行的连续动作。
- 注意:离散化会引入量化误差,
num_bins越大误差越小但词表开销越高。
子模块 C:训练与推理主流程(VLA 最关键)
def vla_forward(llm, encoder, images, input_ids, attention_mask, labels=None):
# 视觉前缀:编码图像得到视觉 token
image_embeds = encoder(images) # (B, N_img, D)
# 文本前缀:查表得到文本 embedding
text_embeds = llm.get_input_embeddings()(input_ids) # (B, N_txt, D)
# Early Fusion:拼接成统一输入序列
inputs_embeds = torch.cat([image_embeds, text_embeds], dim=1)
# 图像 token 的 mask / label 需要同步扩展
img_mask = torch.ones(image_embeds.shape[:2], device=attention_mask.device, dtype=attention_mask.dtype)
full_mask = torch.cat([img_mask, attention_mask], dim=1)
full_labels = None
if labels is not None:
ignore = torch.full(image_embeds.shape[:2], -100, device=labels.device, dtype=labels.dtype)
full_labels = torch.cat([ignore, labels], dim=1)
return llm(inputs_embeds=inputs_embeds, attention_mask=full_mask, labels=full_labels)
@torch.no_grad()
def predict_action_tokens(llm, prefix_embeds, action_token_ids, action_dim):
# 自回归生成动作 token(只保留动作词表上的 logits)
# 把动作 token 列表转成张量,便于 batch 索引
action_vocab = torch.as_tensor(action_token_ids, device=prefix_embeds.device, dtype=torch.long)
generated, past = [], None
next_embed = prefix_embeds
for _ in range(action_dim):
# use_cache=True: 复用历史 KV,加速自回归生成
out = llm(inputs_embeds=next_embed, past_key_values=past, use_cache=True)
past = out.past_key_values
# 仅在动作词表子空间上做 argmax 选 token
logits = out.logits[:, -1, :][:, action_vocab]
idx = logits.argmax(dim=-1) # (B,)
token_ids = action_vocab[idx] # (B,)
generated.append(token_ids)
# 把新 token 映射成 embedding,作为下一步输入
next_embed = llm.get_input_embeddings()(token_ids[:, None])
return torch.stack(generated, dim=1) # (B, action_dim)
子模块 C 的职责:
vla_forward:构建训练用多模态序列,保证 mask/labels 与拼接后的 token 完全对齐。predict_action_tokens:在推理阶段自回归生成动作 token 序列。
训练路径(简化):
encoder(images)得到视觉 token(B,N_img,D)。- 与文本 embedding 拼接成
(B,N_img+N_txt,D)。 - 扩展
attention_mask;图像位置labels=-100,只监督文本/动作 token。 - 计算语言建模损失并反传。
推理路径(简化):
- 准备好视觉+指令前缀 embedding。
- 循环生成
action_dim个动作 token。 - 用
bins_to_actions反量化成连续控制量。
常见坑:
attention_mask与拼接序列长度不一致,直接导致训练异常。- 忘记把图像 token 对应标签设为
-100,损失会污染。 - 动作离散化区间与控制器真实范围不一致,推理动作会系统性偏移。
- 多帧输入时
N_img激增,需配合 token 压缩或降采样策略。
说明:真实工程还会包含 tokenizer 特殊 token 注册、LoRA、KV Cache、批处理采样等,这里省略以突出 VLA 融合主线。
4.4 工程实现中的注意点
- 输入序列长度:多图像输入会快速拉长上下文,训练和推理都要控制 token 数。
- attention mask:图像 token 和文本 token 的 mask 要同步扩展。
- 标签对齐:图像 token 对应的标签通常设为
-100,避免参与损失。 - 动作输出:VLA 常把连续动作离散化为 token,以复用 LLM 的生成能力。
5. 本章总结与实践建议
5.1 核心知识速查
| 概念 | 一句话总结 |
|---|---|
| 投影层(Projector) | 将视觉特征维度映射到 LLM 维度,两层 MLP 通常比单层更强 |
| Early Fusion | 在输入层拼接视觉和文本 token,是 LLaVA/VLA 的主流方案 |
| Cross-Attention | 在 LLM 层间插入交叉注意力,Flamingo 风格 |
| Q-Former | 用可学习 Query 压缩视觉 token 数量,BLIP-2 |
| 跨模态对齐 | 让视觉特征能被 LLM 理解,通过预训练和对齐损失实现 |
| 多图像输入 | VLA 中用于时序建模,帧拼接或加入时序编码 |
5.2 VLA 中的最佳实践
1. 视觉编码器:SigLIP 或 CLIP,通常冻结参数
2. 投影层:两层 MLP,可训练
3. 融合方式:Early Fusion(token 拼接)
4. LLM 微调:LoRA,高效且稳定
5. 动作输出:离散化为 token,复用 LLM 预测能力
5.3 学习路线建议
1. 先理解 LLaVA 的架构和训练流程
→ 看懂投影层如何连接 CLIP 和 LLaMA
2. 跑一个 LLaVA 的推理示例
→ 感受多模态模型的输入输出
3. 阅读 Early Fusion 的代码实现
→ 理解如何将视觉 token 插入文本序列
4. 对比不同融合策略
→ 理解 Cross-Attention 和 Q-Former 的优缺点
5. 阅读 OpenVLA 的多模态融合代码
→ 理解 VLA 中如何处理动作输出
本章核心:把视觉特征"接入"LLM 有三种主流范式——Linear Projector(直接映射,简单高效)、Cross-Attention(层间注入,持续交互)、Q-Former(可学习查询压缩,大幅减少 token 数),三者在结构复杂度、推理速度和对齐质量上各有权衡。
融合不只是技术问题,也是工程权衡:视觉 token 数、计算量、对齐质量三者相互制约,没有放之四海的最优解,需要根据任务场景和部署约束做出选择。
引出下一章:融合之后,LLM 已经能"看懂"图像了。但 VLA 的目标不是描述图像,而是执行动作——第 6 章(从 VLM 到 VLA)将讲解 VLM 如何进一步演化为 VLA,把语言理解能力转化为机器人的动作决策。
6. 参考资料
- CLIP: Learning Transferable Visual Models
- LLaVA: Visual Instruction Tuning
- Improved Baselines with Visual Instruction Tuning
- Flamingo: a Visual Language Model for Few-Shot Learning
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- Qwen-VL: A Versatile Vision-Language Model
- Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
- OpenVLA: An Open-Source Vision-Language-Action Model
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- LLaVA GitHub
- HuggingFace Transformers 多模态文档
- LLaVA-NeXT