3. RT-1 架构与关键取舍
先修建议
- 理解行为克隆(Behavior Cloning)与负对数似然训练目标。
- 熟悉离散化动作与分类损失的基本关系。
- 了解控制频率、推理开销与部署稳定性的常见工程约束。
本节目标
- 明确 RT-1 在 VLA 演进中的奠基作用与问题边界。
- 读懂“3 Hz”与“256 bin”两项关键设计背后的工程取舍。
- 建立 RT-1 的数据体系、模型架构与部署约束之间的因果链路。
RT-1 的参数规模与控制频率在今天并不突出,但其关键价值在于验证了“机器人学习可作为序列建模问题统一处理”。RT-2、OpenVLA 与后续基础模型路线都建立在这一前提之上。
1. RT-1 定位
这一讲不按论文原始章节顺序展开,而是围绕两个工程决策组织内容:
为什么控制频率只有 3 Hz?不能更快吗? 为什么每个动作维度恰好量化成 256 个 bin?不能更细吗?
把这两个"为什么"说清楚,RT-1 的数据体系、模型架构、训练流程和部署约束就能连成一条完整链路。阅读时可以先记住导航:第 6 节回答"为什么是 3 Hz",第 7 节回答"为什么是 256 bin"。
先看任务覆盖面:RT-1 不是只会单一抓取,而是覆盖了抓、推、开合等一组可复用技能。

2. 任务定义
作为 VLA 章节里第一个具体模型,RT-1 的核心是先把问题定义清楚:给定语言指令与视觉历史,输出当前时刻的动作分布。
在时刻
一段完整交互可写成 episode:
RT-1 用 imitation learning 里的 behavioral cloning 训练。给定成功示范数据集
这一定义的关键价值是:它把"机器人策略学习"和"序列建模"放进了同一数学框架,后续结构设计都服务于这个目标。
3. 数据体系
RT-1 的第一个贡献不是新损失,而是数据工程。在 2022 年之前,机器人学习数据集通常只有几千条轨迹、几十种物体,很多是为某一种算法定制采集的。RT-1 把顺序反过来:先确立标准化采集协议,再让 13 台 Everyday Robot 在三间办公室厨房里连续工作 17 个月。
下图重点看三件事:采集场景多样性、机体与相机配置、以及物体分布覆盖面。

最终产出是 13 万条轨迹、700+ 条自然语言指令,并按技能动词组织(pick、place、open、close、knock over 等)。每条轨迹绑定完整自然语言描述,例如 "pick rxbar chocolate from middle drawer"。这种以"动词+对象"组织的数据形式,决定了后续模型把语言作为行为条件,而不是单纯的物体标签。
这条数据管线后来也成为 Open X-Embodiment 的重要蓝本之一。
4. 模型架构
RT-1 的架构可以概括为三段:
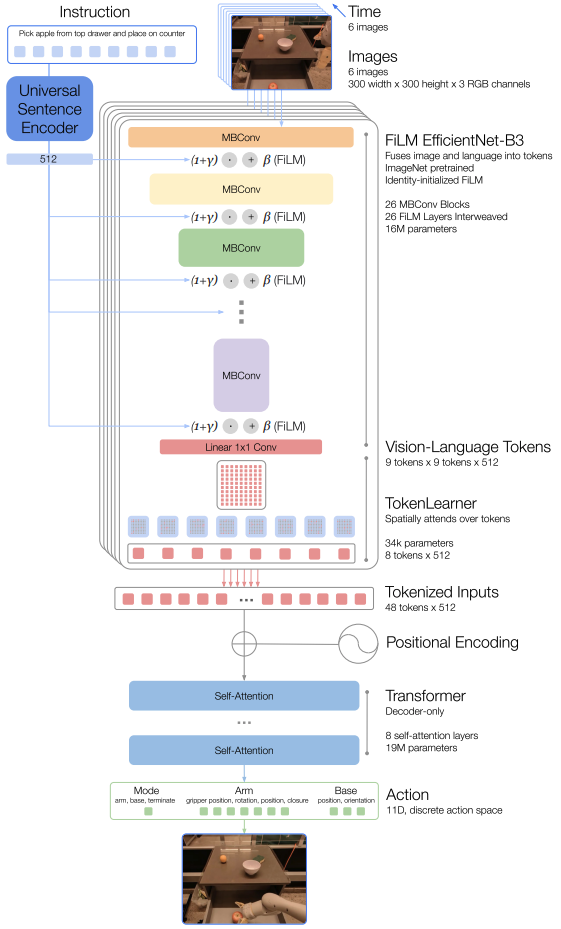
- 语言条件化的视觉编码(FiLM-EfficientNet)
- Token 压缩(TokenLearner)
- Decoder-only Transformer 动作解码
先看 RT-1 的端到端总览图,建立“指令/图像输入到动作输出”的整体信息流。
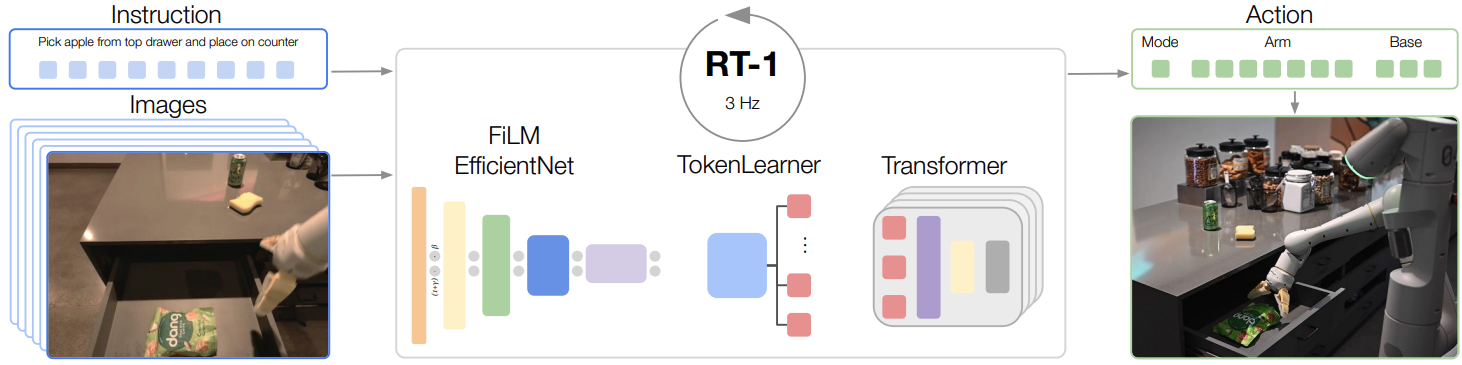
4.1 FiLM 条件化视觉编码
所有后续设计都依赖一个前置问题:一张
最简单的做法是末端拼接语言和视觉特征,但 RT-1 选择更早融合:在视觉主干每一层注入语言条件。这样同一图像在不同指令下可关注不同区域(比如"把苹果递给我"和"把鼠标推开")。
RT-1 使用 FiLM(Feature-wise Linear Modulation):
这里
为什么把
训练初期若满足
这样不会破坏预训练 EfficientNet 的功能,同时允许梯度稳定回传到视觉主干与 FiLM 参数层。
4.2 TokenLearner 压缩
TokenLearner 的核心目标不是“盲目降维”,而是把和当前任务最相关的视觉信息保留下来,再交给 Transformer。它解决的问题是:每帧 81 个 token 太贵,但直接平均池化又会抹掉关键局部细节(比如夹爪和目标物的接触区域)。
可以把它想成“8 个可学习观察员”在看同一帧图像:每个观察员都会生成一张自己的关注热力图,再把自己关注区域的信息汇总成 1 个 token。这样模型不是被动接受固定网格特征,而是主动决定“这一步控制最该看哪里”。
实现上可以按 4 步理解:
- 输入是每帧特征
(由 FiLM-EfficientNet 产生)。 - 一个轻量打分网络为每个输出槽位
生成一张注意力图 。 - 对每个槽位做加权汇聚,得到输出 token
。 - 把若干个
(RT-1 里是 8 个)拼成压缩后的 token 序列送入 Transformer。
这里有两个容易忽略的点:
- 端到端学习:TokenLearner 没有单独的“注意力标签”,而是通过最终动作损失反向传播,自动学出关注区域。
- 槽位自组织分工:8 个输出槽位通常会学到互补角色,有的更偏目标物体,有的更偏夹爪接触区或运动相关背景。
其数学形式是:
关键点在于
从系统角度看,TokenLearner 把序列长度从“每帧 81 个”压到“每帧 8 个”,显著缓解后续自注意力开销。注意力复杂度近似随
理论上序列变短会带来很大收益,但真实系统里还有视觉主干、内存搬运等开销,所以论文实测 TokenLearner 对推理速度的净提升约为 2.4 倍(而不是理论上限)。
对学习者来说,一个实用判断是:平均池化给的是“整图平均语义”,而 TokenLearner 给的是“任务相关语义摘要”。前者更像压缩,后者更像选择。
4.3 Transformer 与动作头
压缩后 6 帧总计 48 token(加位置编码)输入 decoder-only Transformer(8 层)。输出是动作 token,而不是直接回归连续向量。
这一层可以理解为“时序决策器”:
- FiLM + TokenLearner 负责把观测变成紧凑、可读的表示;
- Transformer 负责在时间维与语义维上整合信息,输出当前时刻最合理的动作分布。
为什么“位置编码”在这里很关键?因为 6 帧历史里“第几帧”本身就是控制信号。没有位置编码,模型很难区分“刚刚发生的状态变化”和“更早之前的背景信息”。
动作头把 Transformer 表征映射到动作 token 概率分布(对应各动作维度)。这种设计的工程价值是:训练上可直接使用分类交叉熵,系统上也更容易与后续 VLM 的 token 化范式对齐。
这里的“动作 token”需要做一个术语澄清。RT-1 中的 token 更准确地说是动作离散化后的类别标签:每个动作维度先量化成若干个 bin,模型预测的是“该维度落在哪个 bin”。它和自然语言模型里的词表 token 在监督形式上相似,都是分类问题,但语义上并不是同一类对象。
这也是 RT-1 和 RT-2 最容易混淆的地方。RT-1 已经证明“动作可以 token 化并用分类损失训练”,但这些 token 仍然属于机器人策略内部的结构化动作表示;它们还没有进入通用 VLM 的词表体系。
架构信息流如下。先看流程图建立全局,再看论文原图对齐细节。
5. 训练流程
这一节补全"基础模型怎么训练",把结构图落到可执行训练闭环。
5.1 样本构造
从示范 episode 中,在每个时刻构造训练样本:
- 输入:指令
+ 最近 6 帧图像历史 - 目标:时刻
的动作
RT-1 将动作拆成 11 个维度(7 维机械臂 + 3 维底盘 + 1 维模式切换),每维离散为 256 个 bin,最终得到 11 个动作 token 标签。
5.2 目标函数与掩码
训练时用分类交叉熵。若把每个动作维度离散后的 bin 记为一个 token 标签,则单步损失可以写成:
其中
有些资料会把这一过程写成带 causal mask 的 token 级预测,用来强调 RT-1 采用了 decoder-only Transformer 的序列建模骨架。这种写法对理解“结构兼容性”有帮助,但容易引出另一个误解:仿佛 RT-1 已经像语言模型一样,必须逐个动作 token 自回归生成完整动作串。
更准确的理解是:
- RT-1 的核心是把动作监督改写成离散分类问题;
- 这些 token 是动作 bin 标签,而不是自然语言词表项;
- 论文消融还显示,对动作维度显式做自回归条件化会让推理速度下降约 2 倍以上,最终版本并没有把“LM 式逐 token 生成”作为主要收益来源。
这一步依然非常关键,因为它先把训练信号变成了与语言模型相容的分类形式,后续 RT-2 才能继续把动作 token 接入 VLM 的统一词表与解码接口。
6. 推理控制
机器人部署不只看精度,还看时延与抖动。RT-1 的目标是把策略放进真实控制闭环,而不是离线评测。
6.1 部署时到底是不是 next-token prediction
这里需要把两种“next”严格区分开。
- 若按控制时序理解,RT-1 确实是在每个控制周期预测“下一步动作”;
- 若按语言模型解码理解,RT-1 的部署方式并不是逐个动作 token 自回归生成完整动作串。
实际工程部署更接近下面这条链路:
其中
把这条链路展开,可以理解成 4 个步骤:
- 读取语言指令和最近 6 帧视觉历史。
- 经过一次前向计算,直接得到 11 个动作维度各自的分类分布。
- 为每个维度选出目标 bin,并反量化成连续控制量。
- 将当前动作发给机器人执行,再进入下一控制周期。
因此,RT-1 在部署侧更准确的描述是单步动作分类闭环,而不是 LLM 式的“逐 token 解码”。这一点也和前面的训练目标相呼应:token 在这里是动作 bin 标签,不是要按词表顺序逐个生成的自然语言符号。
论文还专门比较过对动作维度显式做自回归生成的版本。结果表明,这种做法会让推理速度下降约 2 倍以上,而收益并不明显,因此最终部署版本没有采用“动作串逐 token 生成”的方案。
6.2 为什么控制频率只有 3 Hz
论文中的关键工程约束是:为满足约 3 Hz 控制,需要把模型推理预算压到约 100ms 量级(其余时延来自相机、通信等系统环节)。
RT-1 的主要推理加速来自两件事:
- TokenLearner 压缩视觉 token(约 2.4x)
- 滑动窗口特征复用(相邻推理共享历史视觉特征,约 1.7x)
这套组合把端到端闭环推到 3 Hz 可用区间。
3 Hz 能做什么、不能做什么也很直观:
- 能做:推、拉、抓、放、开抽屉、关冰箱(对反应时延容忍较高)
- 难做:插 USB、穿针、拧螺丝、翻薄饼(需要更高频连续微调)
7. 动作表征
7.1 为什么不是连续回归
一个自然想法是直接回归连续动作(MSE)。但在多峰动作分布下,MSE 的最优解是条件均值:
当可行动作存在多个模式(例如从左或从右绕过障碍),均值往往落在"中间无人区",反而是不可行动作。
RT-1 采用每维离散化 + 分类交叉熵,能表达多峰分布,而不是被单峰高斯假设限制。
7.2 为什么是 256 bin
RT-1 的 11 维动作空间包括:
- 手臂 7 维:
+ roll/pitch/yaw + gripper - 底盘 3 维:
- 模式 1 维:arm / base / terminate
以手臂
这个数字本身不是理论最优,而是"分辨率够用 + 工程实现方便"的折中。与连续高斯回归相比,论文消融显示离散动作在泛化与鲁棒性上更稳。
从 VLA 演进视角看,这个设计还有一层更长远的价值:RT-1 先回答了“机器人动作能否稳定离散化并用分类损失学习”,RT-2 则在这个基础上继续回答“这些离散动作能否进一步被纳入 VLM 的词表与 next-token 解码体系”。
8. 局限与演进
RT-1 把机器人策略学习推进到了可扩展序列建模范式,但也留下了明确边界:
- 控制频率与时延预算限制精细操作
- 离散动作在高精度连续控制任务上有上限
- 数据仍以特定机体与场景为主,跨机体迁移难度高
论文消融也给了三条硬证据(方向性):
- 连续动作替代离散动作:性能显著下降
- 动作自回归:推理变慢(约 2x 量级)且收益有限
- 去掉视觉预训练:未见任务泛化明显下降
下图读图重点是"分布扰动下仍能完成任务":背景、光照、干扰物变化后性能下降但不崩溃。

把这一讲压缩成工程视角,可以得到一张四列表:
| 决策 | 直接收益 | 代价/上限 | 后续路线 |
|---|---|---|---|
| 大规模真机数据采集(13 万条) | 首次在真机上验证机器人序列建模可行 | 采集成本高、机体覆盖有限 | Open X-Embodiment 做跨机构扩展 |
| FiLM 逐层语言注入 | 视觉特征从早期就带任务条件,提升指令对齐 | 增加调制参数与训练复杂度 | 被后续多模态条件注入范式继承 |
| TokenLearner 压缩 81→8 | 显著降低注意力开销,使 3 Hz 可用 | 信息压缩存在细节损失 | 促使后续研究关注更高频控制 |
| 动作离散化 + 256 分类 | 训练目标与 LM 对齐,易于扩展到 VLM 词表 | 精细连续控制受量化限制 | Diffusion Policy / |
回过头看 RT-1 的贡献可以压缩成三句话:第一,它给出了机器人学习走向规模化训练的早期实证证据;第二,它确立了"序列建模 = 机器人学习"这个框架;第三,它把"动作 token 化"沉淀成了可复用基线。
读到下一讲之前,记住一件事:RT-1 把机器人学习接到了 language modeling 这条主线上。RT-2 要回答的第一个问题就是:能不能直接拿一个 VLM 来做 RT-1 的工作?