8. Diffusion Policy 动作建模
先修建议
- 已理解行为克隆、条件动作分布和多模态示范数据的基本问题。
- 已接触 DDPM / DDIM 的去噪生成框架。
- 已了解控制频率、推理时延和 action chunking 的工程关系。
本节目标
- 用原论文的图表和数据读懂 Diffusion Policy 的核心设计。
- 理解它为何特别适合多模态、连续、精细的机器人动作建模。
- 看清
T_o / T_a / T_p、位置控制、DDIM 加速和视觉条件化之间的联动。 - 梳理论文真正证明了什么,以及它仍然受什么约束。
本文尽量直接使用原论文与补充材料中的原始图表和作者源码中的最终数值。对于 RoboMimic 等实验,如果论文同时报告”最佳 checkpoint”和”最后 10 个 checkpoint 平均值”,文中会保留这一统计方式。
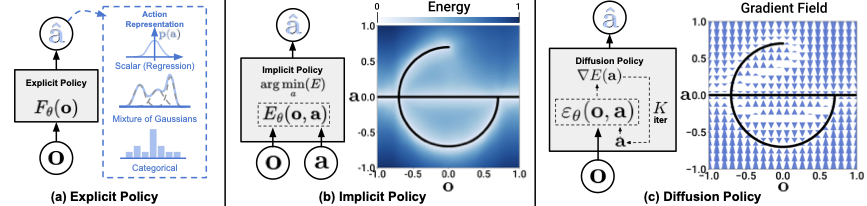
1. 论文定位与核心结论
Diffusion Policy 要证明的是:把机器人策略表示成条件动作扩散过程,在多模态动作、长时序一致性和真实部署上,比当时主流的 BC-RNN、IBC、BET 更稳、更强。
原论文核心结论:
| 维度 | 论文结论 |
|---|---|
| 任务覆盖 | 15 个任务,来自 4 个 benchmark,覆盖仿真与真实机器人 |
| 数据与环境 | 仿真与真实环境、单 / 多任务、刚体 / 液体对象、2DoF 到 6DoF 动作场景 |
| 总体结果 | 相对已有方法,平均成功率提升 46.9% |
| 关键设计 | receding-horizon action prediction、visual conditioning、time-series diffusion transformer |
| 实时推理 | DDIM 将训练 / 推理解耦;论文方法部分报告 100 次训练去噪、10 次推理去噪可在 Nvidia 3080 上达到约 0.1s 推理延迟 |
论文导言里的重点并不是“扩散一定优于所有策略表示”,而是下面三点:
- 动作分布往往是多峰的,单步回归容易掉进均值陷阱。
- 机器人动作不仅要对,还要在时间上连续、平滑、可执行。
- 真机部署不仅看离线分数,还要看推理时延、训练稳定性和 checkpoint 选择是否现实。
2. 任务版图与问题设定
论文评测把短时多模态、长时多模态、真实单臂、真实双臂放在同一条证据链上。

| 类别 | 代表任务 | 论文想检验的能力 |
|---|---|---|
| 仿真短时多模态 | Lift、Can、Square、Transport、ToolHang、Push-T | 给定当前观测后,是否能建模多种可行动作 |
| 仿真长时多模态 | Block Push、Kitchen | 子任务顺序可变时,是否还能保持长程一致性 |
| 真实单臂 | Real Push-T、Mug Flip、Pour、Spread | 精细接触、6DoF 姿态、液体与周期动作 |
| 真实双臂 | Egg Beater、Mat Unrolling、Shirt Folding | 协调双臂、布料操作、长步骤操作 |
Diffusion Policy 在论文中的基本对象不是单步动作,而是条件动作序列分布:
其中
这一定义直接服务于两个目标:
- 用动作块而不是单动作,显式约束时间一致性。
- 为 receding-horizon 控制预留缓冲,使系统能够在真实部署里对抗视觉、网络和控制链路带来的延迟。
3. 单步回归的多模态困境
Diffusion Policy 的切入点是机器人示范数据里确实存在系统性的多模态问题。
在 Push-T 这类任务中,同一个状态往往允许“从左侧接触”或“从右侧接触”两种同样合理的动作。如果把策略写成单步回归:
那么最优解会逼近条件均值,而均值恰好可能落在两个可行模式之间的低概率区。对图像回归,这可能只是模糊;对机器人动作,这通常意味着动作不可执行。
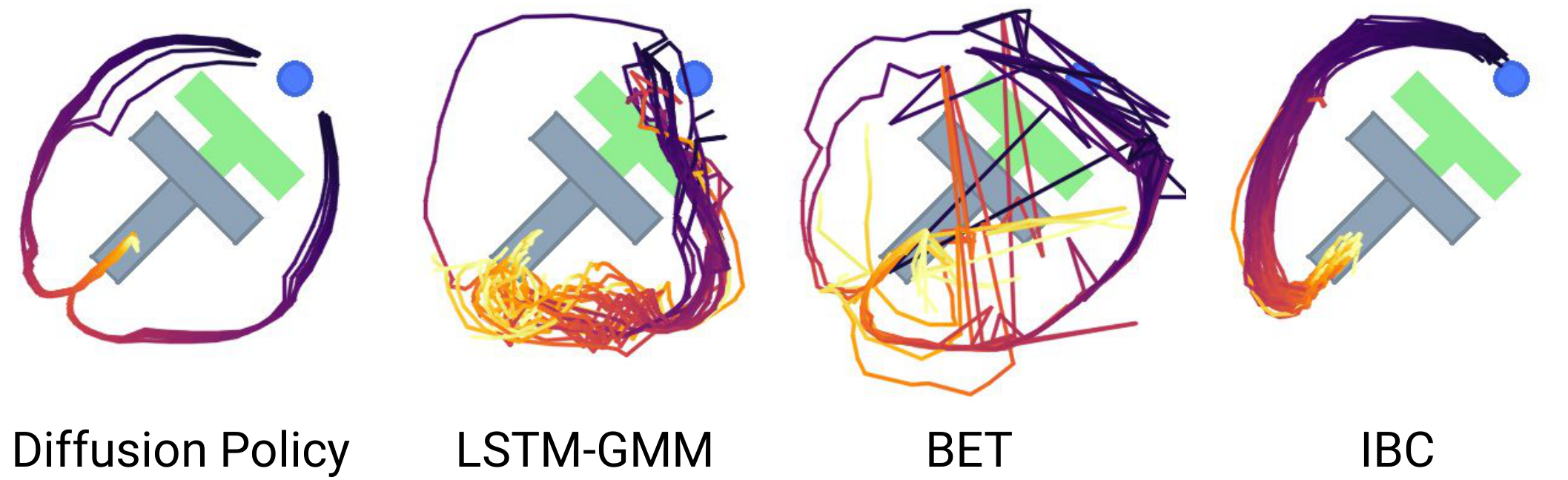
论文把多模态分成两类:
- 短时多模态:同一个即时目标有多种接近方式,例如左绕或右绕障碍。
- 长时多模态:多个子任务的完成顺序本身可变,例如先推哪个方块、先操作厨房里的哪个部件。
这也是为什么论文既需要 Push-T 这样的短时接触任务,也需要 Block Push、Kitchen 这样的长程任务。
4. 方法主线
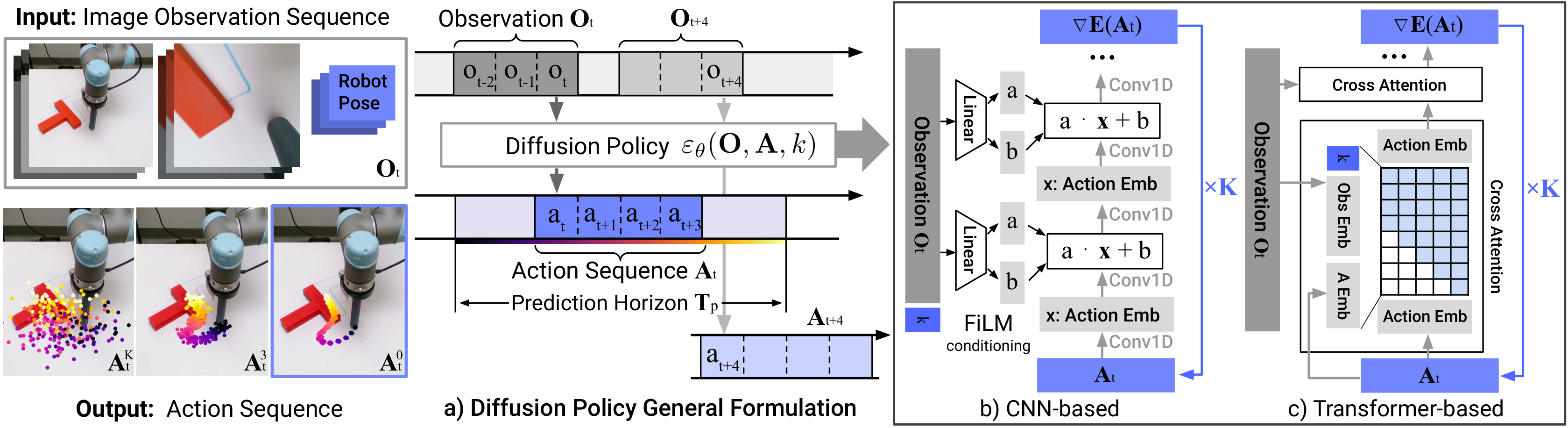
4.1 时间定义:T_o / T_a / T_p
论文里的三个时间超参数需要严格区分:
| 符号 | 含义 |
|---|---|
T_o | observation horizon,策略每次读取多少步观测 |
T_p | action prediction horizon,每次预测多少步未来动作 |
T_a | action execution horizon,每次真正执行多少步再重规划 |
在时间步 t,策略读取最近 T_o 步观测,预测未来 T_p 步动作,但只执行前 T_a 步,然后重新规划。这个设计不是后处理技巧,而是论文最重要的工程贡献之一。
4.2 条件动作扩散
论文把无条件 DDPM 改造成条件动作扩散,推理时的更新写成:
训练目标则写成:
这里的重点不是公式本身,而是以下三件事:
- 扩散变量不再是图像,而是动作序列。
- 观测作为条件输入,不跟动作一起被当成联合分布去生成。
- 噪声网络学习的是“如何把当前带噪动作推回更合理的动作分布流形”。
4.3 视觉条件化
视觉观测被当作条件,而不是像部分规划式 diffusion 方法那样把未来状态一起放进生成变量。收益:
- 视觉编码器在一次推理中只需执行一次,不必在每个去噪步里重复跑。
- 视觉特征与动作去噪解耦后,更容易支撑真机实时推理。
- 端到端训练视觉编码器变得可行。
在具体实现上,论文的视觉编码器使用了未预训练的 ResNet-18,并做了两项改动:
- 用 spatial softmax 代替全局平均池化,保留空间信息。
- 用 GroupNorm 代替 BatchNorm,以兼容扩散训练里常见的 EMA。
4.4 两种噪声网络
论文比较了两类主干:
| 主干 | 论文实现要点 | 经验结论 |
|---|---|---|
| CNN-based Diffusion Policy | 1D temporal CNN + FiLM 条件注入 | 大多数任务开箱即用,调参相对稳 |
| Time-series Diffusion Transformer | 动作 token 解码 + 观测 cross-attention | 高频变化、速度控制任务更有潜力,但更敏感 |
作者经验:CNN 版本更稳、更省心;Transformer 版本在动作变化频率高、任务更复杂时可能更好,但调参更难。
4.5 代表性超参数
下表不是“通用最佳实践”,而是论文里最常出现的代表性设置:
| 设置 | Ctrl | T_o | T_a | T_p | D-Iters Train | D-Iters Eval |
|---|---|---|---|---|---|---|
| RoboMimic / Push-T 的 CNN 主设定 | Pos | 2 | 8 | 16 | 100 | 100 |
| Real Push-T 的 CNN 设定 | Pos | 2 | 6 | 16 | 100 | 16 |
| Real Pour / Spread / Mug 的 CNN 设定 | Pos | 2 | 8 | 16 | 100 | 16 |
这张表对应的是作者源码里的最终超参数表。它也解释了为什么论文里反复出现两个结论:
T_o=2往往已经足够提供速度线索。- 真机部署必须依赖 DDIM,把推理步数从训练步数里解耦出来。
5. 关键消融与经验结论
5.1 位置控制 vs 速度控制
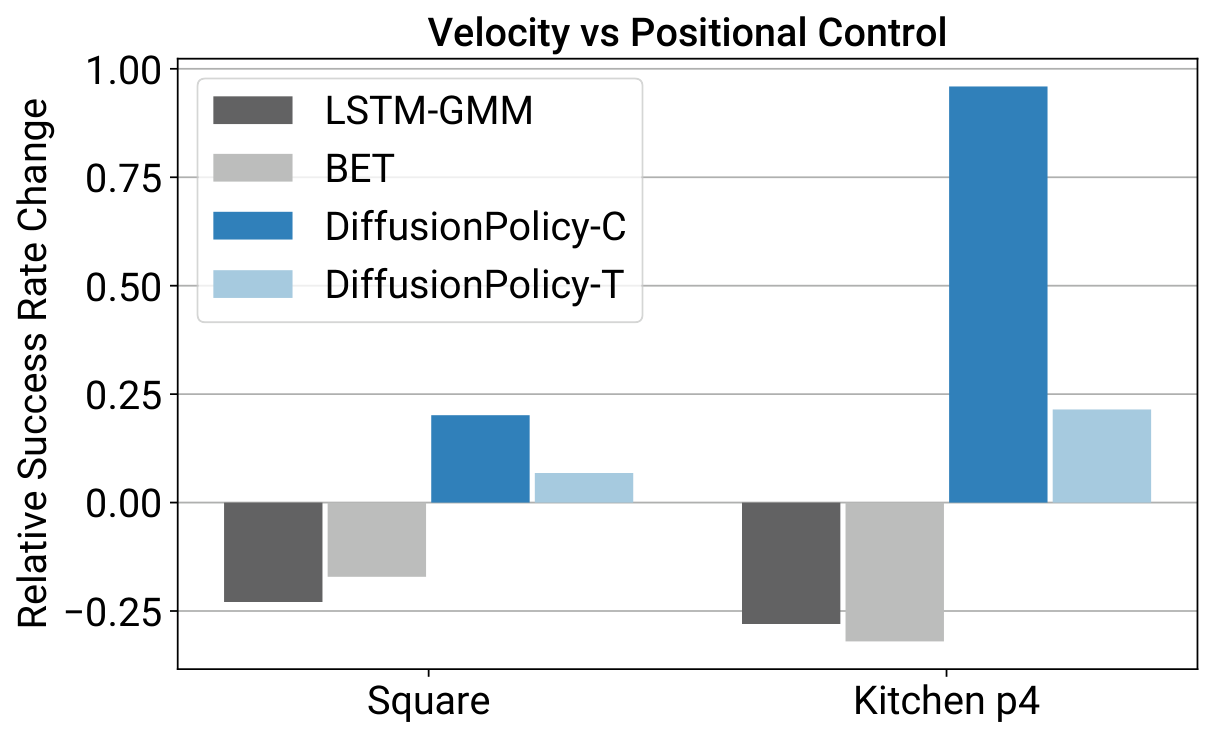
Diffusion Policy 更能发挥位置控制的精度优势。位置控制会让动作分布更”多模态”,但扩散策略恰好更擅长处理多峰分布;而 BC-RNN、BET 在位置控制下更容易表现为抖动和不稳定。
5.2 动作块长度的权衡
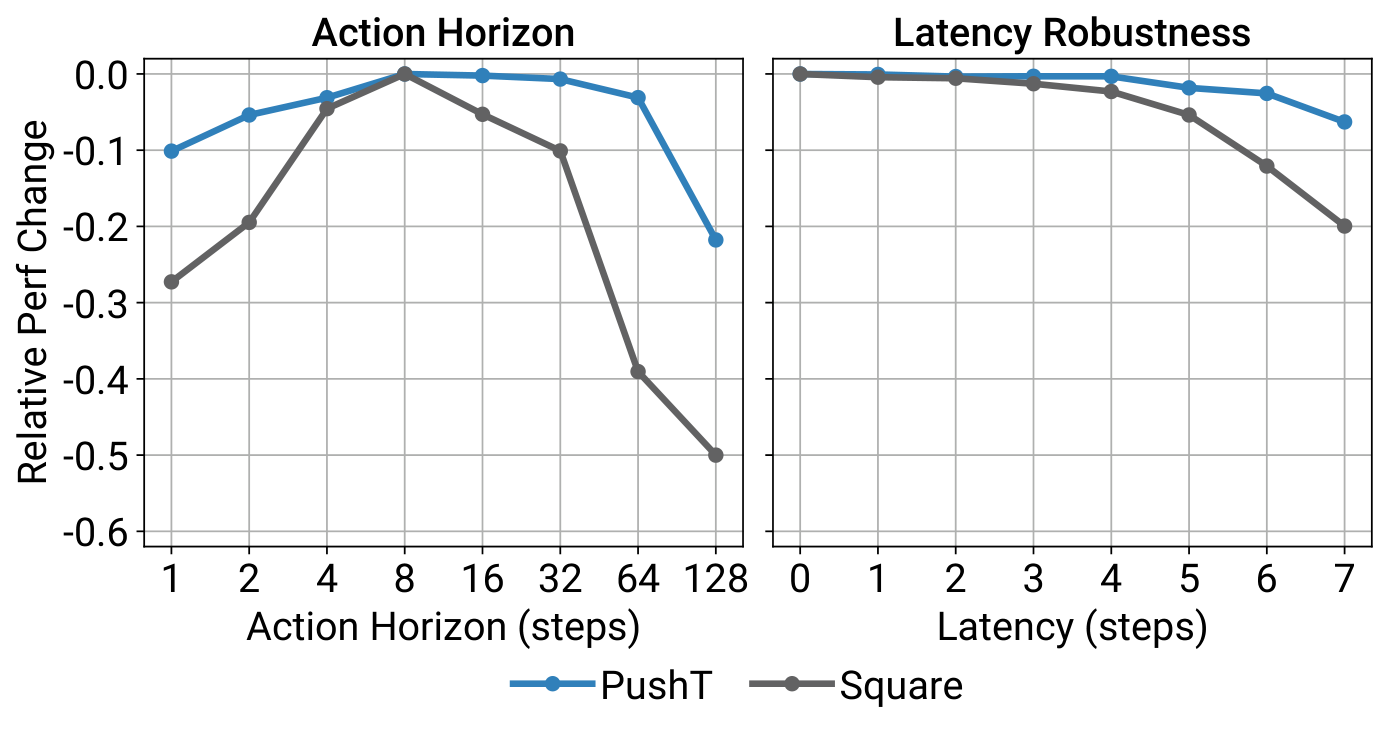
论文对 T_a 的结论非常明确:
T_a > 1往往优于单步执行,因为它能提高动作一致性,并填补示范数据中的 idle 片段。T_a过长又会损害响应性,因为策略重规划变慢。- 在作者测试的大多数任务里,
8步 action horizon 是比较好的折中。
同一张图右侧还支持了另一个部署结论:receding-horizon 的位置控制在存在延迟时更稳。论文文字说明中写到,在模拟延迟实验里,Diffusion Policy 能在最多 4 步延迟下维持峰值性能,而速度控制更容易因为误差累积而退化。
5.3 观测历史长度
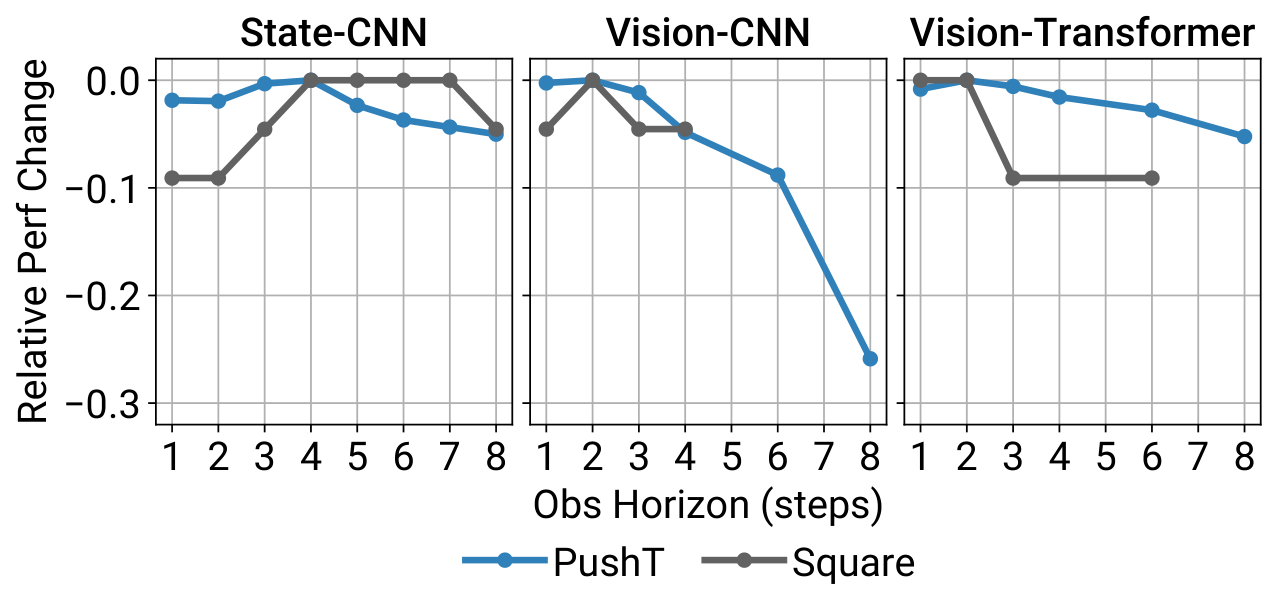
作者在补充材料中的总结是:
- 状态输入版本对
T_o不太敏感。 - 视觉输入版本更偏好较短但大于
1的历史。 T_o=2是大多数任务里的良好折中。
这也是前一节超参数表里大量出现 T_o=2 的原因。
5.4 数据效率
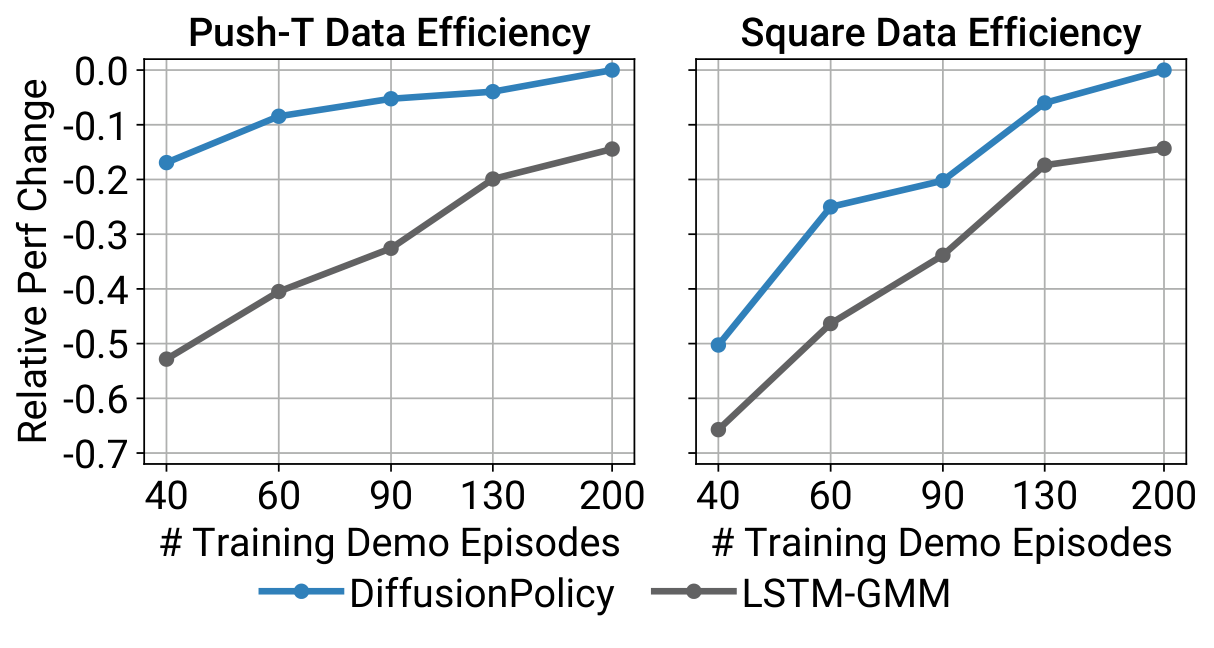
这张图给出的不是单点最好成绩,而是更稳健的趋势结论:不需要把数据规模拉到很大,Diffusion Policy 的优势就已经成立。
5.5 IBC 的训练稳定性问题
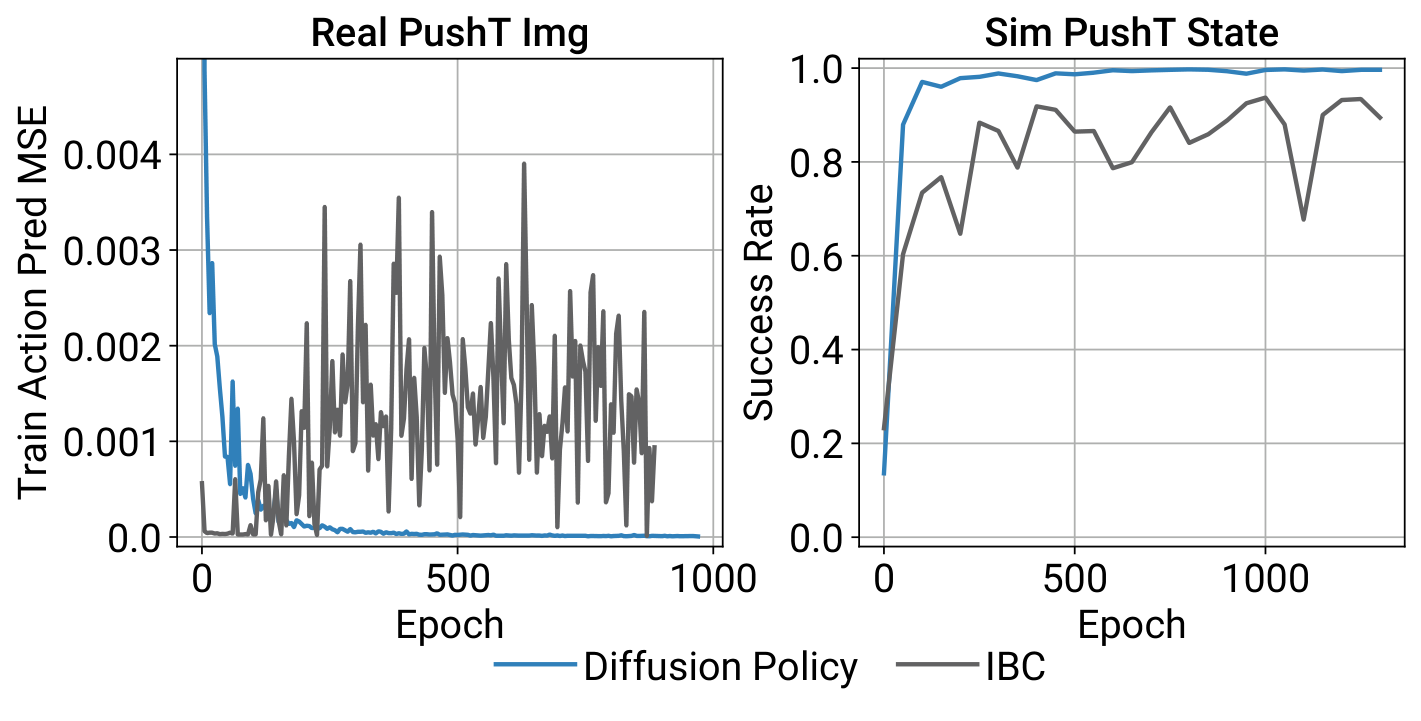
论文指出:IBC 的训练和 checkpoint 选择成本很高,不适合真机迭代。 Diffusion Policy 的核心卖点之一正是更容易被稳定训练和稳定选模。
6. 仿真实验结果
论文在仿真 benchmark 上在 state 和 image 两种观察设定下都稳定领先。代表性结果:
| 任务与指标 | 最强基线 | Diffusion Policy | 读法 |
|---|---|---|---|
| Transport(视觉,PH,best / last-10 avg) | BET 0.38 / 0.14 | Diffusion-T 1.00 / 0.84 | 复杂双臂搬运任务上优势明显 |
| ToolHang(视觉,PH,best / last-10 avg) | LSTM-GMM 0.67 / 0.31 | Diffusion-T 1.00 / 0.87 | 高精度挂接任务也成立 |
| Push-T(视觉,best / last-10 avg) | IBC 0.90 / 0.84 | Diffusion-C 0.95 / 0.91 | 接触丰富任务仍保持领先 |
Block Push p2 | BET 0.71 | Diffusion-T 0.94 | 长时多模态顺序建模更强 |
Kitchen p4 | BET 0.44 | Diffusion-C 0.99 | 长程多子任务组合显著领先 |
围绕这些数字,论文给出的三条解释值得保留:
- 短时多模态任务里,扩散采样比单次回归更容易保留多峰动作。
- 长时多模态任务里,动作块预测比逐步贪心更容易维持整段策略一致性。
- 图像输入下,视觉条件化让扩散策略不必在每个去噪步都重复生成观测,因此真正在系统层面可用。
作者在仿真部分还给出一个非常强的总括:在 RoboMimic 的 proficient-human 设定里,Diffusion Policy 的最佳 checkpoint 在多数任务上可以达到 100% 成功率;而在更难的 mixed-human、Block Push、Kitchen 等设定里,优势会更明显地体现在长尾指标上。
7. 真实机器人结果
7.1 Real Push-T
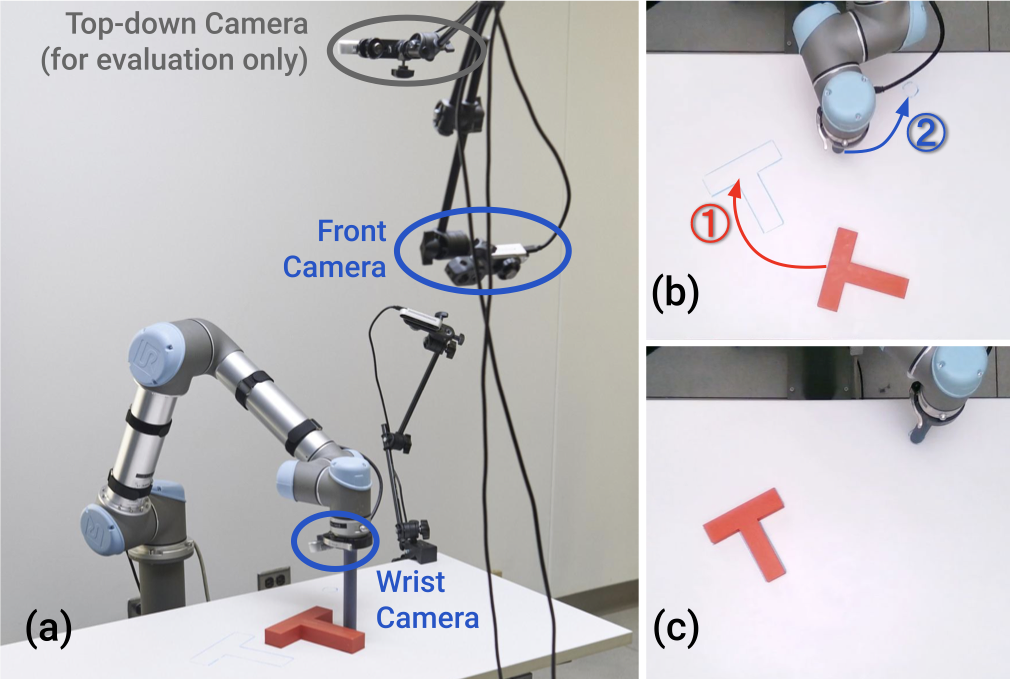
Real Push-T 的难点不只是“要推准”,而是:
- 任务是双阶段的,要在“继续细调”和“离开进入 end-zone”之间做切换。
- 评价看最后一步 IoU,而不是 rollout 过程中的最大覆盖率。
- 数据里不能简单删除 idle actions,因为任务本身就要求精细停顿和终止控制。
论文原表中的关键结果如下:
| 方法 | IoU | Success | Duration (s) |
|---|---|---|---|
| Human Demo | 0.84 | 1.00 | 20.3 |
| IBC(最佳变体) | 0.19 | 0.00 | 41.6 |
| LSTM-GMM(最佳变体) | 0.25 | 0.20 | 47.3 |
| Diffusion Policy E2E(最佳) | 0.80 | 0.95 | 22.9 |
论文这里的说法很强:Diffusion Policy 在真实 Push-T 上达到了接近人类示范的表现。

这组结果也解释了为什么论文如此强调训练稳定性和 action sequence:
- LSTM-GMM 常在 T 字块附近反复小动作,难以退出当前阶段。
- IBC 容易过早离开操控对象,提前进入 end-zone。
- Diffusion Policy 的动作块预测更容易跨过阶段边界,同时保持细调精度。
7.2 闭环恢复行为
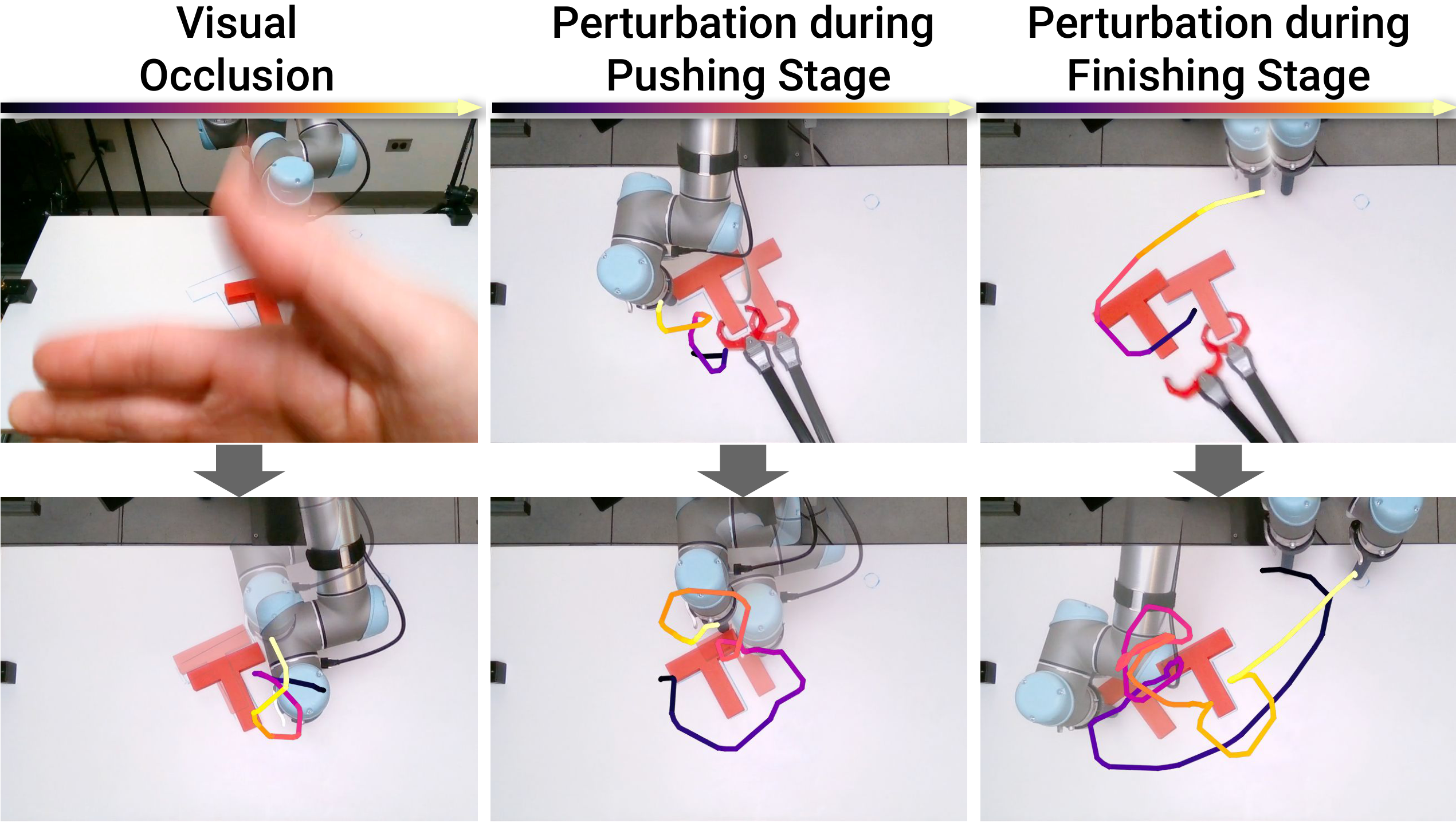
这组鲁棒性图说明:当观测发生扰动时,策略能在闭环中重新规划,而不是机械复现示范轨迹。 作者指出,某些”放弃去 end-zone、返回重新推块”的行为在训练集中并没有直接示范。
7.3 6DoF 任务:Mug、Pour、Spread

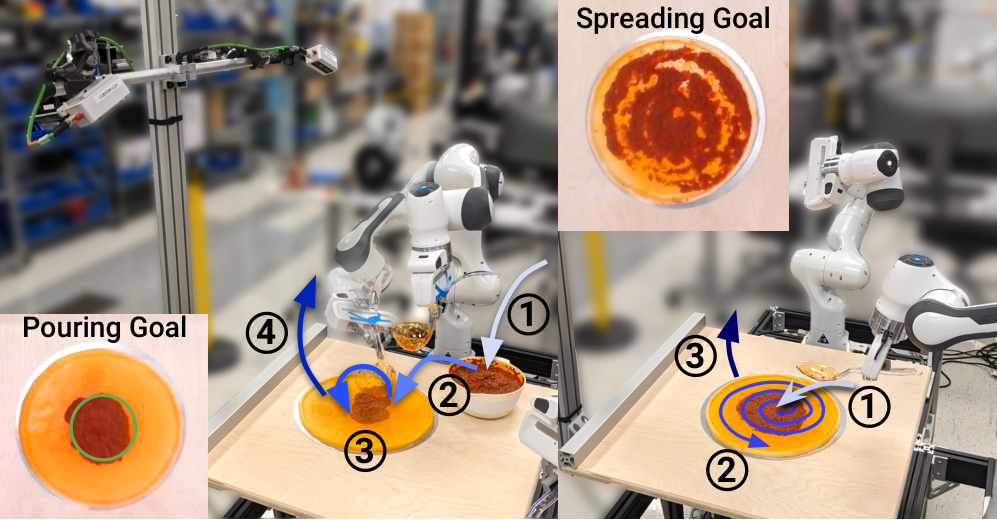
这些真实任务的原始结果可以概括如下:
| 任务 | 论文指标 | Human | Diffusion Policy |
|---|---|---|---|
| Mug Flip | Success | 1.00 | 0.90 |
| 6DoF Pour | IoU / Success | 0.79 / 1.00 | 0.74 / 0.79 |
| Periodic Spread | Coverage / Success | 0.79 / 1.00 | 0.77 / 1.00 |
这些数字说明 Diffusion Policy 的优势不局限于 Push-T 这类平面接触任务,在 3D 旋转(Mug Flip)、多阶段液体操作(Pour)和周期非刚体动作(Spread)上同样成立。
7.4 双臂任务
论文扩展版补充了三个双臂真实任务,作者写到:Diffusion Policy 在这些任务上可以直接开箱使用,无需额外超参数调节。
| 双臂任务 | 训练示范数 | 成功率 | 论文记录的主要失败模式 |
|---|---|---|---|
| Egg Beater | 210 | 0.55 | 初始摆放越界、错过或丢失曲柄把手 |
| Mat Unrolling | 162 | 0.75 | 初始抓取失败后难以恢复,容易重复同一动作 |
| Shirt Folding | 284 | 0.75 | 袖口 / 领口抓取失败,末段不断微调而停不下来 |



这三组任务把结论从”单臂精细操控”扩展到了”真实双臂长流程操控”。
8. 设计原则、局限与后续路线
如果把整篇论文压缩成工程结论,最值得记住的是:
-
动作块建模比单步回归更适合机器人示范数据。 它自然提供时间一致性,并能与 receding horizon 组合。
-
扩散的价值不只在多模态表达,还在真实部署的稳定性。 论文反复对比的是:能否稳定训练、能否现实地选 checkpoint、能否在真机上闭环运行。
-
位置控制是关键经验点。 Diffusion Policy 在 position control 下更能发挥优势,而非被动适配 velocity control。
-
视觉条件化和 DDIM 加速决定了能否真正上机器人。 如果每个去噪步都要重跑视觉编码,或者推理步数降不下来,真机结果很难成立。
主要局限:
- 推理成本偏高。 即使用 DDIM 把真机推理步数降到
10或16,它依然不是天然高频控制方案。 - Transformer 版本更敏感。 在高频变化任务上有潜力,但超参数和训练稳定性更难处理。
- 策略质量受示范覆盖限制。 扩散策略可以在闭环中合成恢复动作,但不能学会完全脱离数据支持的技能。
Diffusion Policy 之所以重要,不是因为”扩散模型进入机器人”这件事本身,而是它第一次把多模态动作建模、动作块闭环控制、真实系统时延约束和稳定训练放进了同一套可运行的策略框架里。
后续再看 ACT、OpenVLA、π₀、RTC 这类路线时,本章提供的是一个清晰的参照系:当任务强调连续动作精度、局部轨迹质量和多模态恢复行为时,Diffusion Policy 依然是需要反复对照的强基线。