4. 视觉编码器与对齐
1. 为什么 VLA 需要专门的视觉编码器?
1.1 VLA 中视觉编码器的角色
在 VLA(Vision-Language-Action)模型中,视觉编码器是第一个处理环节:
摄像头图像 → [视觉编码器] → 视觉特征 → [融合模块] → [LLM] → 动作输出
↑
你现在学的部分
视觉编码器的作用是将原始像素转化为高层语义特征,让后续的语言模型能够"理解"图像内容。
1.2 为什么不直接用 ViT?
你可能已经学过 ViT(Vision Transformer),但 VLA 中通常不会从头训练一个 ViT,而是使用预训练好的视觉编码器:
| 方式 | 说明 | 问题 |
|---|---|---|
| 从头训练 ViT | 随机初始化,在任务数据上训练 | 机器人数据太少,学不到好的视觉特征 |
| 使用预训练编码器 | 在大规模数据上预训练好的模型 | 需要选择合适的预训练方式 |
目前 VLA 中最常用的三种视觉编码器:
| 编码器 | 预训练方式 | 代表模型 | VLA 中的典型用法 |
|---|---|---|---|
| CLIP ViT | 对比学习(图文对) | OpenAI CLIP | RT-2, OpenVLA |
| SigLIP | Sigmoid 对比学习 | Google SigLIP | PaLM-E, OpenVLA |
| DINOv2 | 自监督学习 | Meta DINOv2 | Theia, 部分 VLA |
2. CLIP(Contrastive Language-Image Pre-training)
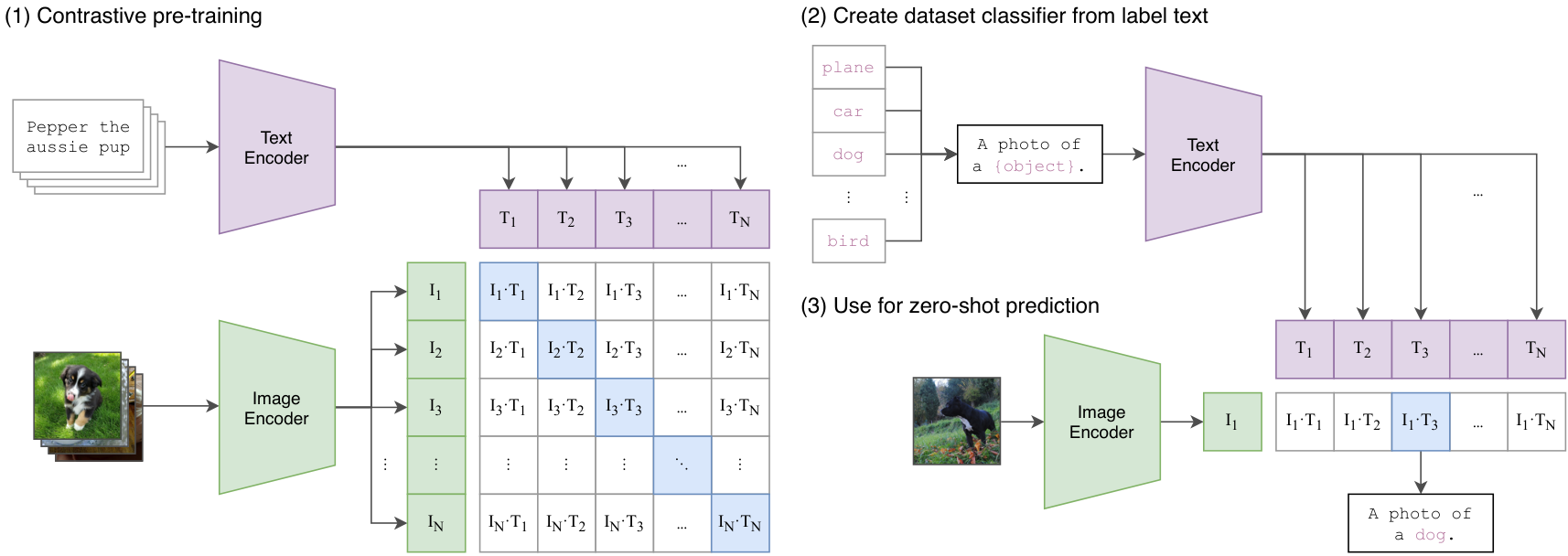
2.1 CLIP 的核心思想
一句话概括:让图像和描述它的文本在同一个向量空间中"靠近"。
CLIP 由 OpenAI 于 2021 年发布,核心创新是用自然语言监督来学习视觉表征。
训练数据:4 亿个 (图像, 文本描述) 对
来自互联网自然采集,无需人工标注
为什么这很重要?
- 传统视觉模型需要人工标注的分类标签(如 ImageNet 的 1000 类)
- CLIP 直接利用网络上现成的图文对,无需人工标注
- 这使得 CLIP 能学到更广泛的视觉概念(不局限于预定义类别)
- 学到的特征天然与自然语言对齐,方便 VLA 理解文本指令
2.2 CLIP 架构
┌──────────────┐
图像 ──────────→ │ Image │ ──→ 图像特征向量 f_img ∈ R^d
│ Encoder │
│ (ViT-L/14) │
└──────────────┘
↕ 对比学习:拉近配对,推远非配对
┌──────────────┐
文本 ──────────→ │ Text │ ──→ 文本特征向量 f_txt ∈ R^d
"a photo of │ Encoder │
a cat" │ (Transformer)│
└──────────────┘
关键点:
- Image Encoder:可以是 ViT 或 ResNet,VLA 中通常用 ViT-L/14 或 ViT-H/14
- Text Encoder:标准 Transformer(类似 GPT)
- 共享的嵌入空间:图像和文本被映射到同一个 d 维空间
架构设计的精髓:
- 两个编码器完全独立,各自处理自己的模态
- 最终通过投影层将两种特征映射到同一维度(如 512 或 768)
- 在这个共享空间中,语义相近的图文对距离近,不相关的距离远
- 这种设计使得图像和文本可以直接通过向量运算(如点积)比较相似度
2.3 对比学习损失(InfoNCE Loss)
2.3.1 核心直觉
给定一个 batch 的 N 个(图像, 文本)对:
- 正样本:配对的图文是正样本(对角线)
- 负样本:不配对的图文是负样本(非对角线)
Text_1 Text_2 Text_3 Text_4
Image_1 [ ✓ ✗ ✗ ✗ ]
Image_2 [ ✗ ✓ ✗ ✗ ]
Image_3 [ ✗ ✗ ✓ ✗ ]
Image_4 [ ✗ ✗ ✗ ✓ ]
✓ = 正样本(相似度应该高)
✗ = 负样本(相似度应该低)
直觉理解:
- 把这个 N×N 的相似度矩阵想象成一个"匹配表"
- 理想情况下,对角线元素(正确配对)的值应该远大于其他位置
- 对比学习的目标就是让模型学会"找到对角线"
- Batch Size 很重要:N 越大,负样本越多,学习信号越强(CLIP 使用 32,768 的超大 batch)
直觉理解:为什么大 Batch Size 这么重要?
想象你在学习"猫"的概念:
- 小 batch(N=4):每次只看 4 张图和 4 段文字。模型可能学到"棕色的东西"就是猫,因为样本太少,没有足够的反例。
- 大 batch(N=32K):每次同时看 32K 张图和 32K 段文字。模型必须区分猫、狗、老虎、兔子……所有动物,才能把"猫的图像"和"猫的文字"正确配对。
大 batch 强制模型学到更本质、更鲁棒的特征,而不是依赖表面的颜色或纹理。
对比学习之所以能让特征空间具有语义结构,是因为它同时施加了"拉近"和"推远"两种力:语义相近的概念(如"猫"和"小猫")因为经常与相似的图像配对而被拉到邻近区域,而语义无关的概念则被大量负样本推开。经过大规模训练后,整个嵌入空间自然形成了按语义聚类的拓扑结构——相似概念聚集成簇,不同概念彼此远离。
2.3.2 数学形式
设 batch 中有 N 个图文对,图像特征
相似度矩阵:
公式解读:
是图像特征和文本特征的点积,衡量两者的相似程度 - 分母
是 L2 范数的乘积,用于归一化(即计算余弦相似度) 是温度参数(temperature),控制分布的"锐度":
越小,softmax 后的分布越尖锐(更确定) 越大,分布越平滑(更均匀) - CLIP 中
是可学习的,初始值通常为
图像到文本方向(对每一行做 softmax):
公式解读:
- 对于每张图像
,我们希望它与正确配对的文本 的相似度 最高 - 分母
是图像 与所有文本的相似度之和 - 这本质上是一个 N 分类的交叉熵损失:给定图像,预测哪个文本是正确配对
文本到图像方向(对每一列做 softmax):
公式解读:
- 对称地,对于每段文本
,我们希望它与正确配对的图像 的相似度最高 - 这是从文本找图像的方向,确保双向对齐
最终损失:
为什么需要双向损失?
- 单向损失可能导致"坍缩":所有图像映射到同一点也能最小化单向损失
- 双向损失确保图像和文本都能区分彼此,形成结构化的嵌入空间
2.3.3 代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class CLIPLoss(nn.Module):
"""CLIP 对比学习损失"""
def __init__(self):
super().__init__()
# 可学习的温度参数,初始化为 log(1/0.07)
self.logit_scale = nn.Parameter(torch.ones([]) * torch.log(torch.tensor(1/0.07)))
def forward(self, image_features, text_features):
"""
image_features: (N, D) 归一化后的图像特征
text_features: (N, D) 归一化后的文本特征
"""
# 对特征做 L2 归一化,使点积等价于余弦相似度
image_features = F.normalize(image_features, dim=-1) # (N, D) → 每行 L2 范数为 1
text_features = F.normalize(text_features, dim=-1) # (N, D) → 每行 L2 范数为 1
# 计算 N×N 相似度矩阵,乘以温度系数放大差异
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t() # (N, D) @ (D, N) → (N, N)
logits_per_text = logits_per_image.t() # (N, N),转置即为文本→图像方向
# 对角线位置是正样本,对每行做 N 分类:label[i]=i 表示图像 i 对应文本 i
labels = torch.arange(len(image_features), device=image_features.device) # (N,)
# 双向交叉熵:图像→文本 + 文本→图像,确保双向对齐
loss_i2t = F.cross_entropy(logits_per_image, labels)
loss_t2i = F.cross_entropy(logits_per_text, labels)
return (loss_i2t + loss_t2i) / 2
2.4 CLIP Image Encoder 细节
VLA 中通常使用 CLIP 的 ViT 变体:
| 变体 | Patch Size | 隐藏维度 | 层数 | 头数 | 图像分辨率 | 输出维度 |
|---|---|---|---|---|---|---|
| ViT-B/32 | 32 | 768 | 12 | 12 | 224 | 512 |
| ViT-B/16 | 16 | 768 | 12 | 12 | 224 | 512 |
| ViT-L/14 | 14 | 1024 | 24 | 16 | 224 | 768 |
| ViT-H/14 | 14 | 1280 | 32 | 16 | 224 | 1024 |
VLA 中的常见选择:ViT-L/14(性能与效率的平衡)
import torch
from transformers import CLIPModel, CLIPProcessor
# 加载预训练 CLIP
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
# 提取图像特征
image = ... # PIL Image
inputs = processor(images=image, return_tensors="pt")
# 方式 1:获取 [CLS] token 的全局特征
with torch.no_grad():
outputs = model.vision_model(**inputs)
cls_feature = outputs.pooler_output # (1, 768) 经过投影的全局特征
# 方式 2:获取所有 patch token 的特征(VLA 中更常用!)
patch_features = outputs.last_hidden_state # (1, 257, 1024)
# 257 = 1 (CLS) + 256 (16x16 patches)
# 去掉 CLS token
patch_features = patch_features[:, 1:, :] # (1, 256, 1024)
重要:在 VLA 中,通常使用所有 patch token 的特征(而非仅 CLS token),因为机器人操作需要空间位置信息。
2.5 CLIP 用于 VLA 的优势与局限
| 维度 | 优势 | 局限 |
|---|---|---|
| 语义理解 | 强大的语义表示,理解物体、场景 | 空间细粒度不够(因为训练目标是图文匹配) |
| 泛化性 | 在大量互联网数据上训练,泛化好 | 对机器人特定视角可能适配不足 |
| 语言对齐 | 特征天然与语言对齐 | 缺少精确的空间位置信息 |
| 使用便利 | HuggingFace 直接加载,生态完善 | 分辨率固定(224/336),需要特殊处理高分辨率 |
2.6 CLIP 的 Zero-Shot 分类能力
CLIP 无需任何额外训练即可做图像分类,这体现了它强大的视觉-语言对齐能力:
# Zero-Shot 分类
texts = ["a photo of a cat", "a photo of a dog", "a photo of a robot arm"]
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits_per_image # (1, 3) 图像与每段文本的相似度
probs = logits.softmax(dim=-1) # 归一化为概率
print(probs) # 例如: tensor([[0.02, 0.01, 0.97]])
这个能力在 VLA 中很重要:模型能理解自然语言指令中描述的物体和场景。
3. SigLIP(Sigmoid Loss for Language-Image Pre-training)
3.1 SigLIP 的动机
CLIP 的 Softmax 对比损失有一个问题:需要全局的 batch 信息。
CLIP 的问题:
┌──────────────────────────────────────────────┐
│ Softmax 需要对整个 batch 做归一化 │
│ │
│ logits = [s_11, s_12, ..., s_1N] │
│ prob_1 = exp(s_11) / Σ_j exp(s_1j) │
│ ↑ │
│ 需要所有 N 个样本的信息 │
│ │
│ 这限制了分布式训练的效率(需要跨 GPU 通信) │
└──────────────────────────────────────────────┘
3.2 SigLIP 的解决方案:Sigmoid Loss
核心改变:把 N 分类的 Softmax 问题,变成 N^2 个独立的二分类问题。
每个 (图像_i, 文本_j) 对独立判断"是否匹配":
其中:
是 sigmoid 函数: ,将任意实数映射到 是标签: 是图像 和文本 的相似度(带温度和偏置)
公式解读:
- 这是标准的二分类交叉熵损失(BCE),应用于
个图文对 - 对于正样本(
),损失为 ,希望 越大越好 - 对于负样本(
),损失为 ,希望 越小越好 - 关键优势:每个图文对的损失计算是独立的,不需要全局归一化
class SigLIPLoss(nn.Module):
"""SigLIP Sigmoid 对比学习损失"""
def __init__(self):
super().__init__()
self.logit_scale = nn.Parameter(torch.ones([]) * torch.log(torch.tensor(10.0)))
self.logit_bias = nn.Parameter(torch.tensor(-10.0))
def forward(self, image_features, text_features):
"""
image_features: (N, D)
text_features: (N, D)
"""
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.t() + self.logit_bias # (N, N)
# 标签矩阵:对角线为 1,其余为 -1
N = logits.shape[0]
labels = 2 * torch.eye(N, device=logits.device) - 1 # 1 or -1
# Sigmoid 二分类损失
loss = -F.logsigmoid(labels * logits).mean()
return loss
3.3 SigLIP vs CLIP 对比
| 维度 | CLIP (Softmax) | SigLIP (Sigmoid) |
|---|---|---|
| 损失函数 | N 路 Softmax 交叉熵 | N^2 个二分类 BCE |
| 归一化范围 | 需要全局 batch | 每对独立计算 |
| 分布式训练 | 需要跨 GPU 通信相似度矩阵 | 每个 GPU 可独立计算 |
| Batch Size | 越大越好,32K+ | 对 batch size 更鲁棒 |
| 性能 | 强 | 同等设置下略优 |
| 额外参数 | 温度 τ | 温度 τ + 偏置 b |
工程实践解读:CLIP 的 Softmax 需要在整个 batch 内归一化,这意味着训练时必须使用超大 batch(CLIP 原始实现使用了 32,768 的 batch size),在普通机器上复现代价极高。SigLIP 改用 Sigmoid 损失,每个图文对独立判断是否匹配,不依赖全局 batch 的负样本,小 batch 也能有效训练——这是学术界和资源有限的工程团队更倾向选择 SigLIP 的核心原因之一。
3.4 SigLIP 模型变体
| 模型 | 图像分辨率 | 参数量 | 输出特征维度 |
|---|---|---|---|
| SigLIP-B/16 | 224 | 86M (vision) | 768 |
| SigLIP-L/16 | 256 | 303M (vision) | 1024 |
| SigLIP-SO400M/14 | 384 | 400M (vision) | 1152 |
VLA 中的常见选择:SigLIP-SO400M/14-384(OpenVLA、PaLM-E 等使用)
from transformers import SiglipModel, SiglipProcessor
# 加载 SigLIP
model = SiglipModel.from_pretrained("google/siglip-so400m-patch14-384")
processor = SiglipProcessor.from_pretrained("google/siglip-so400m-patch14-384")
# 提取视觉特征
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
vision_outputs = model.vision_model(**inputs)
# 所有 patch token 特征 (VLA 中常用)
patch_features = vision_outputs.last_hidden_state # (1, 729, 1152)
# 729 = 27 x 27 patches (384/14 ≈ 27)
# 全局特征
pooled = vision_outputs.pooler_output # (1, 1152)
3.5 为什么 VLA 越来越倾向用 SigLIP?
- 性能更优:同等参数量下表现更好
- 训练更高效:sigmoid 损失在分布式训练中通信开销更小
- 更高分辨率:SigLIP-SO400M 支持 384 分辨率,提供更细粒度的空间信息
- Google 生态:PaLM-E、RT-2-X 等 Google 系 VLA 都使用 SigLIP
4. DINOv2(Self-Supervised Vision Transformer)
4.1 与 CLIP/SigLIP 的根本区别
CLIP / SigLIP: DINOv2:
有监督 (图文对) 自监督 (仅图像)
学习"这张图说的是什么" 学习"这张图的结构是什么"
全局语义 + 语言对齐 局部空间特征 + 几何信息
适合:理解指令中的物体和场景 适合:理解空间布局和几何关系
自监督特征与监督特征的本质区别:
DINOv2 不需要任何标注,模型通过图像自身的结构一致性来学习特征。正因为没有语言标签的约束,模型不会把注意力全部集中在"物体是什么"上,而是同时学习纹理、边缘、几何形状等低层次信息。这些低层次的结构细节在监督训练中往往被忽略,却正是精细操控任务(如毫米级抓取、位姿估计)所需要的:机器人需要知道的不只是"这是一个杯子",还要知道"杯子的握持点在哪里、边缘轮廓怎么分布"。
4.2 DINOv2 训练原理
直觉理解:自蒸馏是什么?
CLIP 靠"文字告诉我这张图是什么"来学习特征;DINOv2 靠"图像自身的一致性"来学习特征。
类比:你不需要别人告诉你,也能认出同一只猫的不同角度照片——因为它们有相同的纹理、形状和结构。DINOv2 就是让模型学会这种"同一物体的不同视角应该有相似特征"的能力。
具体做法:把同一张图裁成两个不同的视图,让"学生网络"的输出去匹配"教师网络"的输出。教师网络是学生网络的滑动平均(EMA),不直接训练,只跟着学生慢慢更新。
DINOv2 使用自蒸馏(Self-Distillation) + 掩码图像建模(Masked Image Modeling):
4.2.1 自蒸馏框架
┌──────────────┐
全局视图 ────────→│ Teacher │──→ 教师输出 t
(大裁剪) │ (EMA 更新) │
└──────────────┘
↕ 蒸馏损失:让学生输出接近教师输出
┌──────────────┐
局部视图 ────────→│ Student │──→ 学生输出 s
(小裁剪/掩码) │ (梯度更新) │
└──────────────┘
- Teacher:学生网络的指数移动平均(EMA),不直接参与梯度更新
- Student:通过梯度下降更新
- 数据增强:对同一张图像生成多个视图(全局/局部裁剪)
EMA 教师网络之所以能提供稳定的学习信号,是因为它的参数是学生网络历史参数的加权平均(
4.2.2 自蒸馏损失
def dino_loss(student_output, teacher_output, center, temp_s=0.1, temp_t=0.04):
"""
DINO 自蒸馏损失
student_output: 学生网络输出 (B, D)
teacher_output: 教师网络输出 (B, D) - 已 detach
center: 教师输出的移动平均中心
"""
# 教师用更低温度 → 更"尖锐"的分布
teacher_probs = F.softmax((teacher_output - center) / temp_t, dim=-1)
# 学生用更高温度 → 更"平滑"的分布
student_log_probs = F.log_softmax(student_output / temp_s, dim=-1)
# 交叉熵:让学生模仿教师
loss = -torch.sum(teacher_probs * student_log_probs, dim=-1).mean()
return loss
4.2.3 掩码图像建模(iBOT 组件)
原始图像 → Patch 序列: [P1, P2, P3, P4, P5, P6, ...]
↓ 随机掩码部分 patch
掩码后: [P1, [M], P3, [M], P5, P6, ...]
↓ 学生网络处理
学生输出: [z1, z2', z3, z4', z5, z6, ...]
↓ 教师网络处理原始图像
教师输出: [z1, z2, z3, z4, z5, z6, ...]
↓
损失: 让 z2' 接近 z2,z4' 接近 z4(被掩码位置的 token 要还原)
这使得 DINOv2 学到了局部空间特征——知道每个 patch 位置"应该有什么"。
4.3 DINOv2 的独特能力
DINOv2 学到了惊人的空间理解能力:
DINOv2 特征可以直接用于:
├── 语义分割(不需要微调)
├── 深度估计(不需要微调)
├── 物体对应关系(同一物体不同视角的特征匹配)
└── 场景理解(空间布局)
4.3.1 DINOv2 特征的空间性质
from transformers import Dinov2Model, AutoImageProcessor
model = Dinov2Model.from_pretrained("facebook/dinov2-large")
processor = AutoImageProcessor.from_pretrained("facebook/dinov2-large")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Patch-level 特征:每个 patch 都有独立的语义特征
patch_features = outputs.last_hidden_state[:, 1:, :] # (1, 256, 1024)
# 去掉 CLS token,剩余 256 个 patch 特征
# 可以 reshape 为 2D 特征图
H = W = int(patch_features.shape[1] ** 0.5) # 16
feature_map = patch_features.reshape(1, H, W, -1) # (1, 16, 16, 1024)
# 这个 feature_map 保留了空间结构!
4.4 DINOv2 模型变体
| 模型 | 参数量 | 隐藏维度 | 层数 | Patch Size |
|---|---|---|---|---|
| DINOv2-S | 22M | 384 | 12 | 14 |
| DINOv2-B | 86M | 768 | 12 | 14 |
| DINOv2-L | 300M | 1024 | 24 | 14 |
| DINOv2-G | 1.1B | 1536 | 40 | 14 |
4.5 DINOv2 用于 VLA 的场景
DINOv2 通常不单独用于 VLA,而是与 CLIP/SigLIP 互补使用:
方案 1:仅用 CLIP/SigLIP(大多数 VLA 的选择)
图像 → CLIP ViT → 视觉 token → LLM
优点:语言对齐好,理解指令中的物体
缺点:空间信息可能不够精确
方案 2:仅用 DINOv2
图像 → DINOv2 → 视觉 token → LLM
优点:空间信息好,几何理解强
缺点:没有语言对齐,需要额外对齐
方案 3:CLIP + DINOv2 互补(如 Theia, Prismatic VLM)
图像 → CLIP ViT → concat → 视觉 token → LLM
→ DINOv2 → ↗
优点:兼顾语义理解和空间信息
缺点:计算量更大,token 数更多
Prismatic VLM(OpenVLA 使用的视觉骨架)就采用了方案 3:
# Prismatic VLM 的双编码器特征融合(简化版)
class DualVisionEncoder(nn.Module):
def __init__(self, clip_model, dino_model, projection_dim):
super().__init__()
self.clip_encoder = clip_model.vision_model
self.dino_encoder = dino_model
# 将两种特征投影到统一维度
self.clip_proj = nn.Linear(1024, projection_dim) # CLIP ViT-L
self.dino_proj = nn.Linear(1024, projection_dim) # DINOv2-L
def forward(self, images):
# 分别提取特征
clip_features = self.clip_encoder(images).last_hidden_state[:, 1:, :]
dino_features = self.dino_encoder(images).last_hidden_state[:, 1:, :]
# 投影 + 拼接
clip_proj = self.clip_proj(clip_features) # (B, N, D)
dino_proj = self.dino_proj(dino_features) # (B, N, D)
# 沿特征维度拼接
fused = torch.cat([clip_proj, dino_proj], dim=-1) # (B, N, 2D)
return fused
5. 三者详细对比
5.1 预训练范式对比
| 维度 | CLIP | SigLIP | DINOv2 |
|---|---|---|---|
| 监督信号 | 图文对 | 图文对 | 仅图像 |
| 训练方式 | Softmax 对比学习 | Sigmoid 对比学习 | 自蒸馏 + 掩码建模 |
| 训练数据量 | 4 亿图文对 | WebLI 数据集 | 1.42 亿图像 |
| 语言对齐 | 强 | 强 | 无 |
| 空间特征 | 中等 | 中等 | 强 |
| 语义理解 | 强 | 强 | 中等(无语言) |
5.2 输出特征对比
CLIP ViT-L/14 (224x224):
CLS token: (1, 768) ← 全局语义
Patch tokens: (1, 256, 1024) ← 16x16 grid
SigLIP-SO400M/14 (384x384):
CLS token: (1, 1152) ← 全局语义
Patch tokens: (1, 729, 1152) ← 27x27 grid(更高分辨率!)
DINOv2-L/14 (224x224):
CLS token: (1, 1024) ← 全局表示
Patch tokens: (1, 256, 1024) ← 16x16 grid(空间信息更丰富)
5.3 在 VLA 中的实际使用
| VLA 模型 | 使用的视觉编码器 | 特征提取方式 |
|---|---|---|
| RT-2 | CLIP ViT-L | Patch tokens |
| PaLM-E | ViT-22B (类 SigLIP 训练) | Patch tokens |
| OpenVLA | SigLIP + DINOv2 (Prismatic) | Patch tokens 拼接 |
| Octo | 从头训练的小 ViT | Patch tokens |
| pi0 | SigLIP | Patch tokens |
5.4 VLA 中如何选择视觉编码器
在实际搭建 VLA 系统时,视觉编码器的选择取决于任务类型和资源约束,并没有放之四海而皆准的答案。以下是几条实用的决策思路:
-
任务需要强语义理解(理解物体类别、场景语义、指令中的物体描述):优先选择 CLIP 或 SigLIP。它们通过大规模图文对训练,特征天然与语言语义对齐,模型能直接将"红色杯子"等自然语言描述与视觉特征挂钩,无需额外的对齐工作。
-
任务需要细粒度空间感知(精确抓取、位姿估计、像素级定位):优先考虑 DINOv2。自监督训练保留了更多纹理和几何细节,patch 级特征的空间结构性远强于图文对比学习的产物。
-
SigLIP 优于 CLIP 的场景:训练资源有限时,SigLIP 的 Sigmoid 损失使每个样本独立计算,不依赖全局 batch 的负样本,小 batch 下也能有效收敛,复现成本远低于需要 32K batch 的 CLIP。
-
实际 VLA 项目的常见选择:OpenVLA 使用 SigLIP(配合 DINOv2 的双编码器方案),RT-2 使用 CLIP ViT-C,Theia 专门研究了 DINOv2 特征在操控任务中的价值。
结论:没有绝对最优的编码器,任务类型和数据规模决定最终选择。
6. 图像预处理:从原始图像到模型输入
6.1 标准预处理流程
原始图像 Resize 归一化 Patch Embedding
(任意尺寸) ──→ (224×224×3) 或 (384×384×3) ──→ (标准化像素值) ──→ Token 序列
↓ ↓
双线性插值/ 减均值除标准差
Bicubic 插值 (ImageNet 统计量)
6.2 预处理代码详解
三种编码器的预处理流程结构相同(Resize → ToTensor → Normalize),主要差异在于输入分辨率和归一化参数:
| 编码器 | 输入分辨率 | Resize 方式 | 归一化均值 (mean) | 归一化标准差 (std) |
|---|---|---|---|---|
| CLIP ViT-L/14 | 224×224 | Resize(224) + CenterCrop(224) | [0.4815, 0.4578, 0.4082] | [0.2686, 0.2613, 0.2758] |
| SigLIP-SO400M | 384×384 | Resize((384, 384)) | [0.5, 0.5, 0.5] | [0.5, 0.5, 0.5] |
| DINOv2-L | 224×224 | Resize(256) + CenterCrop(224) | [0.485, 0.456, 0.406] | [0.229, 0.224, 0.225] |
以 CLIP 为例,标准预处理代码如下(SigLIP 和 DINOv2 只需替换分辨率和归一化参数):
from torchvision import transforms
# 标准 CLIP 预处理
clip_transform = transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(), # [0, 255] → [0, 1]
transforms.Normalize(
mean=[0.48145466, 0.4578275, 0.40821073], # CLIP 特定的均值
std=[0.26862954, 0.26130258, 0.27577711] # CLIP 特定的标准差
),
])
6.3 分辨率与 Patch Embedding 的关系
| 输入分辨率 | Patch Size | Grid 大小 | Token 数量 | 含义 |
|---|---|---|---|---|
| 224×224 | 14 | 16×16 | 256 | 每个 token 覆盖 14×14 像素区域 |
| 224×224 | 16 | 14×14 | 196 | 每个 token 覆盖 16×16 像素区域 |
| 384×384 | 14 | 27×27 | 729 | 更高分辨率,更多 token |
| 336×336 | 14 | 24×24 | 576 | LLaVA-1.5 使用的分辨率 |
VLA 中的考量:
- 更多 token = 更多空间信息 = 更好的操作精度
- 但更多 token = LLM 需要处理更长序列 = 推理更慢
- 需要在精度和速度之间权衡
6.4 VLA 中的图像预处理特殊注意
VLA 场景下的图像预处理与通常的视觉任务有本质区别:机器人摄像头返回的图像携带了完整的空间语义,预处理必须保留这些信息。具体而言,不能做随机水平翻转,因为翻转会颠倒左右方向的语义("拿左边的杯子"会变成拿右边);不能做大幅随机裁剪,否则会丢失工作台边缘、障碍物等关键环境信息;Resize 时也需注意保持长宽比,避免引入几何畸变。可以安全使用的增强手段包括颜色抖动(color jitter)、轻微缩放和高斯模糊——这些只改变外观而不改变空间关系。
7. 冻结 vs 微调:VLA 中如何使用视觉编码器
7.1 三种使用策略
策略 1:完全冻结(Frozen) ← 最常见
视觉编码器参数不更新,只训练后续模块
优点:训练快,不会破坏预训练特征
缺点:无法适配特定视觉域
策略 2:部分微调(Partial Fine-tuning)
冻结前几层,微调后几层
优点:平衡适配性和稳定性
策略 3:LoRA 微调
在视觉编码器中注入 LoRA 适配器
优点:极少参数即可适配,不破坏原始特征
# 策略 1:完全冻结 — 将视觉编码器所有参数的 requires_grad 设为 False
vision_encoder.requires_grad_(False)
# 策略 2:部分微调 — 冻结前 N 层,只放开最后几层的梯度
for layer in vision_encoder.layers[:N]: layer.requires_grad_(False)
# 策略 3:LoRA 微调 — 通过 PEFT 库对 Q/V 投影注入低秩适配器(r=16)
vision_encoder = get_peft_model(vision_encoder, LoraConfig(r=16, target_modules=["q_proj", "v_proj"]))
8. 总结与学习路线建议
8.1 核心知识速查
| 概念 | 一句话总结 |
|---|---|
| CLIP | 用对比学习让图像和文本在同一空间对齐 |
| SigLIP | CLIP 的改进版,用 Sigmoid 替代 Softmax,训练效率更高 |
| DINOv2 | 自监督视觉模型,擅长空间和几何理解 |
| Patch Tokens | VLA 中取所有 patch 的特征(而非仅 CLS),保留空间信息 |
| 冻结编码器 | VLA 中最常见的做法,不更新视觉编码器参数 |
| 双编码器 | SigLIP + DINOv2 互补,兼顾语义和空间 |
8.2 建议学习顺序
1. 先跑通 CLIP 的使用示例(HuggingFace)
→ 理解 image_features 和 text_features 的含义
2. 学习 InfoNCE Loss 的数学推导
→ 理解对比学习的本质
3. 对比 CLIP 和 SigLIP 的代码差异
→ 理解 Sigmoid vs Softmax 的 trade-off
4. 用 DINOv2 做一个简单的可视化
→ 看看 DINOv2 的 patch features 能否分割物体
5. 阅读 OpenVLA 中 Prismatic VLM 的视觉编码器代码
→ 理解双编码器融合的实际实现
9. 本章小结与下一章预告
本章回答了两个核心问题:为什么 VLA 需要专门的视觉编码器,以及如何在不同编码器之间做出选择。
视觉编码器的"对齐"目标不只是让图像变成向量——而是让视觉特征和语言特征进入同一个可比较的语义空间。CLIP 和 SigLIP 通过大规模图文对训练实现了这种对齐;DINOv2 则专注于保留图像自身的结构信息,为精细操控提供更丰富的空间特征。
这种对齐是下一章(第 5 章:多模态融合与 VLM)的基础:只有特征已经在语义上对齐,投影层的任务才相对简单。如果视觉特征和语言特征处于完全不同的语义空间,即使最复杂的融合模块也难以弥合这道鸿沟。
在"抓杯子"任务中: CLIP/SigLIP 让模型能把"红色杯子"的图像和文字描述关联起来;DINOv2 则提供了杯子的边缘、位置等精细空间信息。
下一章预告: 即使特征已经对齐,维度还不匹配——视觉特征是一组 token 向量,LLM 的输入是文本 token 序列,两者如何"拼"在一起?如何让 LLM 同时看到图像和文字并联合推理?这就是多模态融合和 VLM 架构要解决的核心问题。
10. 参考资料
- Learning Transferable Visual Models From Natural Language Supervision - CLIP
- Sigmoid Loss for Language Image Pre-Training - SigLIP
- DINOv2: Learning Robust Visual Features without Supervision
- Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
- OpenVLA: An Open-Source Vision-Language-Action Model
- HuggingFace CLIP 文档
- HuggingFace SigLIP 文档