1. Transformer 基础
本章目标:理解 Transformer 的核心机制,从"为什么需要它"出发,逐步构建完整的架构认知。
1. 为什么需要 Transformer?
在学习 Transformer 之前,先看两个具身智能中的典型场景:
- 看图问答:机器人摄像头拍到一张桌面图片,需要理解"杯子在哪里"
- 抓杯子:机器人需要把图像信息、语言指令、历史动作融合,输出下一步的关节角度
这两个任务都需要一种能力:在大量信息中,快速找到"哪些部分和当前问题最相关"。这正是 Transformer 解决的核心问题。
1.1 RNN/LSTM 的两个核心问题
在 Transformer 出现之前,序列建模依赖 RNN/LSTM。它们通过隐状态逐步传递信息,存在两个根本性缺陷:
- 长程依赖退化:距离越远的 token 之间梯度越难传递,信息在长序列中逐渐"遗忘"
- 无法并行:必须按时间步顺序计算,无法利用现代 GPU 的并行能力
1.2 注意力机制的核心思想
注意力机制的解法直接而优雅:让每个位置都能直接"看到"序列中的所有其他位置,并根据相关性加权聚合信息。
不再需要信息"一步步传递"——任意两个位置之间都有直接连接,梯度可以直接流动,计算也可以并行。
2. 注意力机制
2.1 先看整体:注意力在 Transformer Block 中的位置
在深入公式之前,先明确你现在学的是哪个部分:
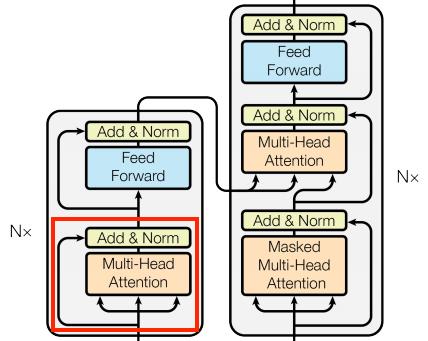
注意力层负责跨位置的信息聚合,FFN 负责每个位置的特征变换。两者缺一不可。
2.2 Scaled Dot-Product Attention
2.2.1 核心公式
其中:
:Query 矩阵(当前位置"想要什么") :Key 矩阵(每个位置"我有什么") :Value 矩阵(每个位置"我实际提供的内容") :Key 的维度(用于缩放)
2.2.2 逐步推导(4步)
Step 1:计算相关性得分(Attention Score)
矩阵形式:
Step 2:缩放(Scaling)
为什么要除以
大方差 → softmax 输入过大 → softmax 梯度趋近于 0("软"变"硬",梯度消失)。除以
Step 3:Softmax 归一化
每一行得到一个概率分布,表示第
Step 4:加权聚合 Value
2.2.3 直觉类比:图书馆检索
| 概念 | 类比 |
|---|---|
| Query (Q) | 你的检索关键词 |
| Key (K) | 书目索引标签 |
| Value (V) | 书的实际内容 |
| Attention Weight | 每本书与你需求的匹配程度 |
| Output | 根据匹配程度加权的知识摘要 |
2.2.4 计算复杂度
| 操作 | 复杂度 |
|---|---|
| Softmax | |
| 总计 |
这是 Transformer 的核心瓶颈:序列长度
2.2.5 PyTorch 实现
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(
Q: torch.Tensor, # (batch, seq_q, d_k)
K: torch.Tensor, # (batch, seq_k, d_k)
V: torch.Tensor, # (batch, seq_k, d_v)
mask: torch.Tensor = None # (batch, seq_q, seq_k) or broadcastable
) -> tuple[torch.Tensor, torch.Tensor]:
"""
Returns:
output: (batch, seq_q, d_v)
attn_weights: (batch, seq_q, seq_k)
"""
d_k = Q.size(-1)
# Step 1 & 2: 计算缩放后的相关性得分
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
# scores: (batch, seq_q, seq_k)
# Step 3: 应用掩码(可选,用于 Causal Attention)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# Step 4: Softmax 归一化
attn_weights = F.softmax(scores, dim=-1)
# Step 5: 加权聚合 Value
output = torch.matmul(attn_weights, V)
return output, attn_weights
# 示例
batch, seq_len, d_k, d_v = 2, 10, 64, 64
Q = torch.randn(batch, seq_len, d_k)
K = torch.randn(batch, seq_len, d_k)
V = torch.randn(batch, seq_len, d_v)
output, weights = scaled_dot_product_attention(Q, K, V)
print(f"Output shape: {output.shape}") # (2, 10, 64)
print(f"Weights shape: {weights.shape}") # (2, 10, 10)
2.2.6 数值稳定性
Softmax 计算时,为防止 exp 溢出,实际实现中会先减去最大值:
PyTorch 的 F.softmax 已内置此优化。
2.3 Multi-Head Attention
单头注意力解决了信息聚合问题,但还不够——同一个 token 与其他 token 之间可能存在多种不同类型的关系,单头只能学到一种视角。
2.3.1 单头的局限
单头注意力在每个位置只能学习一种注意力模式。但实际语言/视觉信号中,同一个 token 可能同时存在:
- 句法关系(主语 ↔ 谓语)
- 语义关系(同义词共现)
- 局部关系(相邻词)
- 长程依赖(代词 ↔ 先行词)
2.3.2 核心公式
其中每个头:
参数维度:
, ,
通常令
2.3.3 计算流程
输入 X: (batch, seq_len, d_model)
↓ 分别投影到 h 个子空间
Q_i = X @ W_i^Q → (batch, seq_len, d_k)
K_i = X @ W_i^K → (batch, seq_len, d_k)
V_i = X @ W_i^V → (batch, seq_len, d_v)
↓ 每头独立计算注意力
head_i = Attention(Q_i, K_i, V_i) → (batch, seq_len, d_v)
↓ 拼接所有头
Concat([head_1, ..., head_h]) → (batch, seq_len, h*d_v = d_model)
↓ 输出投影
Output = Concat(...) @ W^O → (batch, seq_len, d_model)
2.3.4 直觉理解
以
- 第 1 头:可能学习局部窗口内的注意力(相邻词)
- 第 2 头:可能学习句法依存关系
- 第 3 头:可能学习长程语义关联
- ...
类比:如同用多个不同滤镜同时观察同一张图片,然后综合所有视角得出判断。
2.3.5 参数量分析
设
| 参数 | 数量 |
|---|---|
| 总计 |
与单头注意力参数量相同,但表达能力更强。
2.3.6 PyTorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.0):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每头维度
# 合并所有头的投影为一个大矩阵(更高效)
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
def split_heads(self, x: torch.Tensor) -> torch.Tensor:
"""(batch, seq, d_model) → (batch, heads, seq, d_k)"""
batch, seq, _ = x.shape
# 将 d_model 维拆分为 (num_heads, d_k),使每个头独立处理一份子空间
x = x.view(batch, seq, self.num_heads, self.d_k)
# transpose:将 heads 维提前,方便后续对每个头独立做矩阵乘法
return x.transpose(1, 2) # (batch, heads, seq, d_k)
def forward(
self,
query: torch.Tensor, # (batch, seq_q, d_model)
key: torch.Tensor, # (batch, seq_k, d_model)
value: torch.Tensor, # (batch, seq_k, d_model)
mask: torch.Tensor = None # (batch, 1, seq_q, seq_k) 或可广播形状
) -> torch.Tensor:
# 1. 线性投影 + 分头
Q = self.split_heads(self.W_q(query)) # (batch, h, seq_q, d_k)
K = self.split_heads(self.W_k(key)) # (batch, h, seq_k, d_k)
V = self.split_heads(self.W_v(value)) # (batch, h, seq_k, d_k)
# 2. Scaled Dot-Product Attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# scores: (batch, h, seq_q, seq_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 3. 加权聚合
context = torch.matmul(attn_weights, V) # (batch, h, seq_q, d_k)
# 4. 合并多头
batch, _, seq_q, _ = context.shape
context = context.transpose(1, 2).contiguous() # (batch, seq_q, h, d_k)
context = context.view(batch, seq_q, self.d_model) # (batch, seq_q, d_model)
# 5. 输出投影
output = self.W_o(context) # (batch, seq_q, d_model)
return output
# 示例
mha = MultiHeadAttention(d_model=512, num_heads=8)
x = torch.randn(2, 10, 512) # (batch=2, seq=10, d_model=512)
output = mha(x, x, x) # Self-Attention
print(output.shape) # torch.Size([2, 10, 512])
PyTorch 也提供了高度优化的内置实现:
# PyTorch 内置 MHA
mha = nn.MultiheadAttention(
embed_dim=512,
num_heads=8,
dropout=0.1,
batch_first=True # (batch, seq, embed) 格式
)
x = torch.randn(2, 10, 512)
output, attn_weights = mha(x, x, x) # Self-Attention
注意力机制解决了信息聚合的问题,但模型还需要几个关键组件才能真正工作——注意力本身是排列不变的,不知道 token 的先后顺序;而且它只做加权求和,缺少逐位置的非线性变换能力。位置编码、FFN、归一化等组件正是为了补齐这些短板。
3. 让 Transformer 能工作的组件
3.1 位置编码
注意力机制本身是**排列不变(permutation-invariant)**的:打乱输入序列的顺序,注意力的计算结果是相同的。但语言和视觉信号中,顺序信息至关重要("猫追狗"和"狗追猫"含义完全不同)。因此需要显式地将位置信息注入模型。
3.1.1 Sinusoidal PE(原始 Transformer 方案)
Vaswani et al. 提出用正弦/余弦函数生成位置编码,不需要学习:
其中
直觉:每个维度对应不同频率的正弦波,低维高频(相邻位置差异大),高维低频(捕捉长程位置差异)。
维度 0 (高频): ▲▼▲▼▲▼▲▼▲▼▲▼▲▼▲▼ ← 位置
维度 2: ▲▲▼▼▲▲▼▼▲▲▼▼▲▲▼▼
维度 50: ▲▲▲▲▲▲▲▲▼▼▼▼▼▼▼▼
维度 510 (低频):▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲ ← 变化极慢
import torch
import torch.nn as nn
import math
class SinusoidalPositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 预计算位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float() # (max_len, 1)
# 计算分母:10000^(2i/d_model)
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
) # (d_model/2,)
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维:sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维:cos
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe) # 不参与梯度更新
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""x: (batch, seq_len, d_model)"""
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
3.1.2 Learned PE(可学习位置编码)
BERT、GPT 等模型改用可学习的位置嵌入:为每个位置分配一个 nn.Embedding 向量,与 token 嵌入相加后送入模型。这些位置向量在训练中通过反向传播自动学习,无需手工设计频率。缺点是位置数量在初始化时固定(如 BERT 的 512),超过 max_len 的序列无法处理,外推能力较差。
3.1.3 RoPE(旋转位置编码)
RoPE(Rotary Position Embedding,Su et al., 2021)是目前主流 LLM 的标准选择(LLaMA、Qwen、Mistral 等)。
核心思想:在计算 Attention 之前,对 Q 和 K 中的向量旋转,旋转角度取决于位置。这样 Q 和 K 的点积自然包含了相对位置信息:
即 Q 在位置
对于
def rotate_half(x: torch.Tensor) -> torch.Tensor:
"""将向量的后半部分取反,实现旋转。
RoPE 将 d_k 维向量拆为前后两半:
前半为 x1,后半为 x2
rotate_half 输出 [-x2, x1],与原向量做线性组合即可模拟复数旋转:
x_rotated = x * cos + rotate_half(x) * sin
"""
x1 = x[..., : x.shape[-1] // 2] # 前半部分
x2 = x[..., x.shape[-1] // 2 :] # 后半部分
return torch.cat([-x2, x1], dim=-1)
def apply_rotary_pos_emb(
q: torch.Tensor, # (batch, heads, seq, d_k)
k: torch.Tensor,
cos: torch.Tensor, # (seq, d_k),预计算的 cos(m*theta_i)
sin: torch.Tensor # (seq, d_k),预计算的 sin(m*theta_i)
) -> tuple[torch.Tensor, torch.Tensor]:
cos = cos.unsqueeze(0).unsqueeze(0) # (1, 1, seq, d_k)
sin = sin.unsqueeze(0).unsqueeze(0)
# 旋转变换:q_rotated = q * cos + rotate_half(q) * sin
q_embed = q * cos + rotate_half(q) * sin
k_embed = k * cos + rotate_half(k) * sin
return q_embed, k_embed
class RoPE(nn.Module):
def __init__(self, dim: int, max_seq_len: int = 4096, base: float = 10000.0):
super().__init__()
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer('inv_freq', inv_freq)
self._build_cache(max_seq_len)
def _build_cache(self, seq_len: int):
t = torch.arange(seq_len, device=self.inv_freq.device).float()
freqs = torch.outer(t, self.inv_freq) # (seq, dim/2)
emb = torch.cat([freqs, freqs], dim=-1) # (seq, dim)
self.register_buffer('cos_cached', emb.cos())
self.register_buffer('sin_cached', emb.sin())
def forward(self, q, k, seq_len: int):
cos = self.cos_cached[:seq_len]
sin = self.sin_cached[:seq_len]
return apply_rotary_pos_emb(q, k, cos, sin)
3.1.4 ALiBi
ALiBi(Press et al., 2021)不修改 token 嵌入,而是直接在 Attention Score 上加一个与相对距离成正比的负偏置:
其中
每个头的斜率
即
3.1.5 各方案对比
| 方案 | 参数量 | 相对位置 | 外推能力 | 代表模型 |
|---|---|---|---|---|
| Sinusoidal PE | 0 | 隐式 | 有限 | 原始 Transformer |
| Learned PE | 无 | 差(截断) | BERT, GPT-2 | |
| RoPE | 0 | 显式 | 好(可调) | LLaMA, Qwen, Mistral |
| ALiBi | 0 | 显式 | 好 | BLOOM |
| T5 相对 PE | 显式 | 较好 | T5 |
3.2 前馈网络(FFN)
位置编码解决了"模型不知道顺序"的问题,但注意力层只做信息路由——每个位置还需要独立的非线性变换来处理聚合后的信息,这就是 FFN 的职责。
3.2.1 基本形式
- 输入/输出维度:
(如 512) - 中间层维度:
(通常 ,如 2048) - "Position-wise":对序列中每个位置独立、相同地应用
3.2.2 为什么需要 FFN?
注意力机制负责信息聚合(不同位置之间的交互),FFN 负责特征变换(在每个位置上做非线性变换)。
两者协作:注意力 = 路由(什么信息到哪里),FFN = 处理(如何变换信息)。
研究表明 FFN 层可以看作键值记忆存储(Geva et al., 2021),低层存储语法信息,高层存储语义/事实知识。
FFN 的参数量通常占 Transformer 参数总量的约 2/3(另 1/3 是注意力层)。
3.2.3 GELU 与 SwiGLU 变体
原始 Transformer 用 ReLU,现代 LLM 改用更好的激活函数:
GELU(BERT、GPT 系列使用):
比 ReLU 更平滑(无硬截断)。
SwiGLU(LLaMA、PaLM、Qwen 等现代模型使用):
其中
import torch
import torch.nn as nn
import torch.nn.functional as F
class FFN(nn.Module):
"""标准 FFN(ReLU/GELU)"""
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1, activation='gelu'):
super().__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.act = nn.GELU() if activation == 'gelu' else nn.ReLU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.fc2(self.dropout(self.act(self.fc1(x))))
class SwiGLU(nn.Module):
"""SwiGLU FFN(LLaMA 风格)"""
def __init__(self, d_model: int, d_ff: int = None):
super().__init__()
if d_ff is None:
d_ff = int(8 / 3 * d_model) # 近似 2.67x
d_ff = (d_ff + 63) // 64 * 64 # 对齐到 64 的倍数(GPU 效率)
self.gate = nn.Linear(d_model, d_ff, bias=False)
self.up = nn.Linear(d_model, d_ff, bias=False)
self.down = nn.Linear(d_ff, d_model, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Swish(gate) ⊙ up,再投影回 d_model
return self.down(F.silu(self.gate(x)) * self.up(x))
3.3 LayerNorm 与残差连接
FFN 提供了非线性变换能力,但深层网络的训练稳定性还需要 LayerNorm 和残差连接来保障。
3.3.1 LayerNorm 公式
其中
3.3.2 与 BatchNorm 对比
| 特性 | LayerNorm | BatchNorm |
|---|---|---|
| 归一化维度 | 特征维度(每个 token 独立) | batch 维度(跨样本) |
| 序列长度变化 | 不受影响 | 受影响 |
| batch size=1 | 正常工作 | 统计不稳定 |
| Transformer 适用性 | 是 | 差 |
3.3.3 RMSNorm
LLaMA 等现代模型用 RMSNorm,去掉了均值减法(只做 RMS 缩放):
计算更快,实验效果相当甚至更好。
class RMSNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model))
def forward(self, x: torch.Tensor) -> torch.Tensor:
rms = x.pow(2).mean(dim=-1, keepdim=True).add(self.eps).sqrt()
return x / rms * self.weight
3.3.4 残差连接的作用
- 梯度直通:梯度可以通过加法直接流回浅层,缓解梯度消失
- 恒等映射的可学习性:子层只需要学习"残差"(输入的增量)
- 深层网络稳定训练:ResNet 引入后,超深网络成为可能
3.3.5 Post-Norm vs Pre-Norm
Post-Norm(原始 Transformer):
Pre-Norm(现代 LLM 常用):
| 特性 | Post-Norm | Pre-Norm |
|---|---|---|
| 训练稳定性 | 较差(需要 warmup) | 较好 |
| 梯度流 | 较难 | 更顺畅 |
| 现代使用 | BERT, 原始 Transformer | LLaMA, GPT-3, Qwen |
有了注意力机制、位置编码、FFN 和归一化这四个组件,我们就可以组装出完整的 Transformer 架构了。每个组件各司其职:注意力做跨位置的信息路由,位置编码提供顺序感知,FFN 做逐位置的非线性变换,归一化和残差连接保障深层网络的训练稳定性。接下来看它们如何拼装在一起。
4. 完整 Transformer 架构
4.1 三种架构形式
原始 Transformer(Vaswani et al., 2017)由 Encoder 和 Decoder 两部分组成。后续演化出三种主要形式:
Encoder-Decoder(原始 Transformer)
适用:机器翻译、摘要生成、问答
代表:T5、BART、mBART
特点:源序列和目标序列分开处理,Cross-Attention 传递信息
Encoder-Only(BERT 系)
适用:文本分类、命名实体识别、句子嵌入
代表:BERT、RoBERTa、ALBERT、DeBERTa
特点:
- 双向自注意力(无 Causal Mask)
- 训练目标:MLM(完形填空)+ NSP
- 输出是每个 token 的表示,不直接生成文本
Decoder-Only(GPT 系)
适用:文本生成、Few-shot 学习、指令跟随
代表:GPT-2/3/4、LLaMA、Mistral、Qwen、Claude
特点:
- 因果自注意力(Causal Self-Attention)
- 训练目标:CLM(下一个 token 预测)
- 无需 Encoder,单一前向传播完成生成
- 目前最主流的 LLM 架构
完整架构图(Encoder-Decoder):
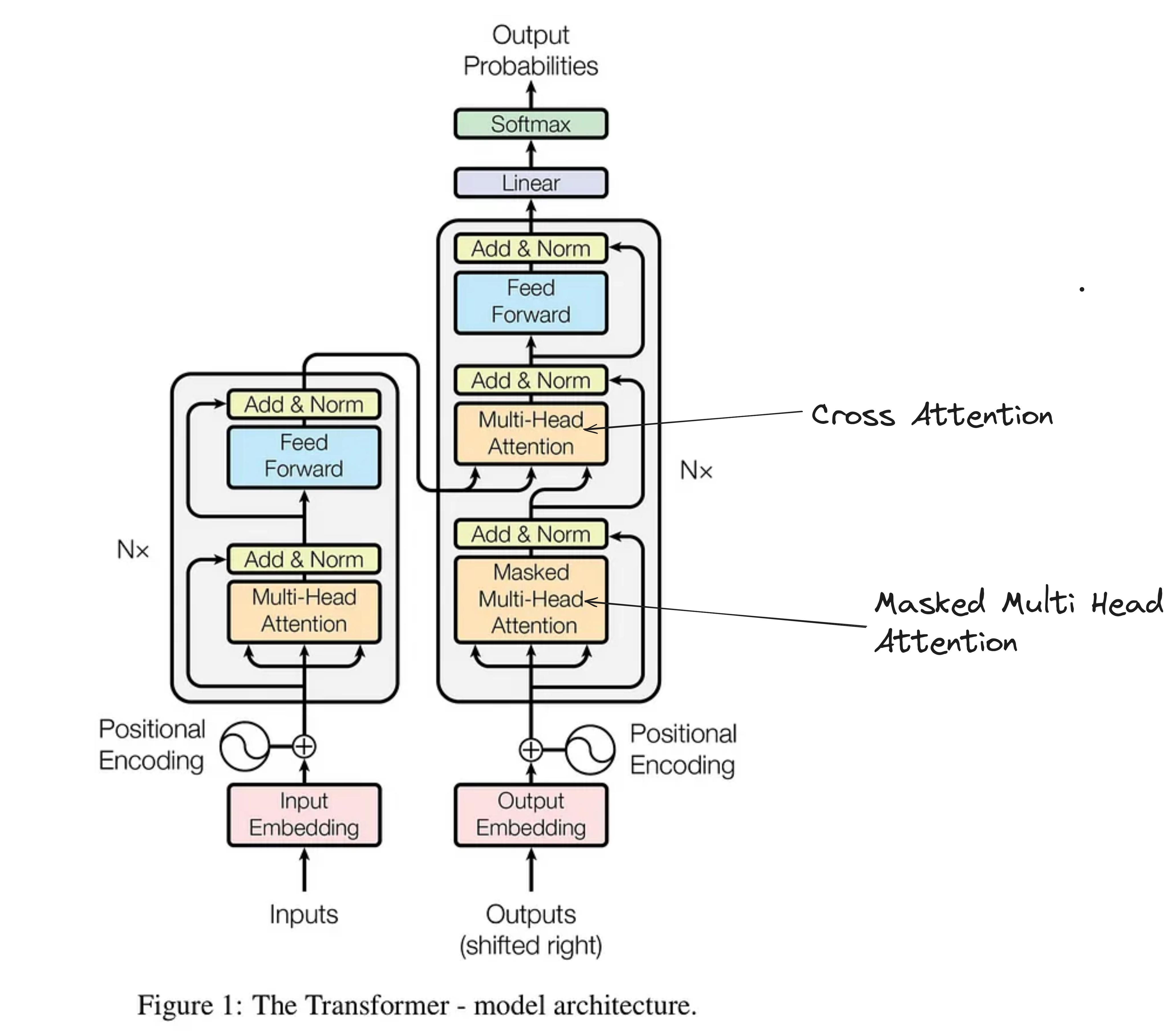
4.2 注意力变体:Self / Causal / Cross
三种架构形式对应三种注意力变体,理解它们的区别是理解整个架构的关键。
4.2.1 三种变体概览
| 变体 | Q 来源 | K/V 来源 | 掩码 | 典型应用 |
|---|---|---|---|---|
| Self-Attention | 同一序列 | 同一序列 | 无 | Encoder、ViT |
| Causal Self-Attention | 同一序列 | 同一序列(仅过去) | 因果掩码(下三角) | GPT、LLM Decoder |
| Cross-Attention | 序列 A | 序列 B | 通常无 | Encoder-Decoder(翻译、T5) |
4.2.2 Self-Attention(自注意力)
Q、K、V 均来自同一个序列 X,每个位置可以看到序列中的所有位置:
位置: 1 2 3 4
↓ ↓ ↓ ↓
[A] [B] [C] [D] ← 作为 Query
↑ ↑ ↑ ↑
[A] [B] [C] [D] ← 作为 Key/Value(每个 Query 都能看到所有位置)
def self_attention(X, W_q, W_k, W_v):
Q = X @ W_q # (batch, seq, d_k)
K = X @ W_k
V = X @ W_v
return scaled_dot_product_attention(Q, K, V)
4.2.3 Causal Self-Attention(因果注意力)
与 Self-Attention 相同,但通过因果掩码限制每个位置只能看到它自己和之前的位置。
为什么需要因果掩码?在自回归训练时,如果位置
直觉例子:预测"我爱___"时,如果模型能偷看后面的"机器学习",它就不需要真正理解语言,只需要复制答案。Causal Mask 就是把"未来的词"遮住。
构造下三角矩阵作为掩码(1 表示可见,0 表示屏蔽):
seq_len = 4:
pos1 pos2 pos3 pos4 ← Key 位置
pos1 [ 1 0 0 0 ]
pos2 [ 1 1 0 0 ]
pos3 [ 1 1 1 0 ]
pos4 [ 1 1 1 1 ]
↑ Query 位置
import torch
def make_causal_mask(seq_len: int) -> torch.Tensor:
"""生成下三角因果掩码,True 表示可以看到"""
mask = torch.tril(torch.ones(seq_len, seq_len, dtype=torch.bool))
return mask
def causal_self_attention(X, W_q, W_k, W_v):
seq_len = X.size(1)
mask = make_causal_mask(seq_len).to(X.device)
Q = X @ W_q
K = X @ W_k
V = X @ W_v
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
scores = scores.masked_fill(~mask.unsqueeze(0), float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
return torch.matmul(attn_weights, V)
因果约束后的注意力矩阵:
A B C D ← Key
A [1.0, 0.0, 0.0, 0.0] ← A 只看自己
B [0.4, 0.6, 0.0, 0.0] ← B 看 A 和自己
C [0.3, 0.3, 0.4, 0.0] ← C 看 A, B, 自己
D [0.2, 0.3, 0.2, 0.3] ← D 看所有
↑ Query
4.2.4 Cross-Attention(交叉注意力)
Q 来自序列 A(目标序列,如 Decoder),K 和 V 来自序列 B(源序列,如 Encoder 输出):
典型应用:机器翻译(解码器 Query 编码器输出)、图像描述生成(文本 Query 图像特征)、Diffusion 模型(图像 Feature Query 文本 Embedding)。
Encoder 输出(中文):
[我] [爱] [机器] [学习] ← 作为 Key/Value
Decoder 位置(英文):
[I] → Query → 关注源序列哪些位置?
[love] → Query → 关注源序列哪些位置?
[ML] → Query → 关注源序列哪些位置?
class CrossAttentionBlock(nn.Module):
def __init__(self, d_model: int, num_heads: int):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.norm = nn.LayerNorm(d_model)
def forward(
self,
target: torch.Tensor, # Decoder 序列 (batch, tgt_len, d_model)
source: torch.Tensor, # Encoder 输出 (batch, src_len, d_model)
src_mask: torch.Tensor = None
) -> torch.Tensor:
# Q 来自 target,K/V 来自 source
attn_output = self.mha(
query=target,
key=source,
value=source,
mask=src_mask
)
return self.norm(target + attn_output)
4.2.5 Padding Mask 与 Causal Mask 的组合
实际训练中,通常需要同时处理 Padding Mask 和 Causal Mask:
def make_combined_mask(
padding_mask: torch.Tensor, # (batch, seq_len),1 为有效 token,0 为 padding
seq_len: int
) -> torch.Tensor:
"""
结合 Padding Mask 和 Causal Mask
Returns: (batch, 1, seq_len, seq_len)
"""
# Causal Mask: (1, 1, seq_len, seq_len)
causal = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).unsqueeze(0)
# Padding Mask: (batch, 1, 1, seq_len) - 屏蔽 padding 的 Key 位置
pad = padding_mask.unsqueeze(1).unsqueeze(2).float()
# 两者取交集(AND)
combined = causal * pad
return combined # (batch, 1, seq_len, seq_len)
4.3 完整实现
import torch
import torch.nn as nn
from typing import Optional
class EncoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FFN(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, mask: Optional[torch.Tensor] = None):
# Pre-Norm 形式(现代常用)
attn_out = self.self_attn(self.norm1(x), self.norm1(x), self.norm1(x), mask)
x = x + self.dropout(attn_out)
ffn_out = self.ffn(self.norm2(x))
x = x + self.dropout(ffn_out)
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FFN(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(
self,
x: torch.Tensor,
encoder_output: torch.Tensor,
src_mask: Optional[torch.Tensor] = None,
tgt_mask: Optional[torch.Tensor] = None
):
# 1. Causal Self-Attention(目标序列内部)
attn_out = self.self_attn(
self.norm1(x), self.norm1(x), self.norm1(x), tgt_mask
)
x = x + self.dropout(attn_out)
# 2. Cross-Attention(目标 Query,源 K/V)
cross_out = self.cross_attn(
self.norm2(x), encoder_output, encoder_output, src_mask
)
x = x + self.dropout(cross_out)
# 3. FFN
ffn_out = self.ffn(self.norm3(x))
x = x + self.dropout(ffn_out)
return x
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size: int,
tgt_vocab_size: int,
d_model: int = 512,
num_heads: int = 8,
num_encoder_layers: int = 6,
num_decoder_layers: int = 6,
d_ff: int = 2048,
dropout: float = 0.1
):
super().__init__()
self.src_embed = nn.Embedding(src_vocab_size, d_model)
self.tgt_embed = nn.Embedding(tgt_vocab_size, d_model)
self.pos_enc = SinusoidalPositionalEncoding(d_model, dropout)
self.encoder = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_encoder_layers)
])
self.decoder = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_decoder_layers)
])
self.final_norm = nn.LayerNorm(d_model)
self.output_proj = nn.Linear(d_model, tgt_vocab_size)
def encode(self, src, src_mask=None):
"""将源序列编码为上下文表示。
src: (batch, src_len) 源端 token ID
返回: (batch, src_len, d_model) 经所有 Encoder 层处理后的隐状态
"""
x = self.pos_enc(self.src_embed(src)) # token 嵌入 + 位置编码
for layer in self.encoder:
x = layer(x, src_mask) # 逐层做 Self-Attention + FFN
return self.final_norm(x)
def decode(self, tgt, encoder_output, src_mask=None, tgt_mask=None):
"""以 Encoder 输出为条件,对目标序列做自回归解码。
tgt: (batch, tgt_len) 目标端 token ID(训练时为 teacher forcing 输入)
encoder_output: encode() 的返回值,作为 Cross-Attention 的 K/V 源
返回: (batch, tgt_len, d_model)
"""
x = self.pos_enc(self.tgt_embed(tgt)) # 目标端嵌入 + 位置编码
for layer in self.decoder:
# 每个 DecoderLayer 依次做:Causal Self-Attn → Cross-Attn → FFN
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.final_norm(x)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
"""完整前向传播:encode → decode → 输出词汇表 logits"""
encoder_output = self.encode(src, src_mask)
decoder_output = self.decode(tgt, encoder_output, src_mask, tgt_mask)
return self.output_proj(decoder_output) # (batch, tgt_len, tgt_vocab_size)
4.4 参数量估算
以
| 组件 | 参数量 |
|---|---|
| MHA(4 个投影矩阵) | |
| FFN(2 个线性层) | |
| LayerNorm(×2) | |
| 单层合计 | |
| Encoder 6 层 | |
| Decoder 6 层(+Cross-Attn) | |
| Embedding |
完整架构搭好了,接下来看如何训练它——以及训练时有哪些关键技巧。架构设计决定了模型"能表达什么",而训练策略决定了模型"能学到什么":损失函数定义优化目标,学习率调度控制收敛路径,梯度裁剪和混合精度则保障大规模训练的稳定性与效率。
5. 训练与优化
5.1 CLM vs MLM 训练目标
因果语言模型(CLM):给定前缀,预测下一个 token(自回归)
使用 Causal Mask,代表模型:GPT 系列、LLaMA、Qwen。擅长文本生成、补全。
掩码语言模型(MLM):预测被随机遮蔽的 token(完形填空)
使用双向注意力,代表模型:BERT、RoBERTa。擅长理解任务(分类、NER、QA)。
5.2 BERT 掩码策略(80/10/10)
BERT 在训练时,对随机选取的 15% token 做以下处理:
| 操作 | 比例 | 说明 |
|---|---|---|
替换为 [MASK] | 80% | 标准遮蔽 |
| 替换为随机 token | 10% | 防止模型只关注 [MASK] |
| 保持原 token 不变 | 10% | 提供"实际值"监督 |
为什么不 100% 替换为 [MASK]?推理时没有 [MASK],模型如果只在有 [MASK] 时才做预测,会产生训练-推理不一致(train-inference mismatch)。
实现上,先随机选出 15% 的非特殊 token 位置,然后按 80/10/10 比例分别替换为 [MASK]、随机 token 或保持不变。未被选中的位置在 label 中标记为 -100,CrossEntropyLoss 会自动忽略这些位置。
5.3 损失函数
import torch.nn as nn
criterion = nn.CrossEntropyLoss(ignore_index=-100)
def clm_loss(logits: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
"""
logits: (batch, seq_len, vocab_size)
targets: (batch, seq_len),自回归:targets[t] = input[t+1]
"""
# shift: 用 [0, T-1] 的 logits 预测 [1, T] 的 token
shift_logits = logits[:, :-1, :].contiguous() # (batch, seq-1, vocab)
shift_labels = targets[:, 1:].contiguous() # (batch, seq-1)
return criterion(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1)
)
5.4 学习率调度(Warmup + Cosine Decay)
现代 LLM 普遍采用 Warmup + Cosine Decay 策略:先线性增大学习率完成预热,再按余弦曲线平滑衰减。
import math
def cosine_schedule_with_warmup(
step: int,
max_lr: float,
min_lr: float,
warmup_steps: int,
total_steps: int
) -> float:
"""现代 LLM 常用的余弦退火 + warmup"""
if step < warmup_steps:
return max_lr * step / warmup_steps # 线性 warmup
progress = (step - warmup_steps) / (total_steps - warmup_steps)
return min_lr + 0.5 * (max_lr - min_lr) * (1 + math.cos(math.pi * progress))
为什么需要 Warmup?训练初期参数随机,梯度很大且方向不稳定,直接用大学习率容易发散。Warmup 让模型先用小学习率做初始探索。
5.5 梯度裁剪、混合精度、梯度累积
这三种技术解决的是训练流程中三个不同层面的问题:梯度裁剪防止爆炸,混合精度节省显存并提速,梯度累积模拟大 batch。它们并不互斥,而是相互配合——在现代大模型训练中,三者几乎总是同时启用,共同构成标准训练工具链。
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
accumulation_steps = 8 # 等效 batch size = batch_size * 8
for i, batch in enumerate(dataloader):
# --- 混合精度:autocast 内用 fp16 前向,节省显存并提速 ---
with autocast():
logits = model(batch['input_ids'])
loss = criterion(logits, batch['labels']) / accumulation_steps
scaler.scale(loss).backward()
# --- 梯度累积:每 accumulation_steps 步才真正更新参数 ---
if (i + 1) % accumulation_steps == 0:
scaler.unscale_(optimizer)
# --- 梯度裁剪:L2 范数超过 max_norm 时等比缩放,防止梯度爆炸 ---
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
5.6 权重初始化
现代 LLM 通常采用 GPT-2 风格的初始化:所有 Linear 和 Embedding 层的权重用均值为 0、标准差为 0.02 的正态分布初始化,bias 置零。关键细节在于残差路径上的投影层(如注意力的输出投影 W_o 和 FFN 的下投影 down_proj)需要额外缩放标准差为
6. 各组件在现代 LLM 中的选择对比
| 组件 | 原始 Transformer | BERT | GPT-3 | LLaMA-2/3 |
|---|---|---|---|---|
| 激活函数 | ReLU | GELU | GELU | SwiGLU |
| 归一化 | LayerNorm | LayerNorm | LayerNorm | RMSNorm |
| 归一化位置 | Post-Norm | Post-Norm | Pre-Norm | Pre-Norm |
| 位置编码 | Sinusoidal | Learned | Learned | RoPE |
| 注意力 | MHA | MHA | MHA | GQA |
| FFN 中间维度 |
为什么现代 LLM 做出这些选择?
RMSNorm 替代 LayerNorm:LayerNorm 需要先计算均值再做方差归一化,RMSNorm 直接用均方根(RMS)缩放,省去减均值的一步。实验表明去掉均值项对模型效果几乎无影响,却能节省约 7% 的归一化计算量,在百亿参数的训练规模下积少成多。
Pre-Norm 比 Post-Norm 更稳定:Post-Norm 在残差相加之后再做归一化,梯度必须穿过归一化层才能流回浅层,容易衰减;Pre-Norm 先对输入归一化,残差路径本身是"干净"的,梯度可以直接绕过 Norm 层沿残差流传回,训练更稳定,不再需要精心设计的 warmup 才能收敛。
RoPE 成为位置编码标准:RoPE 将相对位置信息直接编码在 Q 和 K 的点积中,天然具有相对位置感知能力;更重要的是,通过调整旋转基底(如 YaRN、LongRoPE 等方法),可以在推理时将上下文窗口外推到远超训练长度的长度,这对实际部署场景至关重要。
GQA 几乎已成必选:自回归推理的 Decode 阶段需要为已生成的每个 token 维护 K/V 向量(即 KV Cache),它是推理显存的主要来源。标准 MHA 的 KV Cache 大小与 Q 头数成正比;GQA 让多个 Q 头共享少量 K/V 头,显存占用可降低 4~8 倍,同时模型质量接近 MHA。
7. 本章小结
回到本章开头的两个例子:
看图问答:图像被切成 patch,每个 patch 变成一个 token。Transformer 的 Self-Attention 让每个 patch 都能"看到"其他所有 patch,从而理解全局图像内容。语言问题同样被 tokenize,Cross-Attention 让文本 Query 图像特征,最终输出答案。
抓杯子:机器人的摄像头图像、语言指令"把杯子拿给我"、历史动作序列,全部被编码成 token 序列。Decoder-Only 的 Transformer 用 Causal Attention 处理这个混合序列,输出下一步的动作 token——这就是 VLA(Vision-Language-Action)模型的核心。
Transformer 是整个具身智能系统的计算引擎。无论是处理图像 patch、处理文字 token,还是最终生成动作,底层都是这一章讲的注意力机制。
下一章预告:同样的 Transformer 架构,如何驱动 LLM 一个 token 一个 token 地生成文字?我们将深入自回归生成机制、Tokenization、以及指令微调——理解 LLM 如何从"架构"变成"能力"。