7. ACT 架构与关键机制
先修建议
- 行为克隆(Behavior Cloning)与 compounding error 的基本概念
- VAE/CVAE 的 ELBO 目标
- Transformer 编码器-解码器结构
本节目标
- 明确 ACT 在 VLA 课程中的定位与适用边界
- 读懂
k步动作分块为何能降低有效时域 - 理解 CVAE 如何处理人类示教的多模态性
- 读懂 ACT 的训练与推理闭环,并能对照论文消融解释关键数字
1. 论文定位与本章聚焦
ACT 来自 ALOHA 体系,面向双臂精细操作场景。原论文题目是 Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,目标并不是提出一个更通用的策略模型,而是回答一个更具体的问题:低成本硬件能否在真实世界中,通过高质量示教与合适的行为克隆结构,学会毫米级精细操作。
原论文的贡献可以分为两层:
ALOHA(系统层):以较低成本实现 50Hz 双臂遥操作、4 机位观测和高质量精细示教采集。ACT(算法层):为这些高频、长时序、人类示教数据设计更合适的 imitation learning 结构。
本章属于 VLA 路线阅读,重点展开算法层。ACT 关注的核心问题是”在 50Hz 精细操作下,行为克隆如何避免长时序误差崩溃”,具体拆成三点:
- 以动作序列预测替代单步预测,把”每步决策”改为”每段决策”。
- 用 CVAE 建模人类示教中的随机性与多解轨迹,而不是把多解任务压成单峰均值。
- 用 temporal ensembling 缓解朴素 chunking 的动作切换突变,提高执行平滑性。
需要注意:论文摘要级结果(”80-90% + 约 10 分钟示教”)与任务级数字(如 Slot Battery 96%、Thread Velcro 20%)来自不同粒度,引用时应区分。本章聚焦 ACT,但不能把论文读成”只靠一个网络结构就完成了精细操作”——理解结果时,始终要把 ALOHA 的系统能力当作前提条件。
2. 形式化定义
ACT 在时刻
其中动作是双臂目标关节位置(14 维),不是离散 token。低层控制由电机 PID 跟踪目标关节轨迹。
训练目标可写成“重构 + 正则”的组合:
说明:论文伪代码将重构项写为 MSE,但实际实现采用 L1 并观察到更高精度。本章统一写为
符号表:
| 符号 | 含义 |
|---|---|
| 时刻 | |
| 时刻 | |
| 从 | |
| chunk size,控制每次预测的时域长度 | |
| CVAE 隐变量(风格变量) | |
| KL 正则权重 | |
| temporal ensembling 的指数权重衰减系数 |
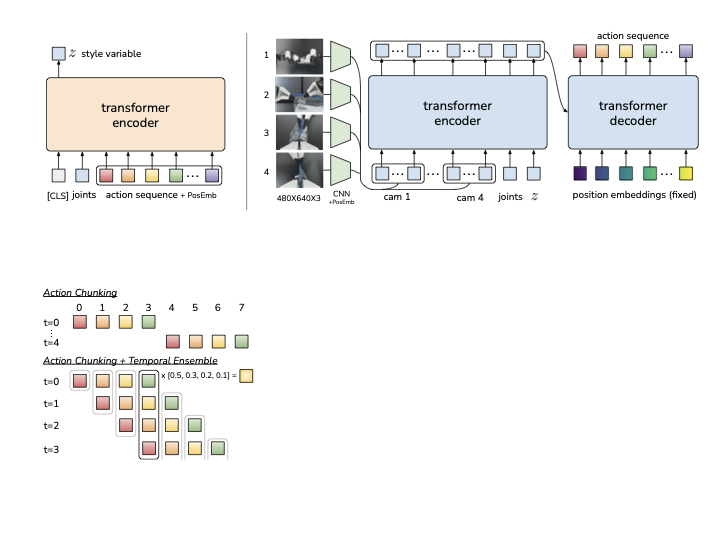
3. Action Chunking:从单步到分段
单步行为克隆学习
Action Chunking 的改动是把单步决策改成分段决策:
论文在这里最想强调的是:需要闭环修正的“有效决策次数”由
论文还强调了第二层动机:chunking 能更好覆盖示教中的 temporally correlated confounders——人类在中途短暂停顿、微调姿态、等待对齐等现象,单步 Markov 策略难以自然表达;而当这些变化落在同一个 chunk 内,模型更容易将其当作局部动作程序来建模。
因此,action chunking 同时改变了策略的决策粒度、有效时域,以及对非严格 Markov 示教片段的建模方式。
教学补充(非论文原式):如果用误差传播直觉来理解,单步 BC 的累计误差可以近似看成按
补充边界:论文原文重点陈述“有效时域缩短
4. CVAE 与示教多模态性
仅靠 chunking 还不够。论文把第二个挑战表述为 noisy human demonstrations:即使由同一个操作者采集,同一观测附近仍可能对应多条合法轨迹;而且在人类认为“精度不那么关键”的区段,动作往往更随机。若直接用单峰回归,模型容易把这些差异平均成一条不可执行的“中间轨迹”。
因此,CVAE 在 ACT 里的作用,并不只是抽象地“建模多模态”,而是更具体地处理人类示教中的随机性、多解性,以及不同精度区段的变化分布。
ACT 用条件变分自编码器建模该多模态性:
实现时使用
结构上的关键点:
- 编码器只在训练时使用,用当前本体感觉与目标动作序列推断
;为加速训练,论文实现不把图像送入编码器。 - 解码器(策略)在训练时接收观测与
,输出 动作。 - 推理时丢弃编码器,设
(先验均值)做确定性解码。
这里最容易误解的一点是:ACT 并不是在推理时不断采样不同风格动作再做选择。论文实际部署时直接固定
证据边界(来自论文消融):
- 在脚本数据(近似确定性)上,去掉 CVAE 影响很小。
- 在人类示教数据(多模态)上,去掉 CVAE 成功率从 35.3% 降到 2%。
5. Temporal Ensembling
朴素 chunking 每
这里沿用论文推理算法的记号:
该机制的作用:
- 不增加训练成本,仅增加推理时计算。
- 在同一时刻融合多个估计,缓和 chunk 边界处“突然切换观测”的不连续性。
- 不等价于“跨时刻平滑”,因为融合对象是“对同一时刻的不同预测”,而不是相邻时刻的动作。
关于超参数
论文消融显示:
- 在 ACT 上,temporal ensembling 带来约 3.3% 增益。
- 在 BC-ConvMLP 上约 +4%。
- 在 VINN 上可能下降,提示该机制更适配参数化策略的建模误差特性。
6. 模型架构与训练流程
6.1 模型结构
ACT 是 Transformer encoder-decoder 架构。
结构要点:
- 观测输入:4 路 RGB 图像(每路
)+ 双臂关节(14 DoF)。 - 图像编码:每路 ResNet18 输出
,展平为 。 - 多相机拼接:4 路合并得到
,再追加关节特征与 ,形成 编码器输入。 - 解码输出:解码器以长度为
的 query 生成 ,经 MLP 投影成 目标关节序列。
工程细节:
- 动作采用“绝对关节目标位置”,论文报告其优于关节增量形式。
- 编码器为提速可省略图像输入,仅用本体感觉+动作序列推断
。
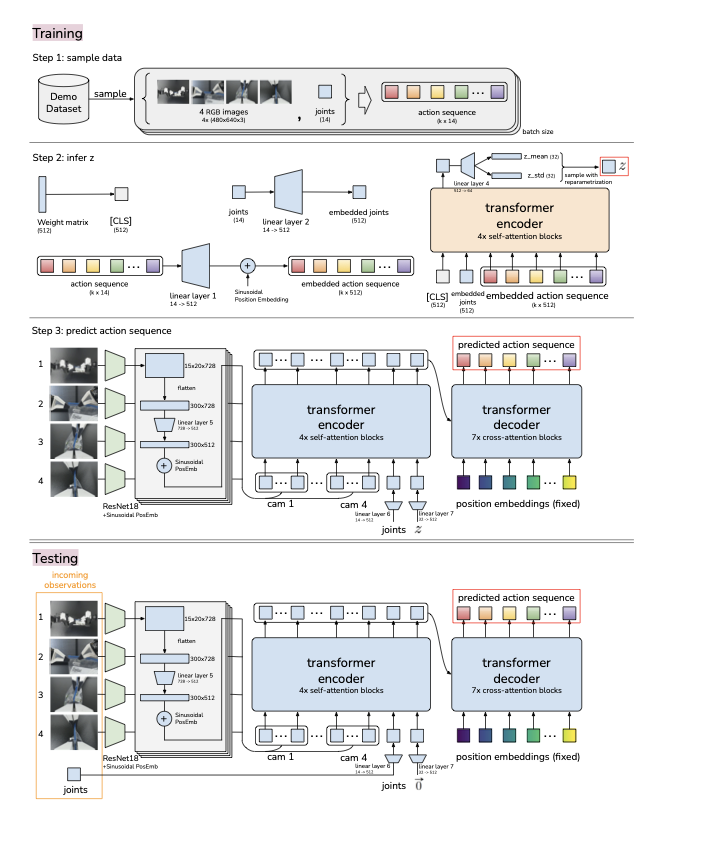
读图重点:下图用于理解 ALOHA 的 4 机位布局与双臂工作空间,对“为何需要高频闭环”很关键。

6.2 训练与推理闭环
训练流程:
- 采集时使用 leader 机械臂关节位置作为动作标签,而非 follower 端读数。
- 从示教数据采样
。 - 编码器估计
并采样 。 - 解码器预测
。 - 用重构项与 KL 项联合优化。
推理流程:
- 固定
,每步基于当前观测预测未来 步动作。 - 将预测写入对应时刻缓冲区。
- 对当前时刻候选动作做指数加权融合后执行。
训练/部署指标(同机型条件):
- 训练:单张 11G RTX 2080 Ti 约 5 小时。
- 推理:单步约 0.01 秒。
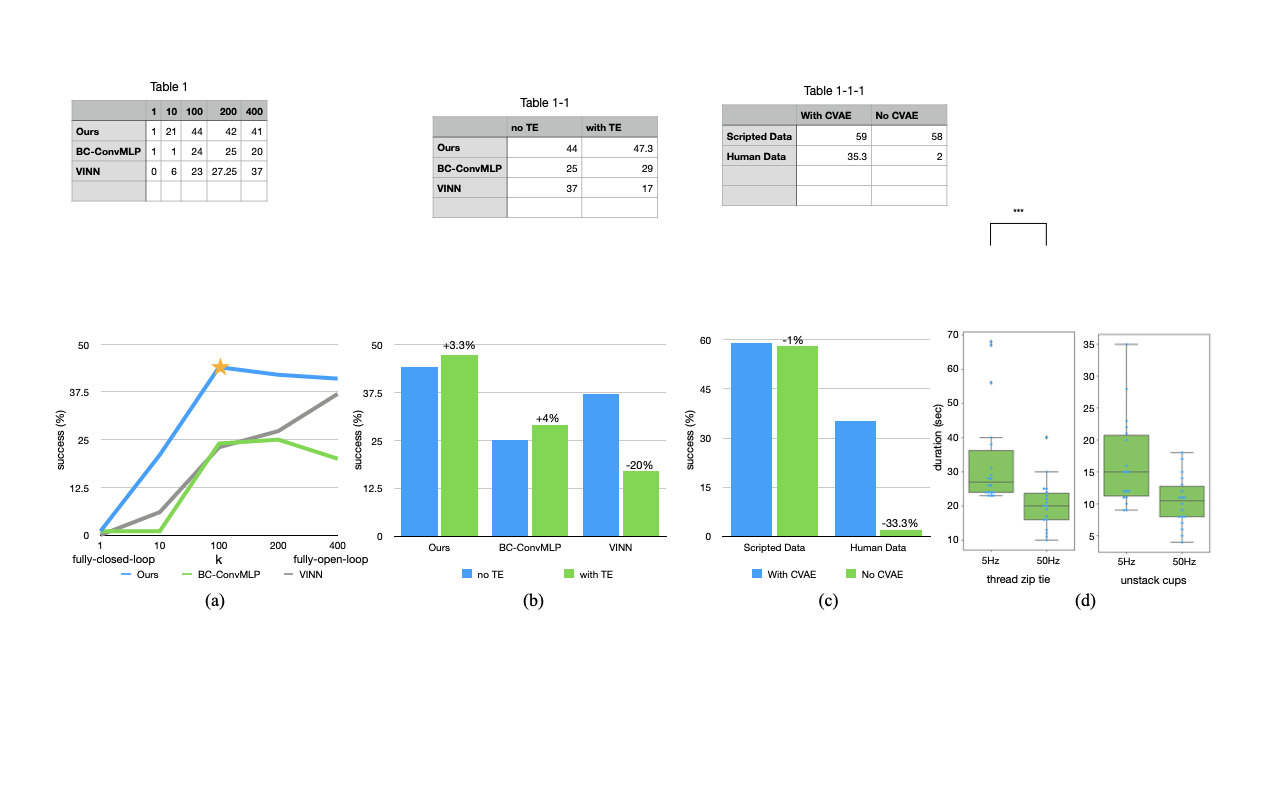
7. 实验结果与消融分析
7.1 数据与评估标准
- 真实任务共 6 个,示教多数任务 50 条,Thread Velcro 为 100 条。
- 每条示教约 8-14 秒,对应 50Hz 下约 400-700 步。
- 仿真任务分 scripted 与 human 两类示教,用于区分“确定性数据”和“多模态人类数据”的训练难度。
读图重点:下图先看 6 个真实任务的阶段拆分,再看每个阶段需要的双臂协同类型。

7.2 主结果与消融
主结果(真实任务)中,论文报告:
- Slide Ziploc:88%
- Slot Battery:96%
- Cup Open:84%
- Thread Velcro:20%
- Prep Tape:64%
- Put On Shoe:92%
关键消融:
chunk size:从到 ,平均成功率从 1% 提升到 44%,继续增大到接近开环时略有回落。 temporal ensembling:在 ACT 上约 +3.3%。CVAE:脚本数据影响小;人类示教数据从 35.3% 降到 2%(去掉 CVAE)。- 高频用户研究:50Hz 对比 5Hz,5Hz 条件下完成时间约增加 62%,统计显著性
。
注意:第 4 项验证的是系统前提(”高频遥操作对精细任务是否必要”),而非 ACT 算法模块本身的消融。
7.3 主张 - 证据 - 结论
| 论文主张 | 直接证据 | 学习者应得出的结论 |
|---|---|---|
| 单步 BC 的长时域不适合 50Hz 精细操作,action chunking 是关键结构变化 | k=1 到 k=100,平均成功率从 1% 提升到 44%;给 BC-ConvMLP、VINN 加 chunk 也能提升 | ACT 最核心的创新不是“用了 Transformer”,而是把策略对象从单步动作改成了动作块 |
| 仅有 chunking 还不够,执行端需要缓和 chunk 边界的突变 | temporal ensembling 在 ACT 上约 +3.3%,在 BC-ConvMLP 上约 +4%,在 VINN 上可能下降 | temporal ensembling 是执行层补丁,能提升平滑性,但不是对所有方法都必然有效 |
| 人类示教的随机性需要生成式训练目标,而不是单峰回归 | scripted data 上去掉 CVAE 几乎无影响;human data 上成功率从 35.3% 降到 2% | CVAE 的价值主要针对 human demos,不应把它理解成一个“任何数据都加分”的通用正则项 |
| 论文成绩依赖高频、高质量示教闭环,而不只是网络结构 | 5Hz 条件下人类遥操作完成时间约增加 62%,且真实任务实验都建立在 50Hz ALOHA 采集链路上 | 阅读 ACT 论文时,必须同时看到 ALOHA + ACT 的系统协同,而不是只看策略模块 |
7.4 工程总结(决策-收益-代价)
| 决策 | 直接收益 | 代价/边界 | 对后续路线影响 |
|---|---|---|---|
| Action Chunking( | 显著降低有效时域,压制长时序误差传播 | 被 Diffusion Policy 等后续方法继承 | |
| CVAE(含 | 对人类示教多模态显著增益 | 训练复杂度上升,需调 | 为后续生成式策略建模提供范式 |
| Temporal Ensembling | 提升动作平滑性与稳定性 | 仅推理增算,不保证所有方法收益 | 成为分块执行时常用的执行层补丁 |
| 高频闭环采集与控制(50Hz) | 更易覆盖毫米级精细操作 | 对系统实时链路要求高 | 强化“数据质量 + 控制频率”在精细操作中的地位 |
8. 局限与后续路线
ACT 的能力边界主要来自两侧:硬件与策略。
硬件侧限制:
- 多指协同任务受限(如需压扣+旋拧的复杂手部操作)。
- 大力矩任务受限(如紧瓶盖、高负载提举)。
- 依赖“指甲式”细小边缘操作仍然困难。
策略侧限制:
- 某些高感知难度任务失败明显,例如糖纸拆解、平放 ziploc 开袋等。
- 失败常由“难感知 + 形变不稳定 + 数据量不足”共同触发。
- Thread Velcro 结果显示:即使前段成功率高,后段插入阶段仍可能因毫米级误差累积而掉点。
因此,ACT 更像”精细操作行为克隆的结构性改进基线”,而非通用语义机器人基础模型。该路线与 RT-1/RT-2 的大模型扩展并不冲突:ACT 优先解决动作精度与时序稳定性,后者优先解决语义覆盖与泛化范围。后续两条演进路径分别对应:
- 8.diffusion_policy.md:在“动作分块”框架下替换分布建模器(CVAE -> diffusion)。
- 9.pi0_foundation_model.md:补足预训练语义与跨任务泛化,把分块控制与基础模型能力进一步整合。
9. 自测问题
如果能独立回答下面 4 个问题,说明本章主线已经基本掌握:
- 为什么 ACT 不能简单概括成“把行为克隆换成 Transformer”?
- 为什么 action chunking 不只是“多预测几步”,而是改变了有效时域和示教建模方式?
- 为什么 CVAE 在 scripted data 上作用很小、在人类示教上作用很大;而推理时又仍然可以设
? - 为什么阅读 ACT 的结果时,必须把 ALOHA 的 50Hz 遥操作与数据质量一起看?