6. OpenVLA 复现与关键取舍
先修建议
- 已完成 RT-2 与 Open X 相关章节,理解动作 token 路线与数据混合背景。
- 熟悉 LLM/VLM 微调常见术语(LoRA、量化、推理服务)。
- 了解机器人部署中的时延、频率与稳定性评估口径。
本节目标
- 说明 OpenVLA 在 RT-2 之后到底补上了哪一层开源工程能力。
- 拆解 OpenVLA 的完整链路:任务定义、数据策展、架构选择、训练配方、评测解释与系统落地。
- 明确哪些结论来自论文直接证据,哪些只是便于理解的工程解释。
OpenVLA 常被概括成”7B 开源版 RT-2-X”,但它真正回答的问题是:当 RT-2 已经证明”把 VLM 迁移到机器人控制”这条路线有效之后,社区能否把它变成可复现、可微调、可部署的开源工程体系。与相邻路线相比,OpenVLA 更适合理解”语言 grounding + 多机器人预训练 + 下游适配”这条主线;如果任务重点是更高频、更平滑的连续控制,后面的 ACT 或 Diffusion Policy 往往更自然。
读图重点:先看整体工程链路,再把后文的每个设计决策放回这张总览图里理解。
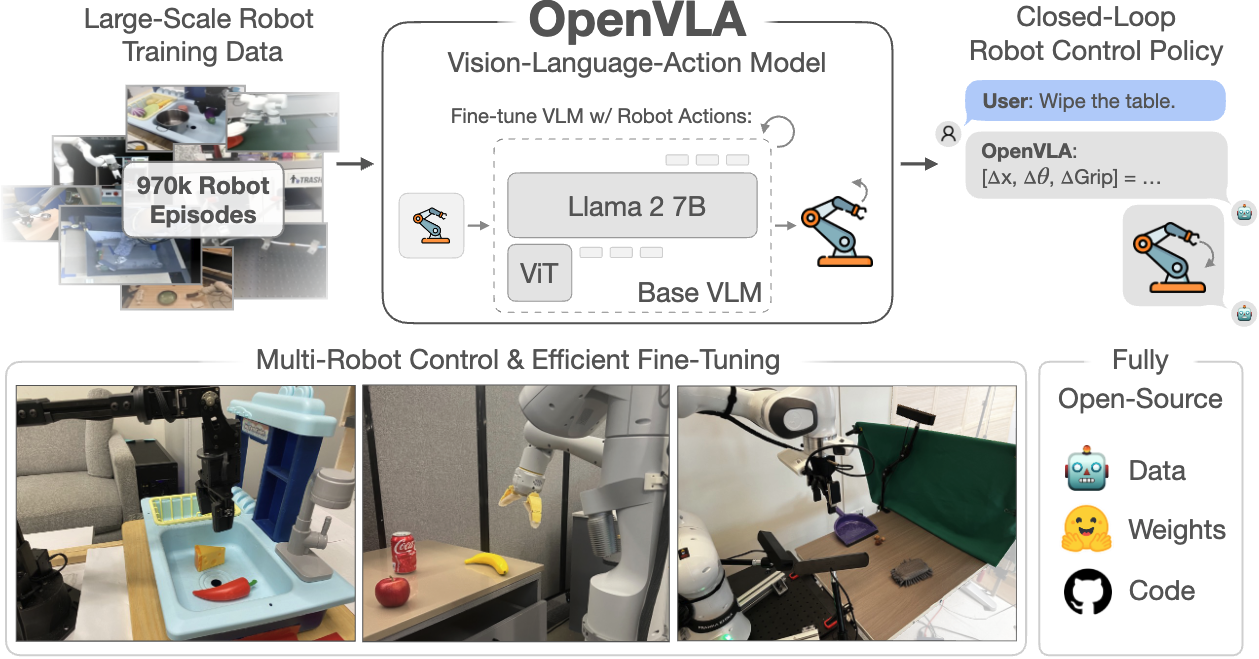
1. 定位与路线对比
OpenVLA 同时把三件过去高度不透明的事情打开了:
- 公开 VLA 的主干架构、训练数据策展和关键超参——
7B参数量级主干,在970k条真实机器人 episode 上训练,在 WidowX 与 Google robot 共29个任务上相对 RT-2-X 有16.5个百分点的绝对成功率提升,参数量约为后者的1/7。 - 把”下游如何微调到新机器人、新任务”作为主问题而不是附带问题来研究。
- 把 LoRA、量化和远程推理服务接进同一个代码库,使它不只是一份 checkpoint,而是一条完整工程链路。
它不是”单靠小模型打赢大模型”,而是用更强的开源 VLM 主干、更大的机器人训练混合、更仔细的数据清洗和更完整的适配链路,第一次把 VLA 做成了可复现的开源工程体系。
下面这张表把 OpenVLA 放回技术坐标系里,方便后文对照。
| 路线 | 典型接口 | 更擅长什么 | 主要短板 | 与 OpenVLA 的关系 |
|---|---|---|---|---|
VLM | 图像 + 文本 -> 文本 | 互联网语义、视觉问答、语言 grounding | 不直接输出机器人动作 | OpenVLA 直接建立在 VLM 主干之上,把动作并入词表 |
Octo | 图像 / 语言 / 异构输入 -> 机器人动作 | 开源通用策略、跨机体训练、下游微调 | 在本文评测里语言 grounding 与复杂干扰场景不如 VLA 强 | OpenVLA 的主要开源对照组 |
RT-2-X | 图像 + 文本 -> 动作 token | 强泛化、强语义先验、VLA 路线标杆 | 闭源,不支持社区微调与复现 | OpenVLA 方法上最接近的前代标杆 |
OpenVLA | 图像 + 文本 -> 动作 token | 开源 VLA、强多任务表现、LoRA/量化/远程推理链路完整 | 单图像输入、吞吐有限、语义泛化并非处处领先 RT-2-X | 本章核心对象 |
Diffusion Policy | 图像历史 / 本体感知 -> 连续动作或动作块 | 窄任务、平滑轨迹、精细控制 | 语言 grounding 较弱,通常需要从头训练 | OpenVLA 下游适配阶段最强的 scratch 基线 |
从这张表可以读出一个更准确的定位:OpenVLA 在方法上更像 RT-2-X,在开放生态上更接近 Octo,而在下游适配阶段又必须和 Diffusion Policy 正面比较。
2. 任务定义与动作接口
OpenVLA 的核心做法并不复杂,但它非常关键:把机器人控制重写成 VLM 已经熟悉的 next-token prediction 问题。
2.1 动作 token 化
设时刻
OpenVLA 先把每一维连续动作分别离散成 256 个 bin:
然后让语言模型自回归地产生这一串动作 token:
训练目标仍然是标准 next-token 交叉熵,但只在动作 token 上计算损失:
整个链路可以压缩成一句话:
图像 + 语言指令 -> VLM 主干 -> 7 个离散动作 token -> 反量化回连续控制
它没有重新设计一个专用控制头,而是把动作直接接进 VLM 已经成熟的序列建模接口里。
2.2 分位数分箱
OpenVLA 沿用了 RT-2 的“每维 256 bins”思路,但把区间边界从 min-max 改成了 1% 到 99% 分位数。对第
论文直接给出的理由是:这样可以忽略长尾异常动作,避免极端值把离散区间拉得过宽,从而降低有效分辨率。
解释性补充(非论文直接结论):在跨数据集混合训练里,动作分布往往带长尾,因此分位数分箱更像是在为主体分布保留分辨率。
2.3 词表接入
这里有一个很容易被忽略的工程细节。Llama tokenizer 预留给微调新增 token 的 special token 只有 100 个,不够容纳 256 个动作 token。OpenVLA 没有扩词表,而是直接覆写了词表里最不常用的 256 个 token。
这么做有三个直接好处:
- 不需要改 embedding 矩阵尺寸。
- 不需要改语言模型输出头的形状。
- 对现有训练与推理代码侵入最小。
这正是 OpenVLA 的工程风格:不是追求最优雅的理论改造,而是优先选择能直接落到已有 LLM/VLM 基础设施上的实现。
2.4 工程价值
把动作写成 token 序列之后,OpenVLA 可以直接继承 LLM 生态的训练范式、LoRA 微调、量化推理和远程服务能力。它的价值不只在模型本身,还在于证明了”机器人动作也能进入通用序列建模工具链”。
3. 数据与训练配方
OpenVLA 的训练数据不是“OpenX 全量直接丢进去”。论文把“OpenX 仓库规模”和“OpenVLA 最终训练混合”区分得非常明确,这一点必须先看清。
3.1 训练混合
Open X-Embodiment 仓库包含 70+ 个数据集、2M+ 条轨迹,而 OpenVLA 实际用于训练的是策展后的 970k 条 episode——并非均匀采样。Fractal、Kuka、Bridge 各占约 12%-13%,BC-Z 和 FMB 也占到 7% 左右。OpenVLA 的成功不是”把所有数据一视同仁地堆起来”,而是带有明确权重设计的数据工程结果。
3.2 关键训练结论
为了保证输入输出空间足够一致,作者先做了两条硬过滤:
- 只保留至少有一个第三人称相机视角的 manipulation 数据。
- 只保留单臂末端执行器控制的数据。
在此基础上,OpenVLA 沿用了 Octo 的数据混合启发式权重。其直觉很直接:降低任务和场景多样性低的数据集权重,提高多样性更高的数据集权重,使训练混合在机体、任务和场景分布上更平衡。
这也是 OpenVLA 和“纯堆数据”之间的重要差别。作者并没有假设所有机器人数据天然兼容,而是明确承认跨数据源训练必须靠数据策展来减少接口不一致与分布偏置。
在此基础上,作者又给出了几条很像工程总结的结论。
OpenVLA 并没有机械地沿用 Octo 当时的混合表。一个最典型的案例就是 DROID:
- 先以保守的
10%权重加入训练混合。 - 训练过程中发现 DROID 上的 action token accuracy 长期偏低。
- 为避免拖累最终模型质量,在训练最后三分之一把 DROID 移除,并把其权重重新分配给其他数据源。
这说明在 VLA 训练里,数据量并不自动等于有效信号。如果模型容量、任务定义或分布匹配度不足,再大的数据源也可能先变成噪声。
另外还有三条关键结论:
- 把分辨率从
224x224提到384x384没带来明显收益,但训练时间增加约3x。 - 学习率 sweep 后,固定
2e-5最好,且没有观察到 warmup 的显著收益。 - 相比常见 VLM 的
1-2个 epoch,VLA 需要反复遍历训练数据;作者直到 action token accuracy 超过95%才认为模型基本收敛,最终训练约27个 epoch。
训练预算也印证了这条路线的成本边界:最终模型使用 64 张 A100 训练 14 天,总计约 21,500 A100-hours。
这里可以把 action token accuracy 看成作者用于判断“动作接口是否基本学稳”的代理指标。它不等于真实机器人表现,但在离散动作 VLA 里明显更有参考价值。
4. 架构与关键证据
OpenVLA 的架构本身并不神秘,但作者在“小规模试验先做选择,再启动大训练”这件事上非常克制。它不是先定死一个模型再赌算力,而是先用 BridgeData V2 做多轮设计决策探索。
4.1 模型架构
OpenVLA 建立在 Prismatic-7B 上。其核心可以压缩成三段:
- 视觉编码器:SigLIP 与 DinoV2 并行抽取特征,并在通道维拼接。
- Projector:一个两层 MLP,把视觉特征映射到语言 embedding 空间。
- LLM 主干:Llama 2 7B,负责接收视觉 token 与文本 token,并生成动作 token 序列。
读图重点:不是只看“用了哪些 backbone”,而是看两路视觉特征如何在进入 LLM 之前完成融合。
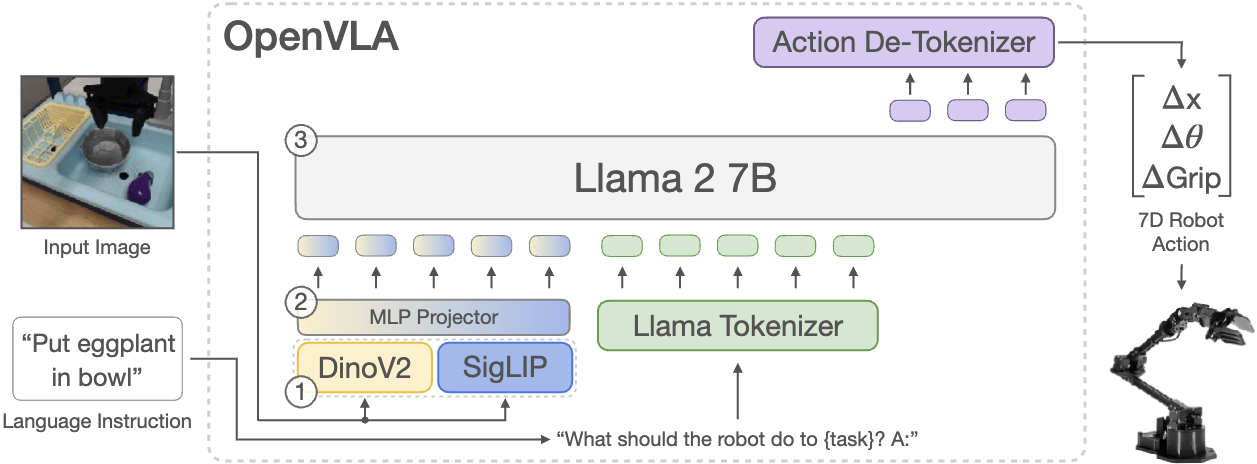
这条设计延续了现代 VLM 的 patch-as-token 路线,使机器人控制可以直接站在开源 VLM 的肩膀上扩展。
4.2 为什么选 Prismatic
作者在 BridgeData V2 的小规模实验里先比较了多个开源 VLM 主干,包括 IDEFICS-1、LLaVA 和 Prismatic。
论文直接给出的观察是:
- 在单物体任务上,LLaVA 和 IDEFICS-1 接近。
- 在多物体、需要语言 grounding 的任务上,LLaVA 相比 IDEFICS-1 平均提升约
35个百分点的绝对成功率。 - 基于 Prismatic 的策略又比 LLaVA 再高约
10个百分点,覆盖单物体和多物体任务。
作者把这部分增益归因于 Prismatic 的融合视觉主干,并补充指出其代码库本身也更模块化、易用。
4.3 关键消融
OpenVLA 最值得反复看的部分,不是单一结论,而是作者给出的几组直接证据。把这些证据压成一张表,会比单独背结论更有用。
| 设计决策 | 论文证据 | 工程含义 |
|---|---|---|
| 使用 OpenX 预训练混合,而不是只训 Bridge | OpenVLA 在 8 个 Bridge 代表任务上 76.3%,OpenVLA-Bridge 只有 45.6%,绝对下降 30.7 个点 | 多机体、多场景、多任务的机器人预训练是主收益来源,不是可有可无的前菜 |
| 使用 SigLIP + DinoV2 双视觉编码器,而不是 SigLIP-only | OpenVLA-Bridge 为 45.6%,OpenVLA-Bridge-SigLIP 为 40.6%,约下降 5 个点 | 空间细节特征确实有用,但边际收益明显小于大规模机器人预训练 |
| 训练时解冻视觉编码器,而不是冻结 | 早期 Bridge 实验平均 80.0% vs 46.7% | VLA 需要把视觉 backbone 调到机器人场景,不能完全照搬 VLM 里的“冻结视觉更稳”经验 |
选 224x224,而不是更高分辨率 | 384px 性能无明显增益,训练约慢 3x | OpenVLA 更看重吞吐与上下文长度,而不是机械追高分辨率 |
固定 2e-5,无 warmup,长轮次训练 | sweep 后最优;最终训练约 27 个 epoch,直到 action token accuracy 超过 95% | VLA 的有效训练节奏和常规 LLM/VLM 不完全相同,更依赖动作拟合充分度 |
如果把收益来源按优先级排序,论文证据更支持”机器人预训练数据多样性 > 视觉主干细节增强 > 更高分辨率”。
需要保留的边界是:这些消融并非完全正交——OpenX 预训练消融在全量模型上完成,双编码器消融在 Bridge-only 训练下完成。因此表中数字更适合读”方向与优先级”,而不应机械理解为完全可叠加的独立增益。
5. 评测与结果
OpenVLA 的结果图很显眼,但如果不先读懂评测设置,就很容易把图里的结论读过头。尤其是 BridgeData V2 这组评测,它不仅是“17 个任务”,而是被明确拆成多种泛化维度,并且部分任务允许 partial success 记分。
读图重点:下面这张任务图更适合用来理解“哪些任务被算作 visual / motion / physical / semantic / language grounding”,而不是直接当结果图看。

5.1 Bridge 与 Google robot
| 平台 | 任务构成 | 试次与记分 | 读结论时的重点 |
|---|---|---|---|
BridgeData V2 WidowX | 5 个 visual、2 个 motion、3 个 physical、4 个 semantic、3 个 language grounding,共 17 个任务 | 每任务 10 次,共 170 rollouts;部分任务允许 0.5 partial success | 重点看不同泛化类别的差异,而不是只看总平均 |
Google robot | 5 个 in-distribution、7 个 OOD,共 12 个任务 | 每任务 5 次,共 60 rollouts;二值成功 | 重点看与 RT-2-X 的可比性,以及 OOD 泛化是否稳住 |
论文还明确说明,这些评测采用 A/B 对照方式:不同方法在相同任务、相同初始机器人状态和物体状态上比较,以尽量保证公平性。
5.2 结果的边界
BridgeData V2 的任务设计本身就很值得读,因为它告诉读者作者想考什么能力。例如:
Put Eggplant into Pot (w/ Clutter)这类 visual generalization 任务,会在机器人朝正确目标靠近时给0.5分。Lift Eggplant这类 motion generalization 任务,在只是接触到目标但未完成抓取时也可能给0.5分。- language grounding 任务会固定初始状态,只改变 prompt,看模型是否真的能找对目标。
这意味着 Bridge 的平均成功率并不只是“做没做成”,而是同时编码了目标选择、动作方向和最终完成度。
论文在附录里反复强调,Bridge 和 Google robot 的测试环境都存在分布偏移——评测无法完全复现原始数据集的物体、背景和摆放,且 OpenVLA 的评测甚至故意设置了比部分旧工作更强的泛化压力。因此,读结果时更应该问”模型在带有真实偏移的环境里还能保留多少语言 grounding 和控制鲁棒性”。
5.3 直接评估
先看 BridgeData V2 总结果。
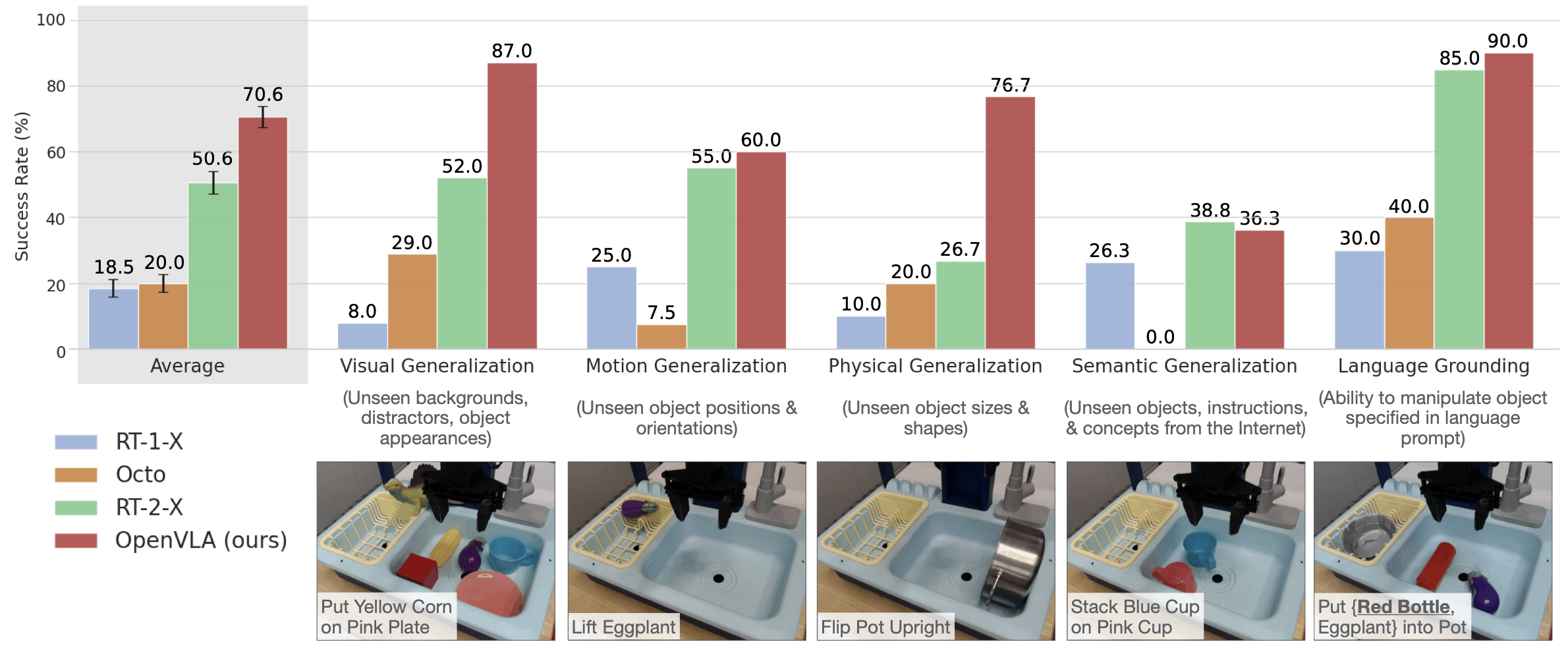
附录详细表格给出的平均成功率是:
RT-1-X:18.5 ± 2.7%Octo:20.0 ± 2.6%RT-2-X:50.6 ± 3.5%OpenVLA:70.6 ± 3.2%
再看 Google robot。
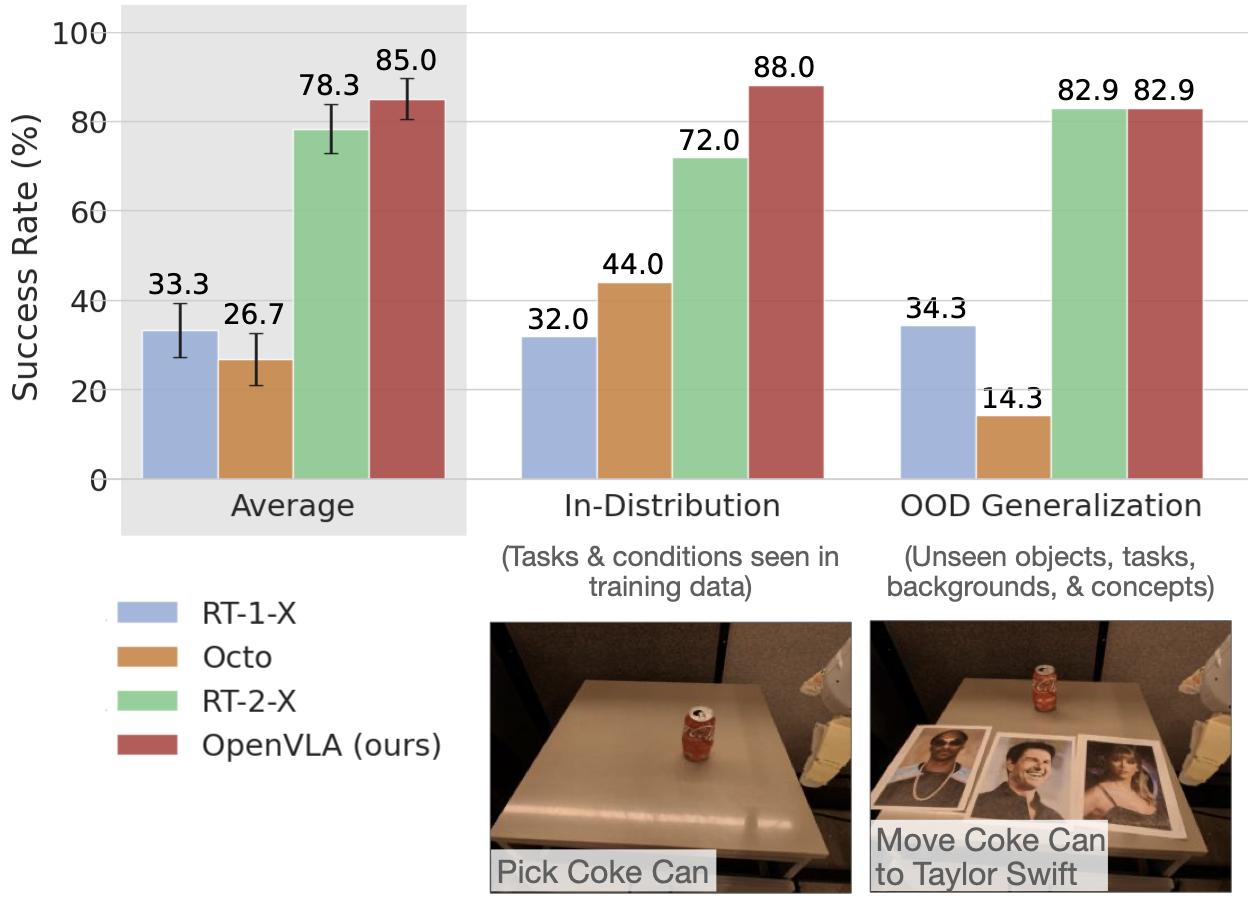
附录表格给出的 Google robot 平均成功率是:
RT-1-X:33.3 ± 6.1%Octo:26.7 ± 5.8%RT-2-X:78.3 ± 5.4%OpenVLA:85.0 ± 4.6%
论文直接给出的结论是:
- OpenVLA 在 BridgeData V2 的大多数类别上优于 RT-2-X。
- 在 Google robot 上,OpenVLA 与 RT-2-X 结果可比。
- 在 semantic generalization 上,RT-2-X 仍然更强——论文指出 RT-2-X 使用了更大规模的互联网预训练并与互联网数据共同微调,而 OpenVLA 只在机器人数据上 fine-tune。OpenVLA 的优势更多体现在机器人控制鲁棒性和多样化数据带来的泛化收益上。
5.4 下游适配
OpenVLA 论文真正比很多前代工作更实用的地方,是它没有停在“开箱即用评测”,而是认真研究了如何适配到新机器人。
读图重点:先看任务构成,再看结果图。Franka-Tabletop 的前半部分是单指令窄任务,后半部分才是多对象、多指令、强语言 grounding 任务。

在设置上,作者用 10-150 条 demonstration 做真实机器人微调,覆盖两个场景:
Franka-Tabletop:5Hz 非阻塞控制,包含 6 个桌面任务。Franka-DROID:15Hz 非阻塞控制,包含Wipe Table一类更动态的桌面清理任务。
这里的比较对象很有代表性:
Diffusion Policy:从头训练的强模仿学习基线。Diffusion Policy (matched):把输入输出规格对齐到 OpenVLA,去掉其原本的一些优势设置。Octo:可微调的开源通用策略基线。OpenVLA (scratch):直接从基础 Prismatic VLM 微调,不用 OpenX 机器人预训练。OpenVLA:先做 OpenX 预训练,再在目标数据集微调。
结果图如下。
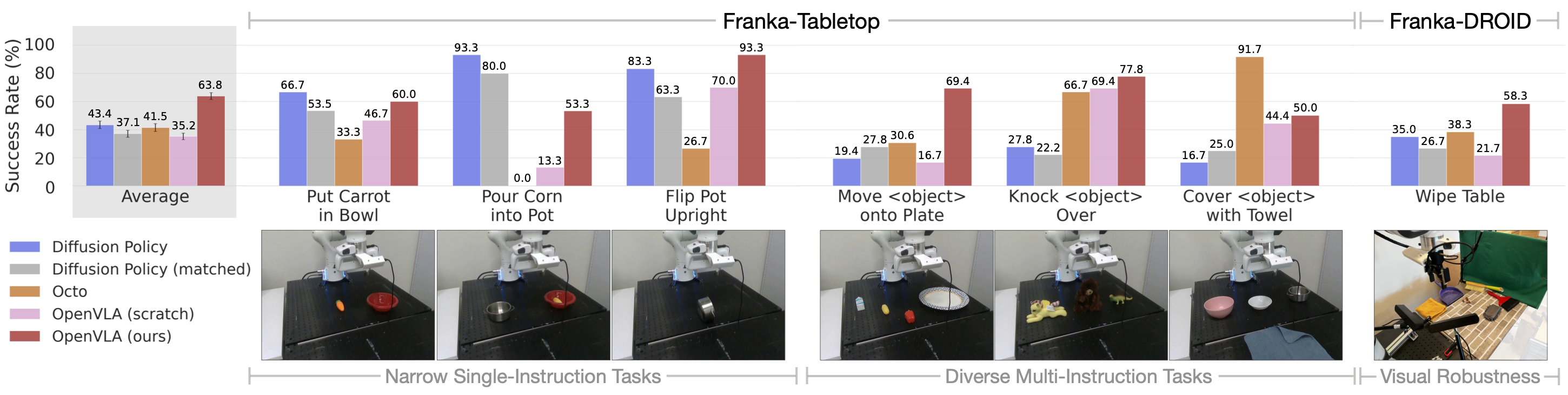
Diffusion Policy 在窄任务、精细轨迹和连续动作生成上更强;OpenVLA 在多物体场景、多指令泛化和语言 grounding 上更稳。
详细表格给出的平均结果也支持这种分工:
- 在
Franka-Tabletop上,OpenVLA平均67.2 ± 4.0%,显著高于Diffusion Policy的48.5 ± 4.9%。 - 在
Franka-DROID上,OpenVLA平均58.3 ± 7.2%,高于Octo的38.3 ± 8.5%与Diffusion Policy的35.0 ± 8.0%。
OpenVLA (scratch) 的存在尤其关键。它说明通用多模态预训练不能直接替代大规模机器人预训练,后者仍然负责把视觉语言表示真正拉进机器人控制分布里。
如果把前面的结果写成教程,有三条边界最好直接写出来。
Bridge评测不是纯二值成功率,且包含明确分布偏移。RT-2-X在 Bridge 对比里存在 API 查询层面的特殊处理。论文附录说明,由于最可能动作常出现 all-zero action,作者最终采用了“始终查询 second-most-likely action”的 workaround。PEFT与量化实验使用的是一个较小的 OpenVLA 变体:更小的机器人预训练混合、且只用 SigLIP 视觉 backbone。因此这些结果最适合读“方法趋势”和“资源换性能的关系”,而不是和最终旗舰模型逐项一一等同。
6. 微调、量化与部署
OpenVLA 的另一层价值,在于作者没有把“能不能在更小资源上适配和部署”留到以后再说,而是在主文里直接把这个问题做成了实验部分。
6.1 LoRA
参数高效微调实验比较了 full fine-tune、last layer only、frozen vision、sandwich fine-tuning 和 LoRA。
最有代表性的几组数字是:
Full FT:69.7 ± 7.2%,可训练参数约7,188.1M,batch=16 时显存约163.3GB,还需要 FSDP 分到两张 GPU。Frozen vision:47.0 ± 6.9%,效果明显变差。Sandwich:62.1 ± 7.9%,比 frozen 更合理,但仍落后于 full FT。LoRA (r=32):68.2 ± 7.5%,只训练97.6M参数,约是 full FT 的1.4%,显存约59.7GB。
最值得注意的不是 LoRA “略低一点但还能接受”,而是它几乎追平 full FT,同时把训练资源拉回单卡可承受范围。论文给出的建议是默认使用 r=32。
更重要的是,这组实验和前面的视觉解冻结论是互相支撑的:last layer only 和 frozen vision 都不理想,说明下游适配的关键并不只是把语言头调一调,而是要让视觉表示也真正适配目标场景。
6.2 量化
量化实验的价值,在于它把“离线 token accuracy”和“真实机器人系统表现”区分开了。
主文给出的 8 个代表性 Bridge 任务结果是:
bfloat16:71.3 ± 4.8%,显存16.8GBint8:58.1 ± 5.1%,显存10.2GBint4:71.9 ± 4.7%,显存7.0GB
读图重点:下面这张图最重要的不是“哪种精度省显存”,而是“哪种精度能把控制频率维持在更接近数据采集时的闭环节奏”。
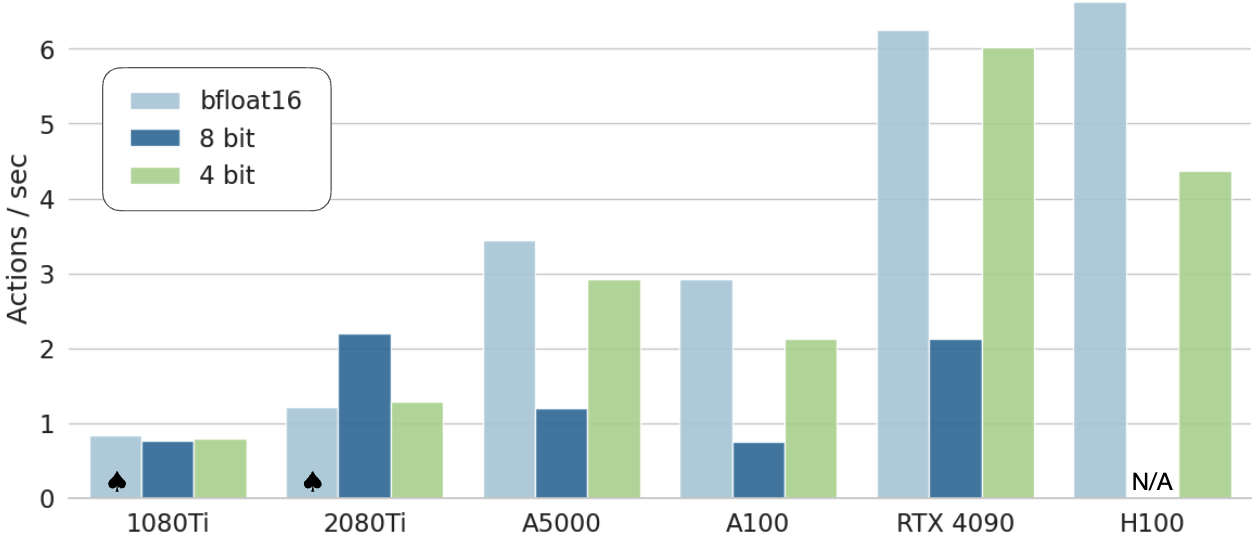
论文给出的关键解释是:
- 在 A5000 上,
int8只能跑到约1.2Hz。 - 同样环境下,
int4约3Hz。 - 而 Bridge 任务的数据采集控制器是
5Hz非阻塞控制。
因此,int8 的性能下降并不主要来自“模型变笨了”,而是来自“系统闭环频率偏离了训练时动力学”。作者在附录里又做了一组 blocking-control 复核:当不同精度都被强制放慢到相近节奏时,bfloat16 / int8 / int4 的平均成功率变成 70.0 / 74.4 / 68.8,误差条互相重叠,支持了“速度失配才是主因”这个解释。
这组实验也说明,在机器人系统里,“量化是否值得”不能只看离线评测或显存数字,还必须一起看控制频率是否仍然落在任务可接受区间。
6.3 推理部署
OpenVLA 还给出了几条和真实部署直接相关的事实:
- 默认
bfloat16推理需要15GB+显存。 - 在未启用额外编译优化时,RTX 4090 上约
6Hz。 - 代码库提供 remote VLA inference server,可以让机器人端远程请求动作。
这让 OpenVLA 的使用门槛明显低于“必须本地有高端 GPU 才能控机器人”的方案,但也清楚暴露出其吞吐上限。论文讨论部分直接指出,像 ALOHA 这类 50Hz 控制系统,当前 OpenVLA 还远远不够快。
7. 代码库、局限与展望
OpenVLA 开源的不只是模型权重,而是一条比较完整的 VLA 研发链路:
OpenX 数据 -> VLA 训练 -> 下游微调 -> 量化部署 -> 远程推理服务
后续研究者要改骨干、换数据混合、尝试新的微调方法或新的部署路径,都不再需要从零搭一套 VLA 工程基础设施。边界同样要保留:OpenVLA 依然建立在 SigLIP、DinoV2、Llama 2 这些外部预训练组件之上,它是”VLA 工程链路开源”,而不是”所有底层预训练数据和训练过程都完全开源”。
但论文自己的讨论部分并不支持”开源 VLA 已经成熟”这种过强表述。作者明确指出了几类限制:
- 目前只支持单张图像输入,不支持多视角、本体感知或显式历史状态。
- 当前吞吐还不足以覆盖
50Hz一类高频控制场景,因此更灵巧、双臂、强闭环任务还很难直接接上。 - 测试任务上的成功率通常仍低于
90%,更适合作为强基线和研究平台,而不是生产级可靠系统。 - 更大 VLM、互联网数据共训、最优视觉特征等关键设计问题仍未系统回答。
作者在讨论里还提到两个可能方向:action chunking 和 speculative decoding。
把 OpenVLA 压缩成四句话:
- 它把 RT-2 之后仍然高度闭源的 VLA 路线,第一次整理成了可复现、可微调、可部署的开源工程链路。
- 论文最有价值的结论不是”7B 打赢 55B”本身,而是揭示了收益优先级:大规模机器人预训练数据混合最关键,其次是能服务机器人细粒度控制的视觉与训练配方。
- 在下游适配阶段,OpenVLA 更像”多任务、多物体、强语言 grounding”的默认起点;而在窄任务、强平滑、强高频连续控制场景,Diffusion Policy 一类方法依然更自然。
- 它也清楚暴露了第一代离散动作 VLA 的上限:输入形态单一、吞吐不足、高频闭环不够稳。
这正好把下一讲 ACT 的动机铺出来。当前一章看到 OpenVLA 在”单步动作 token + 自回归输出”下已经很强,下一步自然要问:如果任务更强调时间连续性、更高控制频率和更平滑的动作轨迹,是否需要一种比单步离散 token 更贴近控制动力学的表示方式?ACT 和 action chunking 就是在回答这个问题。