2. 从 LLM 到机器人策略
先修建议
- 熟悉 Transformer 的注意力与自回归训练目标。
- 了解视觉编码基础(如 ViT patch 表示)与常见损失(cross-entropy、MSE)。
- 具备机器人控制中的机体坐标、控制频率、动作表征基本概念;若后续连读第 8 章,建议先补 DDPM/DDIM 的训练与采样直觉。
本节目标
- 说明 VLA 在具身智能中的问题定义与出现背景。
- 建立
LLM -> VLM -> VLA的统一策略函数视角。 - 梳理单体式与层次式路线的核心取舍。
- 给出 2022-2025 年关键方法演进脉络,为后续章节建立坐标系。
本章聚焦全景框架,不拆单个模型实现细节。LLM/VLM 主要处理“信息输入到信息输出”,VLA 则进一步要求“信息理解到物理执行”的闭环落地;因此,动作表征、时序建模与部署约束会成为主线问题。

这一讲只做一件事:把 2022 年到 2025 年从 LLM 通往 VLA 的技术路径拉成一条线,回答“为什么出现 VLA、它在解决什么矛盾、为何在架构与训练范式上持续迭代”。
1. 一个策略函数的三次“换装”
把这件事想清楚的起点是一张再简单不过的图:一台 agent,一个策略函数
语言模型是这个框架里最成功的特例。把输入定义成"到目前为止的 token 序列
这个式子看似朴素,实则悄悄地做了两件事。其一,它把"智能"约化成了条件概率——没有隐式的符号推理,没有显式的规划模块,全部任务都被塞进了"给定前文、预测下一词"这一个目标里。其二,它假设因果顺序是唯一的:第
VLM 做的事情在形式上几乎没有变化——它只是把条件里的"前文"从纯 token 扩展到 token + 图像:
图像经一个视觉编码器被映射成若干 patch embedding,和语言 token 拼到同一个序列里,让 Transformer 用同一套注意力去处理。这一步的代价非常低——不用改损失函数、不用改架构、只要把视觉编码器接上就行——但能力上的回报是巨大的:模型从"文字世界的复读机"变成了"能看图说话的文字世界复读机"。
VLA 再向前一步。它要做的是把输出空间从"下一个文字 token"扩展到"下一段动作"。此时策略函数写成
其中
形式上的改动非常小,但两处细节会贯穿后面所有九讲。第一,
一句话归纳:LLM、VLM、VLA 在形式上是同一个
| 模型 | 条件 | 输出 | 损失范式 |
|---|---|---|---|
| LLM | 下一个 token | 分类交叉熵 | |
| VLM | 下一个 token | 分类交叉熵 | |
| VLA(离散动作) | 动作 token | 分类交叉熵 | |
| VLA(连续扩散/流) | 动作向量块 | MSE(对噪声或向量场) |
2. 单体式与层次式如何取舍
有了"VLA = 一个把观测映射到动作的
单体式(Monolithic) 把所有事情压在一个网络里。它的哲学非常直接:既然 Transformer 在 LLM/VLM 上表现得那么好,就不要再发明额外的抽象层——让同一个 Transformer 同时承担视觉感知、语言理解、动作生成。
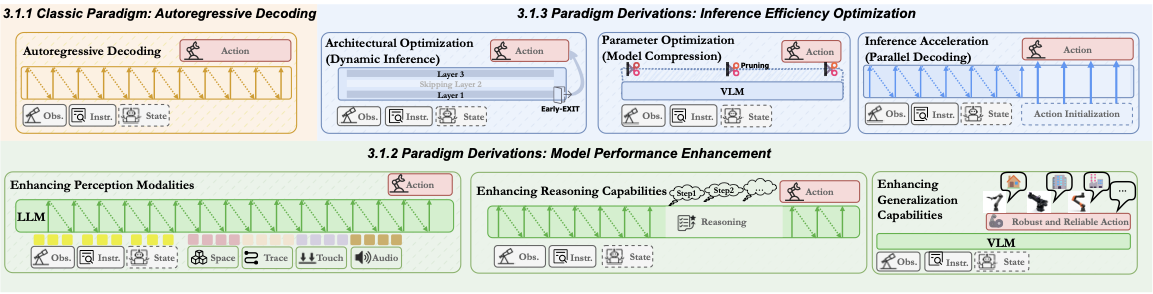
但"一个网络到底"内部又能再细分。最极端的版本叫单系统(single-system):图像进去,动作 token 出来,除了分词表被动了一下手脚,网络结构本身和普通 VLM 几乎没有差别。RT-2 是这一支的代表——它干脆把连续动作离散化成整数,让 VLM 用 next-token prediction 同时生成"文字回答"和"动作指令"。OpenVLA 把这套思路开源化,让社区第一次能亲手复现这条链路。
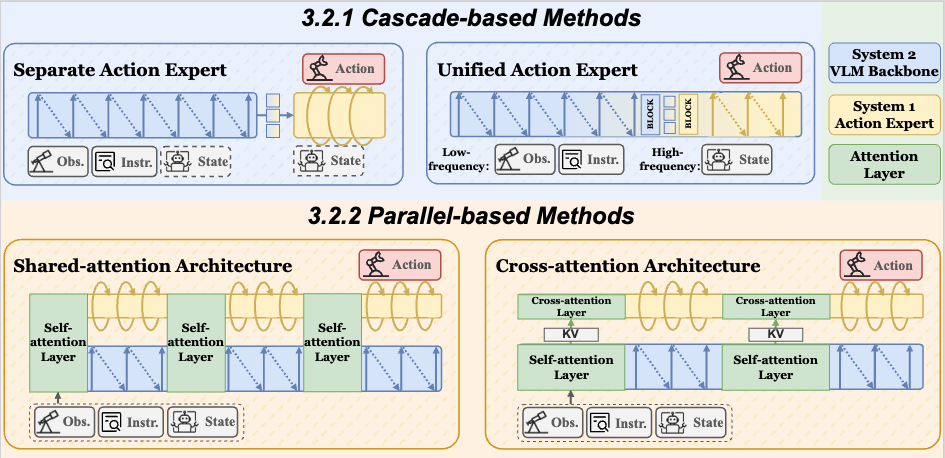
稍微软化一点的版本叫双系统(dual-system)。它承认一件事:语言理解和运动控制在计算需求上并不对称。语言是序列化、因果的;但一个 7-DoF 机械臂的 7 个关节必须彼此协调、同时输出,强行做成因果自回归不是最优解。于是双系统在 VLM 主干之外,再挂一个专门的动作专家——两者共享观测表征,但各自用不同的损失和推理方式。
下图展示双系统的两类实现:级联式(separate / unified action expert)与并行式(shared-attention / cross-attention)。
层次式(Hierarchical) 走的是"先规划、再执行"路线。上层由视觉语言规划器负责理解指令并生成中间子任务;这些中间表示可以是自然语言步骤(如"先去冰箱前面、打开冰箱门、取出牛奶、关上门"),也可以是符号、代码或关键点。下层是低层策略,只负责把子任务翻译为关节级控制。SayCan、Code as Policies、VoxPoser 都属于这一路线。
它的优势是模块解耦:规划错了,优先升级规划器;执行不稳,优先升级控制器。难点在接口粒度:子任务过于抽象(如"把桌子收拾干净"),下层无法直接落地;子任务过于具体(关节目标序列),上层又失去泛化空间。
下图对比了单体式与层次式在信息流、模块边界和中间表示上的差异。

这条分野并非绝对对立。随着单体式双系统越做越细,上层 VLM 负责高阶语义决策、下层动作专家负责连续控制,它与层次式在功能上已高度接近;核心差异逐渐收敛到"上层与下层是否共享权重"。
3. 三代技术与三类核心矛盾
如果把 2022 年至今的 VLA 工作画成一条时间线,会看到三次清晰的代际切换。每一代面对的核心问题都不一样——不是"又提出了一个新架构",而是"上一代留下的天花板必须被打穿"。

第一代(2022–2023):能不能跑通?
这一代面对的是一个纯粹的存在性问题:在机器人这种"数据稀疏、动作高维、闭环耦合"的领域,Transformer 能不能像在 NLP 里那样,吃下足够多的数据,涌现出可用的策略?
RT-1 是第一个给出正面答案的工作。Google 用 13 台机器人在 17 个月里采集了 13 万条演示轨迹,把它们喂给一个 19M 参数的小 Transformer,证明了——机器人领域的 scaling law 是真的。13 万条数据远不及文本的互联网规模,但已经足够让模型对新物体、新背景、新指令展现出量变到质变的泛化。RT-2 更激进,它把预训练 VLM(PaLI-X、PaLM-E)直接改造成机器人策略,让"互联网语义"流入动作空间——机器人第一次学会"把水果放到数字 3 上"这种训练数据里从未出现过的指令。Open X-Embodiment 则回到数据侧,把 22 个机构的数据聚合成第一个跨机体共享仓库,为后续所有工作铺好了地基。
这一代的矛盾是可行性:动作能不能被 token 化?小模型能不能从有限演示里学到可泛化的策略?大 VLM 的知识能不能迁移到物理操作?答案都是肯定的,但代价是精度和速度都不够。
第二代(2023–2024):能不能做精?
当 RT 系列证明了"能跑"之后,天花板立刻换成另一个:这些模型能抓杯子能开抽屉,但穿不了针、插不了 USB、拧不了螺丝。问题有两层。第一层在动作表征——256 个离散 bin 在毫米级精度任务上分辨率不够;第二层在动作分布——同一观测下往往存在多种合理路径,MSE 回归只会学到它们的平均值,而平均值恰恰可能是不可行的动作。
解决方案从两个方向同时收敛。ACT 提出动作分块(action chunking):一次性预测未来一整段动作而非单步,把累积误差的增长率从
这一代的矛盾是表达力:怎么把连续、多模态、高维的动作分布装进可微分的策略里。
第三代(2025– ):能不能进化?
第二代模型已经足够精确,甚至能连续自主操作几个小时。但它们共享一个更隐秘的天花板——所有能力都冻结在训练结束那一刻。部署后遇到没见过的场景,你要么接受失败,要么回去采集更多演示、重训。
第三代的矛盾是持续进化:如何构建能从自己的失败中纠错、不依赖人工标注就能变强的具身智能体。
4. 同一个问题为何被“解决三次”
如果只看时间线,会有一种"每一代都在重发明轮子"的错觉。但把视角切换到被优化的目标上,三代的脉络就会非常清楚。
-
第一代在优化条件概率
本身——让这个分布的负对数似然在大规模演示上最小化。方法简单粗暴:把动作离散化成 token,用语言模型的交叉熵损失就能训。 -
第二代在优化这个条件概率的形状。交叉熵损失在离散分类里能刻画多峰,但动作是连续量,一旦你回归的是连续值,MSE 目标就隐含"单峰高斯"的先验——这个先验和真实演示分布不匹配。所以第二代要么继续走离散 token 的路(但把 bin 分得更细、分位数分箱替代 min-max),要么换用扩散/流这种天然支持多模态的生成模型。
-
第三代在优化上线后这个条件概率的更新机制。前两代已经把基础策略训到了不错的水平,但它是开环的——训练完就冻结,不会因为部署中的好坏反馈而改变。第三代引入了优势估计、价值函数、条件采样(classifier-free guidance),让策略可以被"新的好/坏数据"持续塑形。
这三层目标是堆叠的,不是替代的。你不会因为第三代的出现就不需要第一代的 token 化;RT-2 的动作离散化思路至今仍在 OpenVLA、
5. VLA 十二讲路线图
从第 02 讲开始,我们就会沿着这条时间线逐个拆解关键节点。每一讲对应一个技术决定,以及它在那一代所要解决的核心矛盾。
每一讲的核心阅读线索如下:
| 讲次 | 主题 | 要盯住的那个问题 |
|---|---|---|
| 02 | RT-1 | 连续动作被切成 256 个 bin,为什么损失换成分类交叉熵就够用 |
| 03 | RT-2 | co-fine-tuning 里那个"互联网数据 : 机器人数据"的比例从哪来 |
| 04 | Open X-Embodiment | 22 种机体不做坐标系对齐,为什么还能正迁移 |
| 05 | OpenVLA | 为什么分位数分箱比 min-max 分箱更抗异常值 |
| 06 | ACT | chunk 化把累积误差从 |
| 07 | Diffusion Policy | ε-prediction 和 score matching 是同一件事的两种写法 |
| 08 | Flow Matching 的路径为什么是直的、DDPM 的为什么是弯的 | |
| 09 | 层级推理 + 异构 co-training 为什么能打开"开放世界泛化" | |
| 10 | RTC | guided inference 背后其实是 classifier guidance 的数学 |
| 11 | 为什么 PPO 在 flow matching 上先天失效 | |
| 12 | steerability 与组合泛化如何让 VLA 变成可被指挥的通用执行体 |
按顺序读最扎实,但也不一定要从头啃到尾。如果你已经熟悉 RT 系列,第 6 讲是最合适的切入点——动作分块这个想法会贯穿后面几乎所有工作。如果你只关心前沿进展,直接从 8 讲的
接下来我们从 RT-1 开始。它不是最强的模型,也不是最聪明的架构,但它是第一个让人相信"Transformer 能学机器人"这件事是真的的工作。