4. RT-2 语义迁移与联合微调
先修建议
- 已完成 RT-1 章节,理解动作 token 化与行为克隆训练框架。
- 熟悉 VLM 预训练与微调的基本流程。
- 了解“语义泛化”与“动作技能库”在机器人任务中的区别。
本节目标
- 说明 RT-2 的核心增量为何是“语义迁移到控制”。
- 读懂动作-语言统一 token 表示与联合微调机制。
- 区分 RT-2 的已验证收益与能力边界,避免过度外推。
RT-2 常被概括为“把动作也当 token”,但该表述不足以解释其真实贡献。本章按“现象 -> 机制 -> 训练 -> 边界”展开,重点回答语义迁移为何出现、为何需要 co-fine-tuning、哪些能力提升已有直接证据支持。
1. RT-2 定位
先把 RT-2 放到系列上下文里看。RT-1 的核心是“把机器人控制建成一个统一的行为克隆问题”,重点在动作建模和工程可训练性。RT-2 的核心增量不是“机械臂突然会了新运动学”,而是把大规模 VLM 的语义知识接进策略网络,让模型在未见语义任务上更有迁移能力。
换句话说,RT-2 解决的是这个问题:
同样的机器人动作库,能不能因为“理解能力变强”,在新指令上做出更合理的动作选择?
你可以把两代模型先粗看成下面这个关系:
| 模型 | 主要增量 | 直接收益 |
|---|---|---|
| RT-1 | 统一动作 token 化与训练流程 | 机器人控制可规模化训练 |
| RT-2 | 复用预训练 VLM + 联合微调 | 未见语义任务迁移显著增强 |
这也是后面读所有细节的主线:RT-2 的核心贡献是“语义迁移到控制”,不是“新运动技能凭空生成”。
1.1 先把 RT-1 和 RT-2 的 token 区分开
这一点值得在进入细节前单独说明,因为它直接决定后文应该如何理解“动作也是 token”这句话。
| 维度 | RT-1 | RT-2 |
|---|---|---|
| token 的直接含义 | 动作离散 bin 的类别标签 | VLM 词表中的 token,被映射为动作 bin |
| 是否与语言共享词表 | 否 | 是 |
| 训练接口 | 机器人策略内部的结构化动作预测 | 统一 next-token 解码接口 |
| 核心收益 | 动作学习可离散化、可扩展 | 语义知识可更直接流向动作输出 |
因此,更精确的表述不是“RT-2 发明了动作 token”,而是:
- RT-1 先证明了动作可以离散成 token 标签来学习;
- RT-2 再把这些离散动作接入 VLM 的词表与解码体系。
两者在动作语义层面并非完全断裂。RT-2 大体沿用了 RT-1 的动作离散化思路,但改变了这些 token 所处的“宿主系统”:从策略网络内部标签,变成了 VLM 可以直接生成的输出 token。
2. 核心现象
论文里最抓人的地方是几组“没教过却能做”的任务:
- 把草莓放进水果碗而不是空碗。
- 把苹果放到打印着数字 3 的纸上。
- 捡起“快要掉下桌子”的袋子。
- 找“临时锤子”时选择石头。
这些任务的共同点是:训练演示里没有逐条覆盖这样的具体场景,但任务成功需要识别语义、理解关系,再把语义映射到已有动作技能上。
读图时先看任务类型,不先看细节动作:

这张图主要证明的是“语义类别上的迁移存在”,比如符号理解、关系判断和人相关识别。它没有证明的是“所有复杂任务都稳定成功”。
再看量化图:
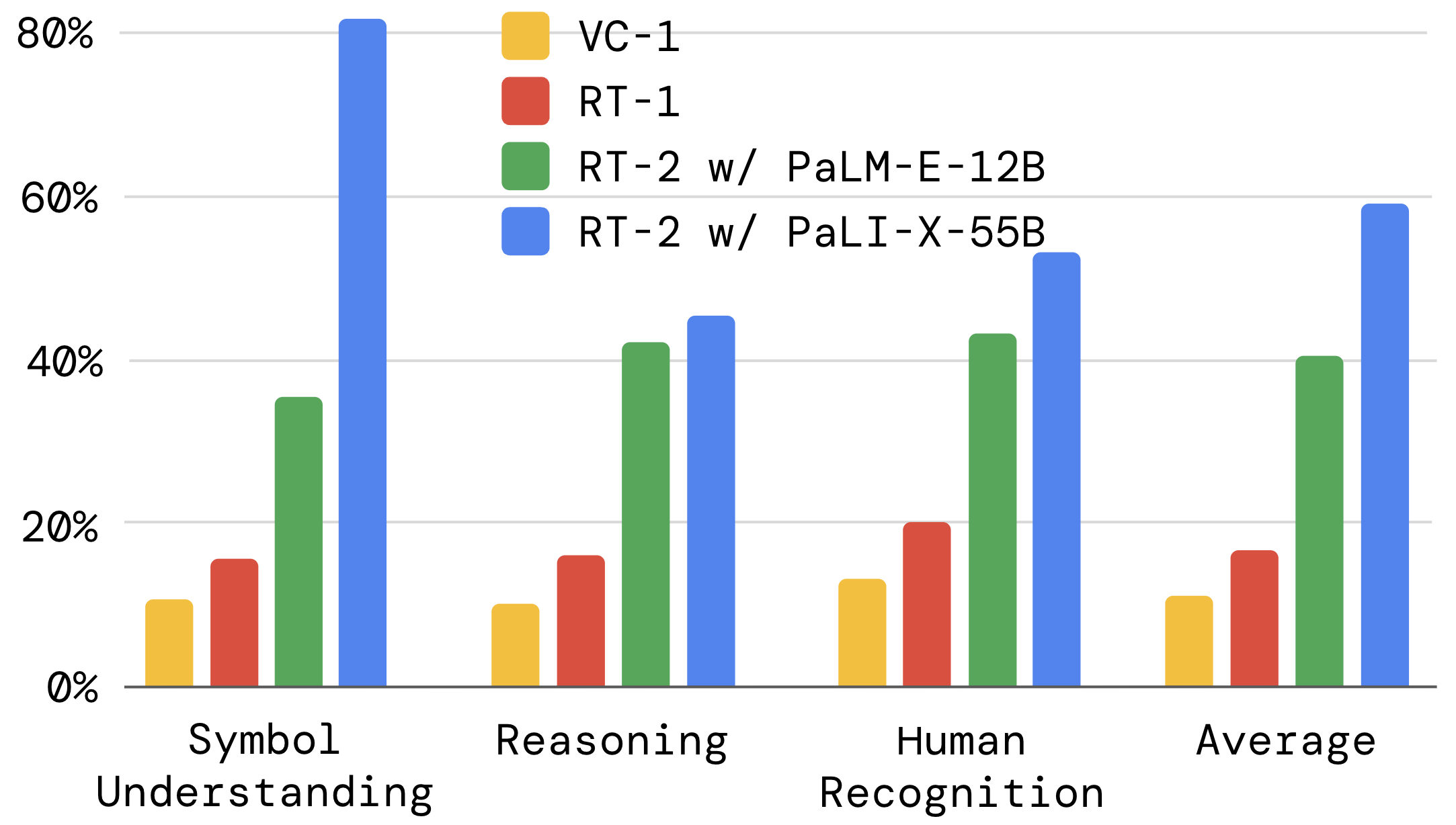
这里最应该关注的是相对差距:在这三类 unseen 语义任务里,RT-2 相对 RT-1 的提升很明显。论文报告的对应评估规模约 6k 次真实机器人试验。
这些结果更接近“把语义迁移到已有技能组合”,并不等于“模型自己发明了新动作原语”。RT-2 的机器人数据规模没有出现同量级跃迁,关键变量是底座 VLM 的语义先验。
3. 表示统一
这一节是 RT-2 最核心、也最容易被一句话带过的机制:动作输出和语言输出进入同一个解码框架。
先从动作表示开始。RT-2 不是重新发明一套动作空间,而是沿用 RT-1 已经验证过的“连续动作先离散为 bin”这条路线,再把这些 bin 写入 VLM 的输出接口。一个 6-DoF 机械臂时间步动作用 8 维表示:
| 维度 | 含义 |
|---|---|
| 1 | 终止标志 |
| 2-4 | 末端位移 |
| 5-7 | 末端旋转 |
| 8 | 夹爪开合 |
连续值先离散到 256 个 bin,再写成整数 token 序列。
例如一个动作可以写成:
于是策略目标仍是标准自回归分解:
这条公式的白话是:
“第 k 个动作 token 的预测,依赖图像、文本指令和前面已经生成的动作 token。”
读图时重点看“同一解码器同时服务语言与动作”:
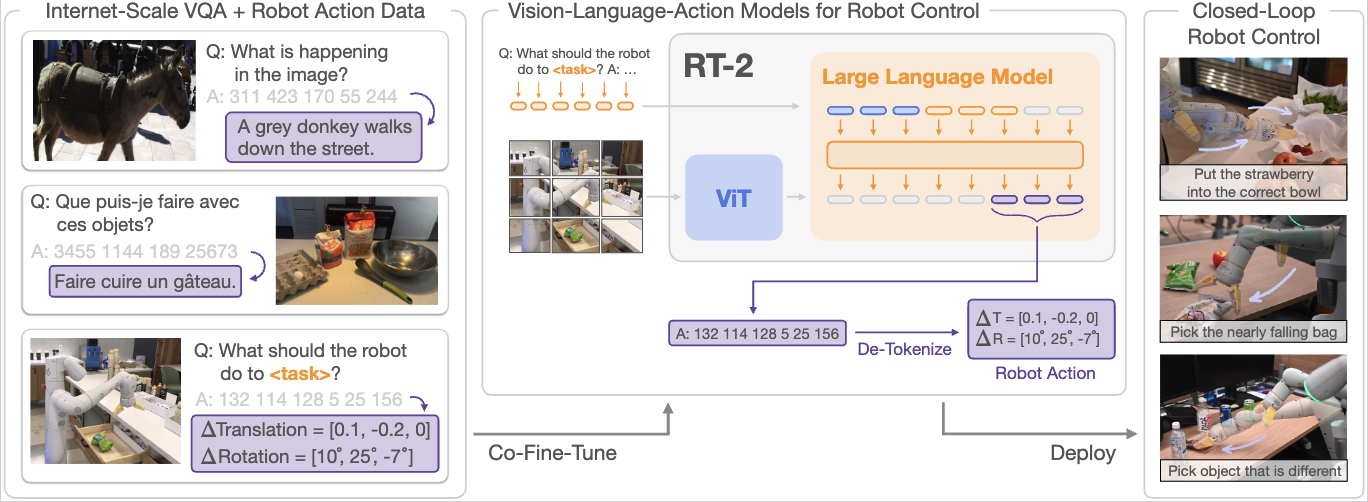
这张图证明的是“任务形式统一”,不代表所有语义都自动变成可执行动作。统一只是前提,训练策略同样关键。
为什么这种表示能真正起作用?因为动作预测不再走一个独立 action head,而是直接复用 VLM 整套解码路径。语义信息不在中间层截断,而是能继续流向输出端。
这里还需要补一句常被忽略的细节:论文里常把动作写成类似 "1 128 91 241 ..." 的字符串,是为了说明“动作可以排成序列并进入标准 tokenizer 接口”。真正关键的不是数字字符本身,而是动作维度对应的离散 bin 能否稳定映射到 VLM 词表 token。
两种底座模型的 token 处理也可以顺手记一下:
PaLI-X:直接使用已有整数 token。PaLM-E:覆写 256 个低频 token 映射 action bin。
因此,RT-2 的动作 token 并不总等价于“文本里看到的十进制数字”。对 PaLI-X 来说,这种对应关系比较直观;对 PaLM-E 来说,动作 token 更接近“被重绑定了新语义的词表项”。这一点也再次说明:RT-2 的创新重点是统一解码接口,而不是把控制问题表面上改写成数字字符串。
3.1 一条样本如何进入训练
把抽象描述落到一个时间步,数据结构大致是:
image: (224, 224, 3)
instruction: "pick up the apple from the table"
action_vector: [1, 0.03, -0.01, 0.02, 0.0, 0.0, 0.15, 1.0]
action_bins: [1, 165, 123, 143, 128, 128, 148, 255]
prefix_tokens: [<BOS>, <img...>, "Q:", ..., "A:"]
target_tokens: ["1", "165", "123", "143", "128", "128", "148", "255", <EOS>]
loss: -Σ_k log p(target_k | prefix, target_<k>)
其中最关键的序列安排是“图像在前、指令在中、动作在后”。这样生成动作 token 时,模型可以看到完整视觉和语言上下文。
若把这一过程和 RT-1 对照来看,差异会更清楚:
- RT-1 里,监督目标是“每个动作维度对应哪个 bin”;
- RT-2 里,监督目标变成“VLM 下一步应该输出哪个动作 token”;
- 于是动作预测首次和语言生成共享了同一套输出层、同一套词表约束、同一套 next-token 训练范式。
4. 联合微调
表示统一后,接下来是训练策略。这里最容易误解的点是:
“既然动作也变 token 了,直接拿机器人数据微调不就行了吗?”
论文实验给出的答案是:只做机器人微调会出现灾难性遗忘,语义泛化能力下降明显。
纯机器人微调可写为:
RT-2 采用 co-fine-tuning,在同一训练过程中同时保留机器人损失和 web 语义损失:
白话理解是:每一步更新都同时“学控制”与“保语义”,而不是先学完语义再被控制数据冲掉。
数据混合比大致为机器人样本占比约 50%(PaLI-X)和约 66%(PaLM-E),本质是抗遗忘工程权衡。
把消融结果压缩到一张表更容易读:
| 模型 | 训练策略 | 未见任务平均成功率 | 结论 |
|---|---|---|---|
| PaLI-X 5B | 从零训练 | 9 | 机器人数据不足以从零学语义 |
| PaLI-X 5B | 纯机器人微调 | 42 | 能学控制,但泛化受限 |
| PaLI-X 5B | 联合微调 | 44 | 同规模下优于纯微调 |
| PaLI-X 55B | 纯机器人微调 | 52 | 大模型有效,但仍有遗忘 |
| PaLI-X 55B | 联合微调 | 63 | 同规模下显著优于纯微调 |
读图时先看排序是否稳定,再看绝对数值:
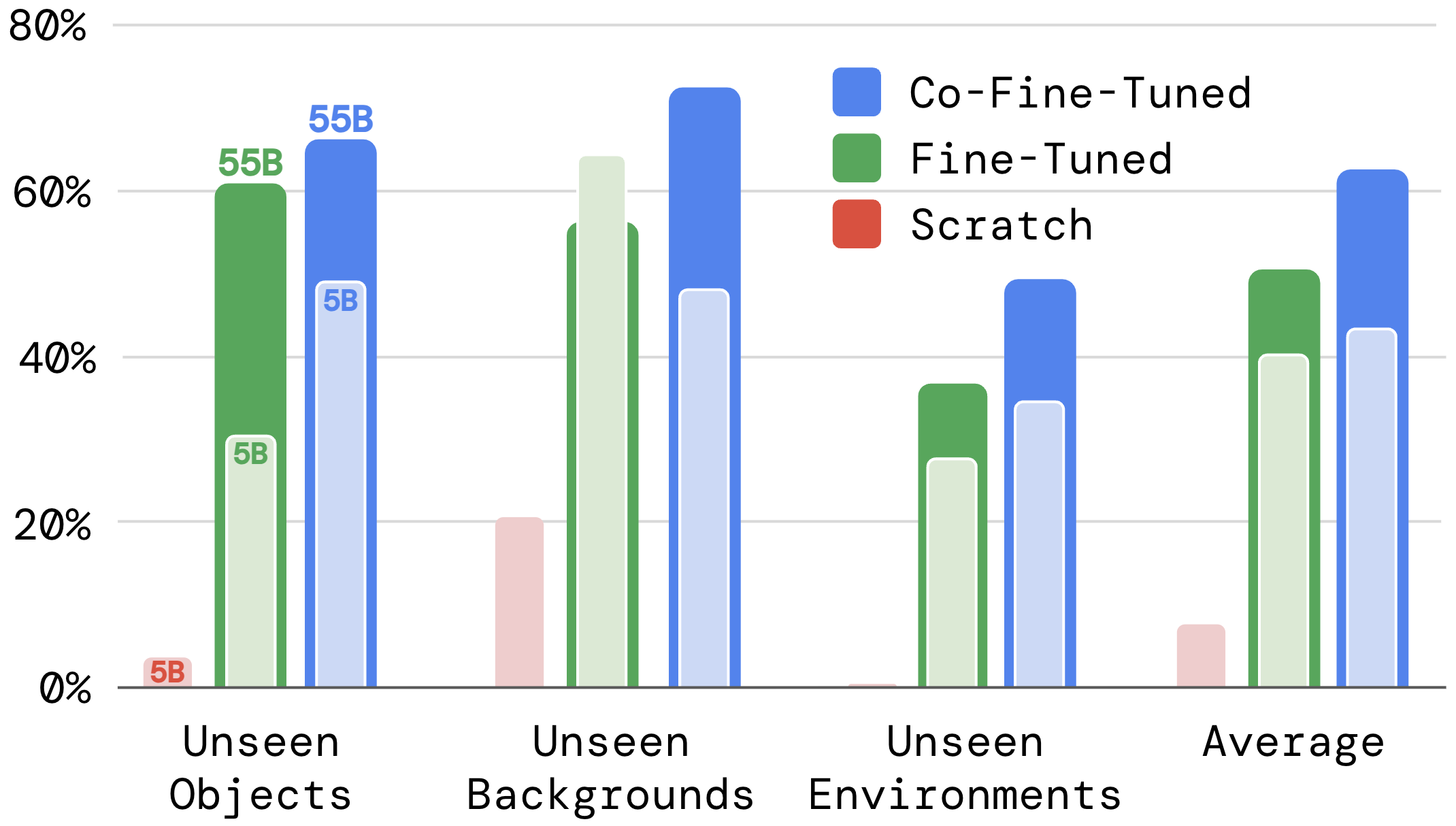
这张图主要证明“训练策略影响泛化排序”,尤其是从零训练明显最差。
再看总体对比图:
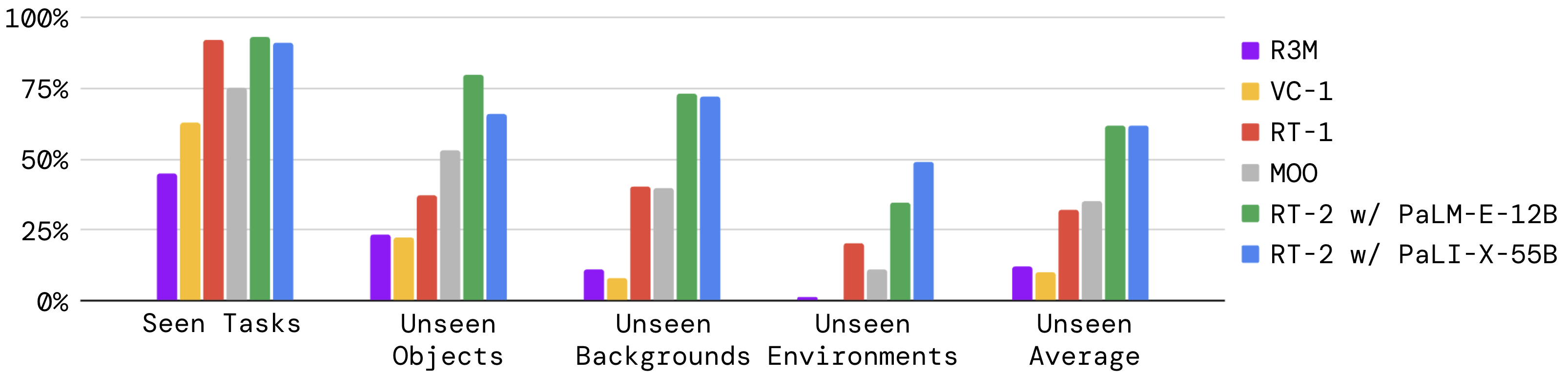
这张图主要说明收益集中在 unseen 维度,而不是所有维度平均上涨。这也正好对应 RT-2 的定位:语义迁移优先。
5. CoT 推理
在表示统一和联合微调之外,RT-2 还测试了 CoT 变体:先输出计划文本,再输出动作。
样例格式是:
Instruction: I'm hungry.
Plan: pick rxbar chocolate.
Action: 1 128 124 136 121 158 111 255
论文实现上,这个变体是在 PaLM-E 基础上继续做了几百个 gradient steps,并在数据里加入 Plan 字段。
如果用概率形式描述,可以把 Plan 看作中间隐变量
这条式子的直观含义是:
先在语义空间里形成一个可解释的中间计划,再条件化生成动作,比“直接一跳到动作”更容易稳定表达复杂语义。
读图时看两个阶段是否被显式展开:

这张图证明的是“机制可行、案例可见”;没有证明的是“在大规模定量评估上全面胜出”。所以 CoT 在这篇里更适合写成“潜力方向”,不是“最终定论”。
6. 训练与推理
前面讲的是为什么,下面把“从输入到部署”走一遍,方便形成完整闭环。
6.1 训练流程
训练循环可以压缩成四步:
- 输入:图像 token + 指令 prompt(VQA 风格模板)。
- 目标:动作离散 token 序列。
- 损失:标准 next-token 交叉熵(teacher forcing)。
- 约束:机器人模式下做 action vocabulary masking,仅采样合法动作 token。
主模型训练配置如下:
- RT-2-PaLI-X-55B:
lr=1e-3,batch=2048,80Ksteps。 - RT-2-PaLI-X-5B:
lr=1e-3,batch=2048,270Ksteps。 - RT-2-PaLM-E-12B:
lr=4e-4,batch=512,1Msteps。
三者都采用 next-token prediction,对应机器人控制里的 BC 目标。
如果用一条最小链路记忆,可以记成:
图像+指令 -> token 序列前缀 -> 预测动作 token -> 反离散化 -> 机器人执行
6.2 推理部署
部署侧结论同样重要,因为它直接决定可用任务范围:
- 55B RT-2 依赖云端多 TPU 服务推理。
- 55B 控制频率约
1-3Hz,5B 约5Hz。 - 工程结论是“可用但不高频”:适合中低频语义驱动操作,不适合高动态精细控制。
这也是为什么后续工作会继续做实时系统与执行层优化,而不只盯着模型本体。
7. 代价与边界
为了避免“只记住亮点”,这里把边界集中列清:
- 速度代价:大模型推理慢,实时控制上限明显。
- 技能边界:不直接产生新
motions,主要是已有技能的新语义组合。 - 常见失败:按特定部位抓取、未见新动作(如擦拭/复杂工具使用)、高精度灵巧动作(如折叠毛巾)、多层间接推理。
- 生态约束:PaLI-X / PaLM-E 闭源,早期社区难以完整复现。
把能力边界写成“能做/不能做”会更直观:
| 更擅长 | 仍薄弱 |
|---|---|
| 未见语义指令下的技能重组 | 未出现过的新动作技能生成 |
| 符号、关系、人相关语义理解 | 高频、精细、强动态控制任务 |
| 借助预训练语义做选择 | 依赖专门数据的新运动模式学习 |
因此更准确的结论是:RT-2 扩展了“何时调用哪种已有技能”的语义决策边界,但没有单独解决“如何生成全新动作技能”。
8. 总结与过渡
如果把这章压缩成一页记忆卡,核心是三个统一:
- 表示统一:动作 token 化,与语言共享解码框架。
- 训练统一:联合微调,降低灾难性遗忘。
- 推理统一:CoT 把规划和执行放进同一序列。
这三点让机器人策略可以更直接继承互联网规模预训练语义能力。
下一讲会把焦点从“语义迁移”转到“数据异构融合”:跨机构、跨机器人、跨控制频率的数据如何一起训练。