11. RTC 实时执行与系统交付
先修建议
- 已理解 action chunking 的基本执行方式(每次推理输出一段动作序列)
- 已了解 flow matching 的迭代去噪生成形式
- 具备基本实时系统概念(采样周期、时延、线程同步)
本节目标
- 建立 RTC 的问题定义与符号系统(
) - 理解同步/朴素异步为何在高延迟下失效
- 对齐论文原式理解 Guided Inference 与 soft masking
- 明确“论文结论”和“工程扩展建议”的边界
RTC 是什么,何时使用 RTC(Real-Time Chunking)是一种推理时调度与引导方法,目标是在模型单次推理显著慢于控制周期时,仍让动作流持续输出并保持跨 chunk 的轨迹连续性。
通常更适合 RTC 的场景:
- 使用 diffusion/flow 类 action chunking 策略
- 控制频率较高,且推理或网络延迟不可忽略
- 任务对轨迹连续性敏感(如高动态、强闭环操作)
与常见替代路线的关系:
- 与“只做模型加速”(量化、蒸馏、并行解码)相比,RTC 重点解决的是高延迟下的调度与接缝稳定性
- 与 Temporal Ensembling 等后处理相比,RTC 直接把“下一段生成”写成受约束的条件生成,通常更容易保持策略一致性
从 action chunking 策略开始:
其中:
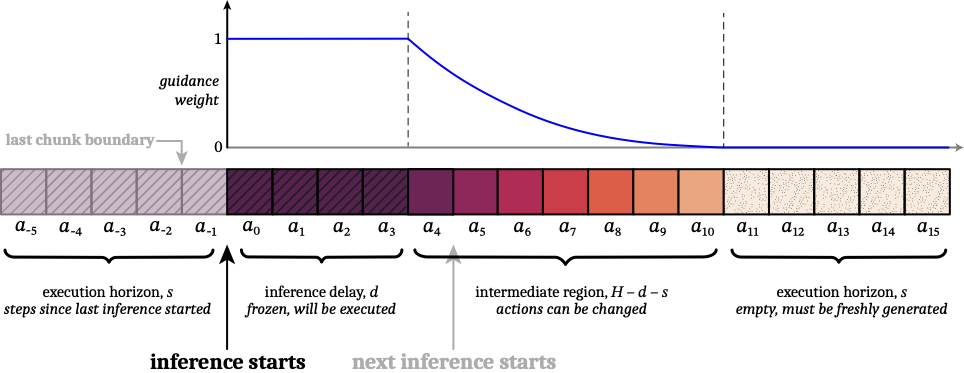
是 prediction horizon(每次预测的动作长度) 是控制时刻 的观测 - 每个 chunk 通常只执行前
步(execution horizon),且一般
chunking 的收益是时序一致性,代价是反应性下降。
读图重点:在显著延迟注入下,RTC 仍能维持高动态闭环任务的可执行性。

1. 时间约束与失败模式
1.1 时间变量与可行条件
设控制器采样周期为
若希望系统始终有动作可发,必须满足“下一段 chunk 到达前,当前段尚未耗尽”,常用可行区间写法为:
1.2 数值背景(论文口径)
论文给出的实时压力示例:
- 目标控制频率 50Hz,即
ms - 3B 规模策略仅 KV prefill 就可能在 46ms 量级
- 远程推理还会叠加网络时延(论文示例给出有线低时延条件约 13ms)
- 7B OpenVLA 的加速实现仍可见 321ms 级时延
因此“单次完整推理
1.3 两类失效模式
- 同步阻塞推理:
- 在 chunk 边界停下来等下一次推理完成,出现可见 pause
- 机器人动力学轨迹被打断,部署分布偏离训练分布
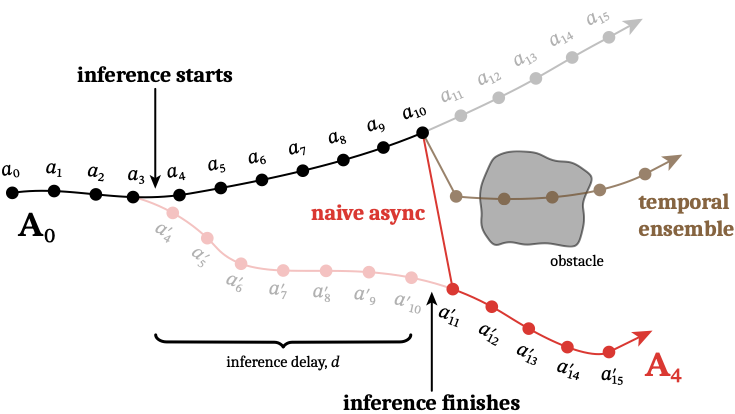
- 朴素异步切换:
- 虽然动作不断流,但新旧 chunk 接缝可出现大跳变
- 在多模态场景中尤其明显(策略从“上绕障碍”跳到“下绕障碍”)
读图重点:系统必须在“推理并发”与“轨迹连续”之间同时满足约束。
2. 从硬切换到 Inpainting
chunk 接缝抖动本质是“两个独立采样轨迹在边界硬拼接”。前一时刻执行的是
读图重点:单独看每段轨迹都合理,但硬切换后的拼接轨迹可能不可行。
常见补救方案及其局限:
| 方法 | 优点 | 主要失效点 |
|---|---|---|
| Temporal Ensembling(重叠平均) | 实现简单,可一定程度降抖 | 多模态下“均值动作”可能不可执行 |
| 硬 freeze(前缀强制覆盖) | 能保证前缀连续 | 新观测在重叠段的修正能力下降 |
RTC 的核心做法是把“下一 chunk 生成”重写为 inpainting 问题:冻结必然会被执行的前缀,并在剩余区间做条件生成。
3. Guided Inference 数学形式(对齐论文原式)
3.1 Flow matching 基础更新
对带噪动作 chunk
其中
3.2 PiGDM 引导修正(RTC 使用的主式)
论文主式:
解释要点:
是当前步对“最终去噪结果”的估计 - 引导项本质是一个 vector-Jacobian product(VJP),可由反向自动微分实现
是引导权重上限,用于稳定低步数去噪(控制场景常见 )
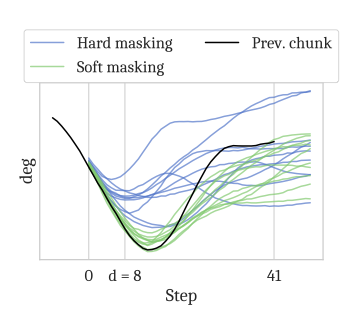
3.3 soft masking 权重(论文原式)
RTC 并不只对前
物理意义:
:这些动作在推理完成前一定会被执行,必须强对齐 :有重叠但不一定执行,允许“受约束地修正” :无重叠,完全由新观测主导生成
说明:工程实现中可用指数衰减近似帮助直觉理解,但教程正文建议保留上面的论文分段原式。
读图重点:soft masking 的作用不是“更平滑曲线”本身,而是“更稳定的跨 chunk 策略连续性”。
3.4 关于
论文附录消融显示,在低去噪步(如
4. 异步执行算法(对齐 Algorithm 1)
4.1 共享状态与线程角色
- 控制线程(消费者):每
调用 GetAction消费下一动作 - 推理线程(生产者):后台持续运行
InferenceLoop - 共享状态:
A_cur(当前 chunk)、t(已消费步数)、o_cur(最新观测)、Q(延迟缓冲) - 同步原语:互斥锁
与条件变量
4.2 核心伪代码(教程化改写,变量与论文一致)
GetAction(o_next):
lock M
t = t + 1
o_cur = o_next
notify C
return A_cur[t - 1]
unlock M
InferenceLoop:
Q = Queue([d_init], maxlen=b)
while True:
lock M
wait C until t >= s_min
s = t
A_prev = A_cur[s:]
o = o_cur
d = max(Q) # 保守估计下一轮延迟
unlock M
A_new = GuidedInference(π, o, A_prev, d, s)
lock M
A_cur = A_new # 整体替换,避免读半更新状态
t = t - s # 让 t 重新对齐新 chunk
Q.push(d_obs) # 观测到的延迟步数(实现上可由 wall-clock 或消费步统计)
unlock M
GuidedInference(π, o, A_prev, d, s):
compute W with Eq.(weights)
right-pad A_prev to H
A^0 ~ N(0, I)
for τ in {0, 1/n, ..., (n-1)/n}:
f_hat(A') = A' + (1-τ) * v_π(A', o, τ)
e = (A_prev - f_hat(A^τ))^T * diag(W)
g = e * ∂f_hat/∂A' |_{A'=A^τ} # VJP
A^{τ+1/n} = A^τ + (1/n) * (v_π(A^τ,o,τ) + min(β,(1-τ)/(τ*r_τ^2))*g)
return A^1
4.3 算法实现要点
- 推理必须在锁外执行,避免控制线程被长时间前向阻塞。
- chunk 切换应为整体替换,不应原地部分写入。
用于控制最小执行长度;论文描述中实际执行长度会受延迟估计影响(常见实现取 )。
5. 实验结论与可迁移经验
5.1 仿真与真机配置对照(论文口径)
| 配置项 | 仿真 | 真机 |
|---|---|---|
| 任务集 | 12 个 Kinetix 高动态任务 | 6 个双臂任务(含移动任务) |
| 8 | 50 | |
| 5 | 5 | |
| 按环境设定 | 20ms(50Hz) | |
| 不需要(固定延迟实验) | 25 | |
| 5 | 5 | |
| 不需要 | 10 |
5.2 真机关键延迟口径
- 同一模型下:vanilla 约 76ms,RTC 约 97ms(GPU 推理部分)
- 远程部署再叠加 LAN 开销(论文示例 10-20ms)
- 注入 +100ms / +200ms 延迟后,推理延迟步数会明显上升(论文报告约
)
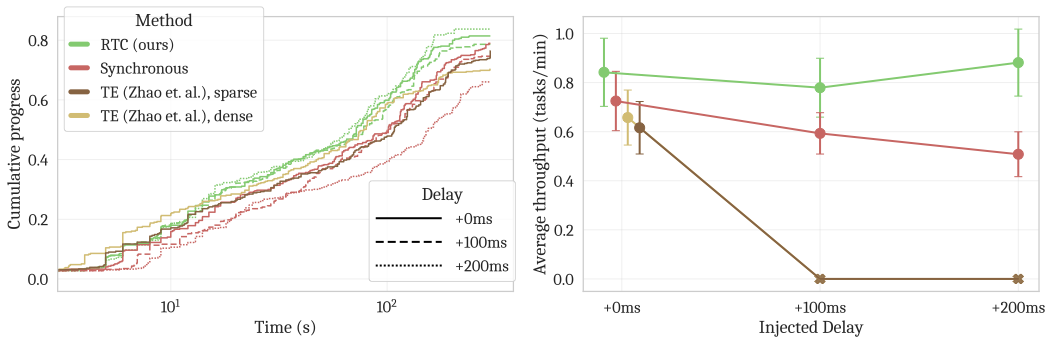
5.3 实验结论(按论文主张归纳)
- 仿真基准中,RTC 对推理延迟更稳健,且相对 BID/TE 有优势。
- soft masking 相比 hard masking 在低延迟或较短执行步时更优。
- 真机评测中,RTC 的 throughput(速度与完成度综合指标)在高延迟注入下优势更明显。
- 高频动态任务中,TE 在高延迟下可能诱发强振荡并触发保护停机(按论文评估设置)。
读图重点:曲线关注的是“吞吐-稳定性联合指标”,而不是单点成功率。
读图重点:位置/速度/加速度三者联合观察,能直接看到接缝抖动是否被抑制。

6. 部署边界与工程扩展建议
6.1 论文明确边界
- 适用范围:RTC 针对 diffusion/flow 类 action chunking policy。
- 计算代价:引导项需要反向计算,带来额外推理开销。
- 任务外推:真实实验虽覆盖多类双臂任务,但仍不能代表全部动态控制场景。
6.2 工程扩展建议(非论文原文结论)
以下建议在工程中较常见,但不属于论文直接结论,落地时需要结合具体平台验证:
- 线程调度:推理线程提高调度优先级,降低抖动。
- 内存与 I/O:减少运行期分页和突发 I/O 对延迟尾部的影响。
- GPU 资源隔离:避免日志/诊断任务与主推理争抢队列。
- 监控指标:动作年龄、延迟分位、freeze 占比三项长期跟踪。
可操作的监控表:
| 指标 | 含义 | 风险信号 |
|---|---|---|
| 动作年龄 | 当前 chunk 已消费步数 | 反复逼近 |
| 延迟分位(如 P99/P50) | 延迟尾部压力 | 比值持续升高常指向系统抖动 |
| freeze 占比 | 受硬约束区间比例 | 持续过高会压缩闭环修正空间 |
6.3 异常兜底(非论文原文结论)
可作为部署侧安全网的策略:
- deadline miss handler:当新 chunk 未及时到达时,进入受控降级动作而非卡死。
- 数值异常恢复:出现 NaN/发散时保守回退并扩大后续 freeze。
- 频率降级策略:当
长期逼近 时触发降频/告警。
7. 总结与过渡
RTC 解决的是“慢推理模型如何保持实时执行正确性”,而不是“把模型本身直接加速到控制周期内”。
可以把 RTC 的贡献压缩为三点:
- 系统层:通过异步生产者-消费者结构保证动作不断流。
- 算法层:通过 Guided Inference + soft masking 缝合 chunk 接缝。
- 实验层:在高延迟注入下仍保持较强的吞吐与稳定性。
模型加速路线(量化、蒸馏、并行解码)与 RTC 调度路线是正交关系。真实部署通常需要两条线并行推进:一条降单次推理时延,另一条提升高延迟下的控制鲁棒性。