12. pi0.6:在线闭环与优势策略
先修建议
- 已完成第 9 讲
π₀,理解VLM + Flow Matching Action Expert基础骨架。 - 已完成第 10 讲
π₀.5,理解“高层子任务文本 -> 低层动作”分层执行。 - 已完成第 11 讲
RTC,理解 action chunk 在高延迟下的异步执行机制。
本节目标
- 理解
Recap如何把部署数据转成可训练的优势监督信号。 - 对齐
π₀.6的模型构型、价值函数训练与优势条件策略提取公式。 - 看懂“采集 -> 估值 -> 提取 -> 重置”在线迭代闭环。
- 建立从
π₀到π₀.7的连续能力阶梯。
| 章节 | 解决的核心问题 |
|---|---|
π₀(第 9 讲) | 跨机体基础骨架如何建立 |
π₀.5(第 10 讲) | 开放世界场景中的分层执行如何落地 |
RTC(第 11 讲) | 慢模型如何接入实时控制闭环 |
π₀.6(第 12 讲) | 部署后如何利用经验持续改进 |
π₀.7(第 13 讲) | 如何可控地组合和指挥新技能 |
1. pi0.6 定位
继承自 RTC 的实时执行能力,本节新增的问题是“执行结果如何反向进入训练”,并引向后续章节中的可控技能组合。
π₀.6 的核心变化不是再换一套动作头,而是给 VLA 增加一条部署后可循环的学习回路:
- 在真实任务中运行当前策略,收集自主轨迹与人类纠正轨迹。
- 用任务结果训练价值函数,估计动作优劣。
- 把优劣信号变成策略条件,重新训练下一轮策略。
读图重点:看三段闭环是否齐全,而不只看“模型规模变大”。

这一步解决的是前十一讲共通的一个限制:训练结束后模型参数基本冻结。π₀.6 把“部署中的成功与失败”变成下一轮训练的监督信号,使策略能在目标场景持续提升吞吐与稳定性。
2. 任务定义与符号约定
继承自 π₀.5 的分层执行语义,本节补齐 π₀.6 在线学习所需的 RL 数学对象。
论文主文把轨迹写为:
并使用(未加折扣的)回报定义:
策略目标是最大化:
值函数与优势可写为:
| 符号 | 含义 |
|---|---|
| 时刻 | |
| 时刻 | |
| 当前参考策略下的状态价值 | |
| 动作相对状态基线的改进量 | |
| 优势二值指示器(正/负) | |
| 任务相关的优势阈值 |
3. 奖励设计与数据组成
继承 π₀.5 的真实部署任务语境,本节新增“如何把执行结果映射为统一奖励监督”。
论文采用通用稀疏奖励:
这一定义让价值函数学习“离成功还剩多少步”,并把失败轨迹压到更低值区。实现中把价值按任务最大长度归一化到
数据组成是三类混合:
- 示教数据(demonstrations)。
- 自主执行数据(autonomous rollouts)。
- 人类纠正数据(expert interventions)。
不同任务每轮数据量并不统一,典型示例包括:
- T-shirt/shorts 任务:每轮约 300 条自主轨迹(4 台机器人)。
- Box assembly:每轮约 600 条自主 + 360 条纠正(3 台机器人)。
- Cafe:单轮约 414 条自主 + 429 条纠正。
因此,“600+360”应理解为特定任务设置,不是所有任务的统一单轮配额。
4. 模型构型:从 pi0 到 pi0.6
相对 π₀.5,本节变化重点是“优势条件 + 价值函数并行”,而不是重建主干架构。
π₀.6 的策略模型沿用 π₀ 系列骨架,并在三处增强:
- VLM 主干升级为 Gemma 3 4B。
- 动作专家扩展到 860M 参数。
- 在输入序列中增加优势指示器文本(正/负/空条件)。
与策略并行训练的是独立价值函数网络,采用 670M VLM backbone。策略与价值函数不共享参数更新。
读图重点:看策略分支与价值分支如何分工,而非只比较参数规模。
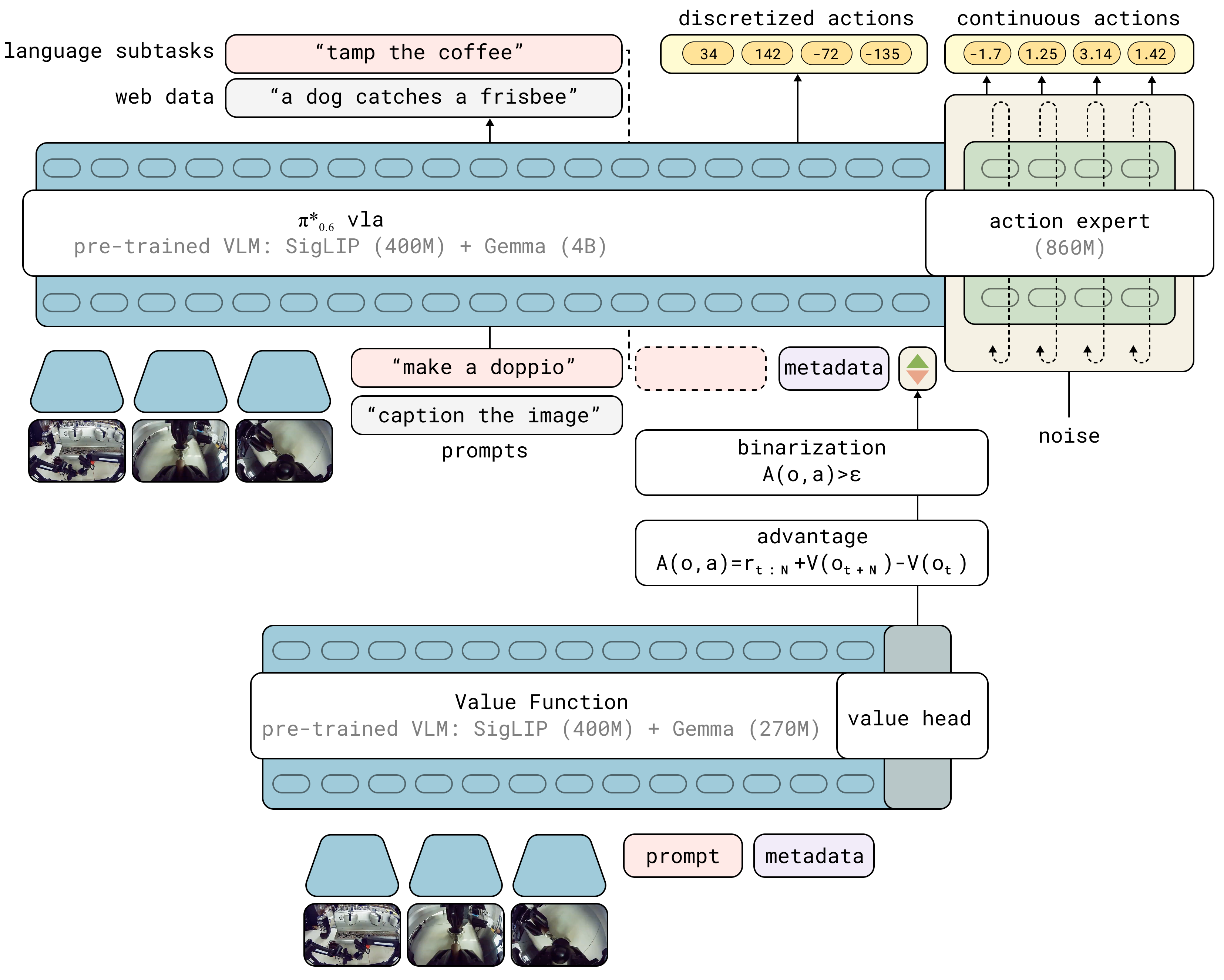
优势指示器的注入位置也很关键:它以文本 token 形式出现于 rawtext 之后、动作输出之前,因此主要调制动作相关 likelihood,而不改任务提示本身的语义输入结构。
5. 分布式价值函数训练
RTC 解决的是“动作连续执行正确性”,本节回答“执行结果如何变成稳定价值监督”。
论文使用多任务分布式价值函数:
核心训练目标是“离散化 empirical return + 交叉熵”:
其中
训练完成后,再由分布恢复连续值:
读图重点:看成功轨迹与失败轨迹中价值重心随时间的变化趋势。

说明:本节可与 C51 等分布式价值方法做背景类比,但 π₀.6 主文实现口径是“离散回报监督 + 交叉熵”,不应误写成投影贝尔曼主路径。
6. 优势条件策略提取(为何不用 PPO 主路径)
本节与 RTC 属于正交层:RTC 解决实时执行,本节解决策略更新方式。
有了价值函数后,Recap 不直接走常规 on-policy PPO 主路径,而采用优势条件策略提取。先定义二值指示器:
策略优化目标为:
其中关键实践细节包括:
- 人类纠正动作强制设为
。 - 训练时随机 dropout 指示器(30%),以支持有条件/无条件双分布建模。
- 推理可用 CFG 进行条件锐化,但过高
可能导致动作过激,论文建议中等区间(如 )。
为什么不把 PPO 作为主路径:
- Flow Matching 模型不直接提供易用的显式 log-likelihood。
- 大模型离线/混合数据训练场景下,传统 on-policy 约束更难稳定扩展。
- 论文实证中,优势条件提取在 throughput 上显著优于对比的 PPO/AWR 方案。
7. 在线闭环:采集、估值、提取、重置
承接 π₀.5 的部署场景与 RTC 的实时执行机制,本节补齐“部署后如何迭代更新”。
π₀.6 的单轮迭代可写为三步:
- 数据采集:运行当前策略,收集自主轨迹与可选人类纠正。
- 价值更新:在累积数据上训练价值函数,重新估计优势并生成
。 - 策略提取:用更新后的
重新训练策略。
其中一个稳定性关键是:策略与价值函数每轮都从 pre-trained checkpoint 初始化,而不是在上一轮权重上直接续训,用于降低多轮分布漂移风险。
训练流程还包含一个初始化阶段:先在任务示教数据上做 SFT(此时固定
8. 实验结果与能力边界
相较 π₀.5 的“开放世界可执行”证据,本节关注“是否可通过在线迭代持续变强”。
论文评测任务覆盖 laundry、espresso、box assembly,单任务时长通常在 5-15 分钟区间。核心指标:
- throughput:每小时成功任务数(同时衡量速度与成功)。
- success rate:人工标注成功率。
读图重点:先看任务覆盖,再看每类任务的吞吐增益。

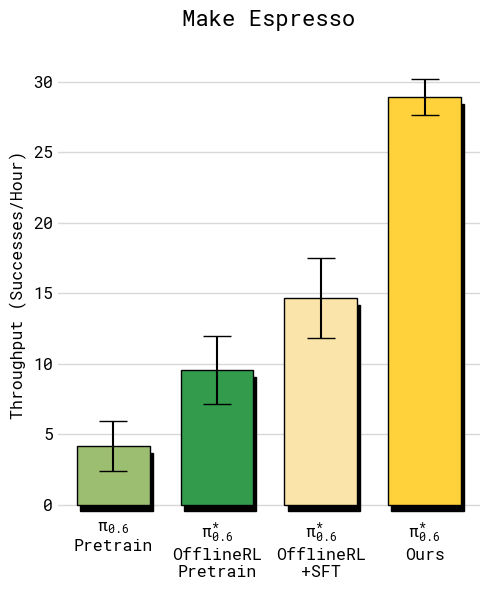
主结果可概括为:
- 在更难任务上,最终模型 throughput 可超过 2x。
- 失败率在对应对比下约下降到原来的 1/2 量级。
- 多轮迭代可继续提升,且对 failure mode removal 有明显作用(特定任务可达 97% 成功率)。
- 部署鲁棒性示例包括:咖啡任务连续运行 13 小时、陌生家庭洗衣折叠运行超过 2 小时。
边界说明:这些结果成立于论文给定任务集合、评价协议和数据采集流程下,不应外推为任意任务都等幅提升。
9. 局限与下一讲过渡
π₀.6 解决了“会学习”的问题,但还没有解决“学习过程完全自治”和“可控技能组合”两类挑战。
论文 Discussion 明确的限制包括:
- 系统仍依赖人工参与(奖励标注、纠正、场景复位)。
- 探索策略偏朴素,主要依赖策略随机性与人工纠偏。
- 当前是迭代离线更新流程,而非并发实时在线 RL。
因此,π₀.6 更准确的定位是“把 VLA 从一次性训练推进到可迭代自改进”,而不是最终形态。下一讲 π₀.7 将继续沿这条路线,重点转向“如何被指挥地组合已有能力,完成未演示任务”。