3. ViT 与视觉表征
1. 输入表示与 Patch Embedding
1.1 为什么需要 Patch Embedding?
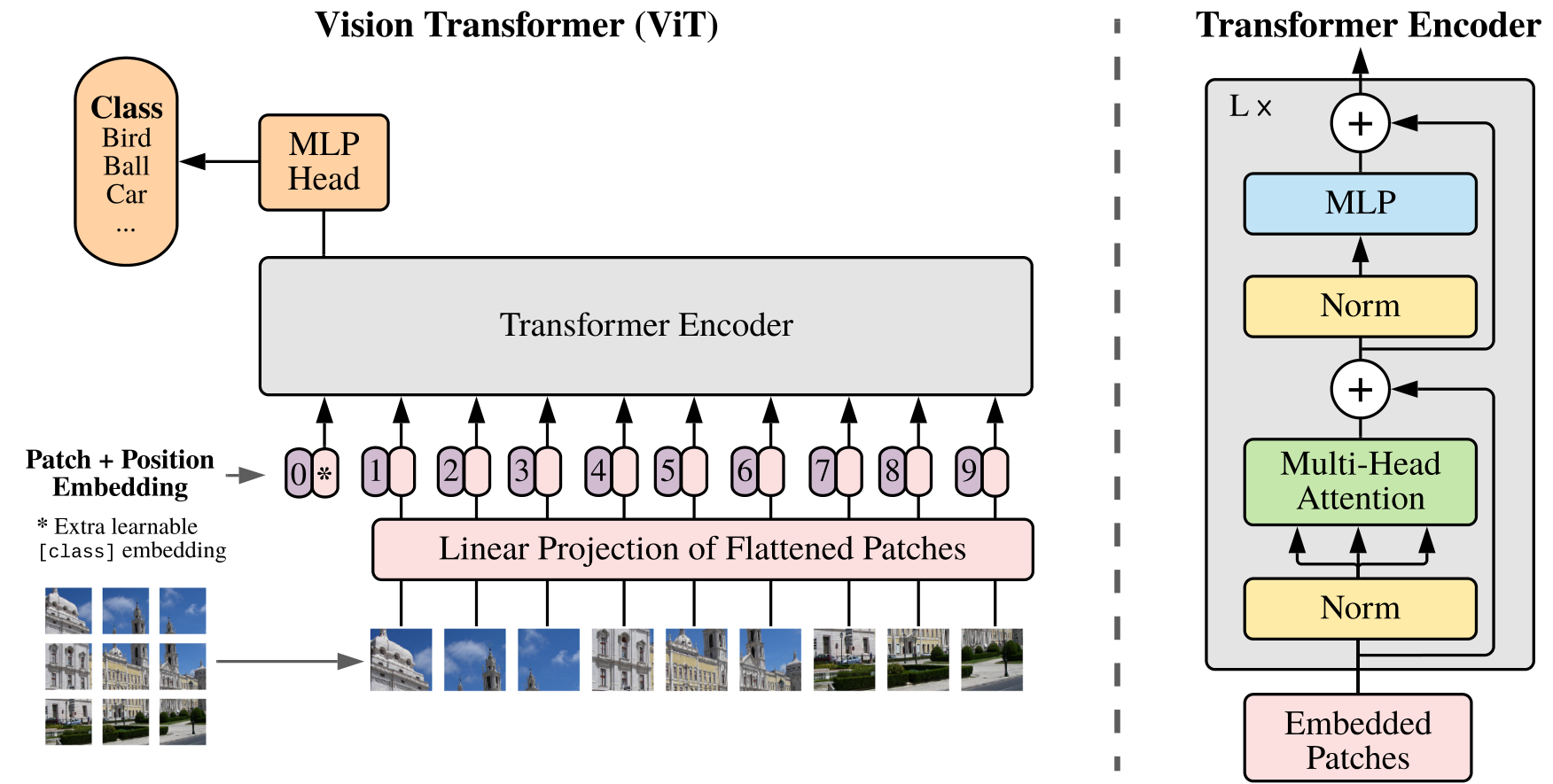
1.1.1 问题背景
Transformer 原本用于处理一维序列,但图像是二维网格。最直接的办法是把每个像素当成一个 token,但这会带来两个问题:
- 224×224 图像会产生 50,176 个像素 token
- 自注意力复杂度是 O(n²),序列过长时计算量不可接受
1.1.2 ViT 的解决方案
ViT 的核心做法是把图像切成固定大小的 Patch,让每个 Patch 对应一个 token:
| 图像尺寸 | Patch 大小 | Token 数量 |
|---|---|---|
| 224×224 | 16×16 | 196 |
| 224×224 | 14×14 | 256 |
| 384×384 | 16×16 | 576 |
这样既保留了局部结构,又把序列长度压到了可接受范围。
1.2 Patch Embedding 的数学原理
在进入公式之前,先建立一个直觉:每个 16×16 的像素块本身就包含了局部纹理、边缘和颜色分布等信息,只是这些信息散落在 768 个原始像素值里,维度高且冗余。线性投影的作用类似于"压缩+旋转"——它学习一组基向量,把高维像素空间中有意义的模式(如边缘方向、颜色梯度)投影到一个更紧凑的特征空间中,使得语义相近的 Patch 在新空间里彼此靠近。这和 NLP 中词嵌入把离散 token 映射到连续向量空间的思路是一致的。
1.2.1 图像分块
设输入图像为
1.2.2 展平与线性投影
每个 Patch 展平为向量:
再映射到
其中:
是投影矩阵 是偏置 是 Transformer 的隐藏维度
1.2.3 完整公式
其中:
:可学习的分类 token :位置编码
1.3 实现方式
1.3.1 方式一:先 Reshape 再线性投影
朴素实现的思路很直接:先将图像张量按 Patch 大小在空间维度上 reshape 为 (B, H/P, W/P, P, P, C) 的块结构,再将每个 Patch 内的像素展平为 P²·C 维向量,最后通过一个 nn.Linear 投影到隐空间维度 D。这种写法逻辑清晰,但涉及多次 reshape 和 permute 操作,实际效率不如下面的卷积实现。
1.3.2 方式二:使用卷积(等价且高效)
Patch Embedding 等价于一个 kernel_size = stride = patch_size 的卷积操作。
class PatchEmbeddingConv(nn.Module):
"""高效实现:使用卷积完成分块+投影"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size,
)
def forward(self, x):
x = self.proj(x) # (B, embed_dim, H/P, W/P)
x = x.flatten(2) # (B, embed_dim, N)
x = x.transpose(1, 2) # (B, N, embed_dim)
return x
1.3.3 为什么卷积实现等价?
| 线性投影视角 | 卷积视角 |
|---|---|
| 每个 16×16 Patch 展平为 768 维向量 | 16×16 卷积核,stride=16,输出 768 通道 |
| 投影矩阵 (768, 768) | 卷积权重 (768, 3, 16, 16) |
两者数学上等价,但卷积实现更简洁,也更容易利用 GPU 加速。
1.4 位置编码的添加
1.4.1 可学习位置编码(ViT 默认)
class ViTPatchEmbed(nn.Module):
"""完整的 ViT Patch Embedding,包含 CLS Token 和位置编码"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
self.patch_embed = nn.Conv2d(
in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size
)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, self.num_patches + 1, embed_dim))
nn.init.trunc_normal_(self.cls_token, std=0.02)
nn.init.trunc_normal_(self.pos_embed, std=0.02)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x) # (B, D, H/P, W/P) - 卷积分块并投影
x = x.flatten(2).transpose(1, 2) # (B, N, D) - 空间维展平,转为序列格式
# 将形状为 (1, 1, D) 的 CLS token 复制 B 份,扩展到 batch 维
cls_tokens = self.cls_token.expand(B, -1, -1) # (B, 1, D)
# 将 CLS token 拼接到 patch 序列最前面,使其能通过注意力聚合全局信息
x = torch.cat([cls_tokens, x], dim=1) # (B, N+1, D)
x = x + self.pos_embed # (B, N+1, D) - 叠加可学习位置编码
return x
1.4.2 2D 位置编码(替代方案)
由于 Patch 具有二维空间结构,也可以使用 2D sin-cos 位置编码。核心思路:将每个 Patch 的行索引和列索引分别用 1D sin-cos 编码,然后将两者拼接成完整的位置向量。这样位置编码天然具有 2D 结构,比 1D 可学习编码更适合不规则分辨率输入(例如推理时换用更大图像)。
为什么 2D sin-cos 比 1D 可学习编码更适合图像?
| 对比维度 | 1D 可学习编码 | 2D sin-cos 编码 |
|---|---|---|
| 位置信息 | 一维序号,隐式包含 2D 结构 | 显式编码行、列位置 |
| 分辨率迁移 | 需要插值,效果一般 | 可自然推广到新分辨率 |
| 参数量 | 有(随 token 数增加) | 无参数,确定性计算 |
| 适合场景 | 固定分辨率分类任务 | 需要处理变长输入的 VLM/VLA |
1.5 可视化理解
1.5.1 Patch 划分示意
原始图像 (224 × 224 × 3)
┌────┬────┬────┬────┬─...─┬────┐
│ P1 │ P2 │ P3 │ P4 │ │P14 │
├────┼────┼────┼────┼─...─┼────┤
│P15 │P16 │P17 │P18 │ │P28 │
├────┼────┼────┼────┼─...─┼────┤
│ │ │ │ │ │ │
... ... ... ... ... ...
├────┼────┼────┼────┼─...─┼────┤
│ │ │ │ │ │P196│
└────┴────┴────┴────┴─...─┴────┘
每个 Patch: 16 × 16 × 3 = 768 维
共 14 × 14 = 196 个 Patch
1.5.2 Embedding 过程
图像 切块展平 线性投影 添加位置编码
224×224×3 → [P1, P2, ..., P196] → [z1, z2, ..., z196] → [z1+PE1, z2+PE2, ...]
每个 768 维 每个 768 维 每个 768 维
↓ 添加 CLS Token
最终: [CLS, z1+PE1, z2+PE2, ..., z196+PE196] 共 197 个 Token
1.6 关键设计选择
1.6.1 Patch 大小的权衡
| Patch 大小 | Token 数量 | 计算量 | 细节捕捉 |
|---|---|---|---|
| 8×8 | 784 | 高 | 好 |
| 16×16 | 196 | 中 | 中 |
| 32×32 | 49 | 低 | 差 |
常用配置:
- ViT-B/16:Patch 大小 16,Base 规模
- ViT-L/14:Patch 大小 14,Large 规模
- ViT-H/14:Patch 大小 14,Huge 规模
为什么现代 VLM/VLA 偏爱 Patch 14(ViT-L/14)? Patch 14 比 Patch 16 粒度更细,能保留更多空间细节——对机器人操控等需要精确定位的任务尤为重要。代价是 token 数从 196 增加到 256(224×224 输入),对 LLM 的序列处理带来一定压力。当输入分辨率提升到 336×336 或 448×448 时,token 数可达 576~1024,这一权衡在高分辨率场景下尤为突出,也是业界持续探索 token 压缩方案的主要动因。
1.6.2 重叠 Patch(Overlapping Patches)
一些改进方法会让 Patch 之间有重叠:
1.6.2.1 重叠 Patch Embedding
self.proj = nn.Conv2d(
in_channels, embed_dim,
kernel_size=16, stride=12 # stride < kernel_size
)
优点是能更好地捕捉边界信息,缺点是 token 数增加、计算量上升。
1.7 小结
| 要点 | 说明 |
|---|---|
| 核心作用 | 将 2D 图像转换为 1D Token 序列 |
| 实现方式 | 使用 stride=patch_size 的卷积最简洁 |
| Patch 大小 | 常用 16×16 或 14×14 |
| 输出维度 | (B, N+1, D),包含 CLS Token |
| 位置编码 | 可学习 1D 编码或 2D sin-cos 编码 |
2. ViT 架构、训练与实现
2.1 ViT 架构概览
2.1.1 整体流程
输入图像 (224×224×3)
↓
┌─────────────────────────┐
│ Patch Embedding │ 图像 → Patch 序列
│ + CLS Token │
│ + Position Embedding │
└─────────────────────────┘
↓
┌─────────────────────────┐
│ Transformer Encoder │ L 层堆叠
│ (Multi-Head Attention │
│ + FFN + LayerNorm) │
└─────────────────────────┘
↓
┌─────────────────────────┐
│ Classification Head │ CLS Token → 类别
└─────────────────────────┘
↓
输出 (num_classes)
2.1.2 关键组件
| 组件 | 作用 |
|---|---|
| Patch Embedding | 将图像切分为 Patch 并投影到隐空间 |
| CLS Token | 聚合全局信息,用于分类 |
| Position Embedding | 注入位置信息 |
| Transformer Encoder | 特征提取与建模 |
| MLP Head | 将 CLS Token 映射到类别概率 |
2.2 CLS Token 的设计
2.2.1 什么是 CLS Token?
CLS(Classification)Token 是一个可学习向量,添加在 Patch 序列最前面:
输入序列: [CLS, P1, P2, P3, ..., P196]
↑
可学习参数
2.2.2 为什么需要 CLS Token?
| 问题 | CLS Token 的解决方案 |
|---|---|
| 如何聚合所有 Patch 的信息? | CLS Token 通过注意力机制与所有 Patch 交互 |
| 分类时使用哪个 Token? | 使用 CLS Token 的最终表示 |
| 如何避免位置偏差? | CLS Token 不对应具体 Patch,位置中立 |
2.2.3 CLS Token 的工作原理
Layer 1: [CLS] [P1] [P2] ... [P196]
↓ ↓ ↓ ↓
←─────────────────────────→ (Self-Attention)
↓
Layer 2: [CLS'] [P1'] [P2'] ... [P196']
↓
...
↓
Layer L: [CLS*] [P1*] [P2*] ... [P196*]
↓
MLP Head → 分类结果
CLS Token 会在多层注意力中不断聚合全局信息。
2.2.4 代码实现
class ViT(nn.Module):
def __init__(self, ...):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
nn.init.trunc_normal_(self.cls_token, std=0.02)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x) # (B, N, D)
cls_tokens = self.cls_token.expand(B, -1, -1) # (B, 1, D)
x = torch.cat([cls_tokens, x], dim=1) # (B, N+1, D)
x = x + self.pos_embed # (B, N+1, D)
x = self.transformer(x) # (B, N+1, D)
cls_output = x[:, 0] # (B, D)
return self.head(cls_output) # (B, num_classes)
2.3 Transformer Encoder
2.3.1 单层 Encoder Block
class TransformerEncoderBlock(nn.Module):
def __init__(self, embed_dim, num_heads, mlp_ratio=4.0, dropout=0.0):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(
embed_dim, num_heads,
dropout=dropout, batch_first=True
)
hidden_dim = int(embed_dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
x = x + self.attn(self.norm1(x), self.norm1(x), self.norm1(x))[0]
x = x + self.mlp(self.norm2(x))
return x
2.3.2 Encoder 结构图
输入: (B, N+1, D)
↓
┌───────────────────────────────────────┐
│ ┌─────────────────────────────────┐ │
│ │ Layer Normalization │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ Multi-Head Self-Attention │ │
│ └─────────────────────────────────┘ │
│ ↓ ↑ │
│ + ←──────────┘ (Residual) │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ Layer Normalization │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ MLP (FFN + GELU) │ │
│ └─────────────────────────────────┘ │
│ ↓ ↑ │
│ + ←──────────┘ (Residual) │
└───────────────────────────────────────┘
↓
输出: (B, N+1, D)
重复 L 次
2.4 分类头
2.4.1 标准 MLP Head
class ClassificationHead(nn.Module):
"""ViT 原始论文的分类头"""
def __init__(self, embed_dim, num_classes):
super().__init__()
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
return self.head(x) # x: CLS token 的输出 (B, D)
在预训练后微调阶段,也可以在线性层前加入隐藏层(LayerNorm → Linear → GELU → Linear),以提升分类头的表达能力。
2.4.2 全局平均池化(替代方案)
另一种做法是不使用 CLS Token,而是对所有 patch token 取全局平均池化(GAP)作为图像表示,再送入分类头。这种方式更简单且无需额外参数,但会丢失位置信息。
| 方法 | 优点 | 缺点 |
|---|---|---|
| CLS Token | BERT 预训练兼容、位置中立 | 需要额外参数 |
| GAP | 简单、无额外参数 | 丢失位置信息 |
2.5 完整 ViT 实现
import torch
import torch.nn as nn
class ViT(nn.Module):
"""Vision Transformer 完整实现"""
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.0,
dropout=0.0,
):
super().__init__()
self.patch_embed = nn.Conv2d(
in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size
)
num_patches = (img_size // patch_size) ** 2
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(dropout)
self.blocks = nn.Sequential(*[
TransformerEncoderBlock(embed_dim, num_heads, mlp_ratio, dropout)
for _ in range(depth)
])
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
self._init_weights()
def _init_weights(self):
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, x):
B = x.shape[0]
# Step 1: Patch Embedding — 卷积分块,输出空间特征图
x = self.patch_embed(x) # (B, D, H/P, W/P)
# Step 2: 展平空间维度,转为 token 序列格式
x = x.flatten(2).transpose(1, 2) # (B, N, D)
# Step 3: 将 CLS token 扩展到 batch 维并拼接到序列头部
cls_tokens = self.cls_token.expand(B, -1, -1) # (B, 1, D)
x = torch.cat([cls_tokens, x], dim=1) # (B, N+1, D)
# Step 4: 叠加位置编码,注入空间位置信息
x = x + self.pos_embed
x = self.pos_drop(x) # Dropout 正则化
# Step 5: 通过 L 层 Transformer Encoder 提取特征
x = self.blocks(x) # (B, N+1, D)
# Step 6: 最终 LayerNorm
x = self.norm(x)
# Step 7: 取 CLS token 的输出(index=0),通过线性分类头
return self.head(x[:, 0]) # (B, num_classes)
2.6 ViT 模型配置
2.6.1 标准配置
| 模型 | Layers | Hidden | Heads | MLP | Params |
|---|---|---|---|---|---|
| ViT-Ti (Tiny) | 12 | 192 | 3 | 768 | 5.7M |
| ViT-S (Small) | 12 | 384 | 6 | 1536 | 22M |
| ViT-B (Base) | 12 | 768 | 12 | 3072 | 86M |
| ViT-L (Large) | 24 | 1024 | 16 | 4096 | 307M |
| ViT-H (Huge) | 32 | 1280 | 16 | 5120 | 632M |
2.6.2 模型命名规则
ViT-B/16
│ │
│ └── Patch 大小 (16×16)
└────── 模型规模 (Base)
2.6.3 配置说明
各模型变体的具体参数见上方 2.6.1 配置表格,实际使用时只需按表中数值实例化 ViT 类即可。
2.7 训练与微调
2.7.1 数据增强
ViT 对数据增强很敏感,常见策略包括:
- RandomResizedCrop(随机裁剪缩放到 224×224)
- RandomHorizontalFlip(随机水平翻转)
- AutoAugment / RandAugment(自动增强策略)
- Normalize(ImageNet 均值方差标准化)
2.7.2 正则化技术
| 技术 | 作用 |
|---|---|
| Dropout | 随机丢弃神经元 |
| DropPath | 随机丢弃整个层(Stochastic Depth) |
| Label Smoothing | 软化标签,防止过拟合 |
| Mixup/CutMix | 数据混合增强 |
2.7.3 学习率调度
2.7.3.1 Cosine Annealing with Warmup
ViT 训练通常采用先 warmup 再余弦退火的学习率调度:前 5 个 epoch 线性升温到基础学习率(如 1e-3),之后按余弦曲线衰减至最小值(如 1e-5),总训练轮数一般为 300 epoch。
2.8 小结
| 组件 | 设计选择 |
|---|---|
| Patch Embedding | 16×16 卷积,stride=16 |
| 位置编码 | 可学习的 1D 位置编码 |
| Encoder | Pre-Norm,GELU 激活 |
| 分类 | CLS Token + 线性层 |
3. 关键变体与演进
3.1 变体概览
ViT 的后续工作主要围绕三个方向展开:数据效率、层级结构、自监督预训练。
具体来说:DeiT 解决的是"没有海量标注数据时如何训练 ViT"的问题;Swin Transformer 和 PVT 引入层级特征图和线性复杂度注意力,使 ViT 能胜任检测、分割等密集预测任务;MAE 和 BEiT 则探索无标签自监督预训练,让模型从原始图像中学习通用视觉表征。理解这三条线索,有助于在后续章节中判断不同视觉编码器为何适合不同的下游场景。
3.2 ViT 的局限性
原始 ViT 的几个关键问题:
| 问题 | 描述 |
|---|---|
| 数据饥渴 | 需要 JFT-300M 等超大数据集才能超越 CNN |
| 计算复杂度 | O(n²) 的注意力机制,高分辨率图像计算量较大 |
| 缺乏层级特征 | 单一分辨率,不适合检测、分割等密集任务 |
| 位置编码限制 | 固定分辨率,难以处理可变尺寸输入 |
3.3 DeiT:数据高效的训练策略
ViT 的数据瓶颈能否不靠海量数据来解决?DeiT 的答案是:用已有的 CNN 模型做"教师",通过知识蒸馏把 CNN 积累的归纳偏置传授给 ViT,在 ImageNet-1K 规模下就能训练出有竞争力的模型。
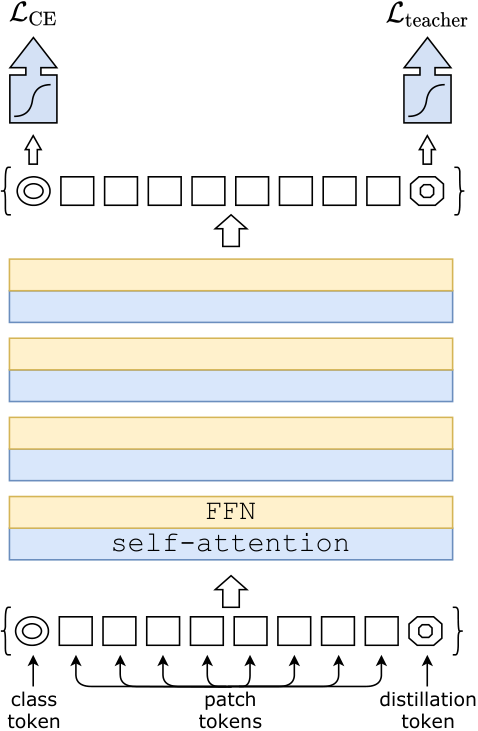
3.3.1 核心贡献
DeiT 证明了只用 ImageNet-1K 也能训练出有竞争力的 ViT。
关键点:
- 知识蒸馏:用 CNN 教师模型指导 ViT 学生模型
- 强数据增强:RandAugment、Mixup、CutMix
- 正则化:Stochastic Depth、Label Smoothing
3.3.2 蒸馏 Token
输入序列: [CLS, Distill, P1, P2, ..., P196]
↑ ↑
分类 蒸馏
Token Token
# DeiT 关键设计:在 CLS token 之外新增一个蒸馏 token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# forward 中的核心逻辑
x = torch.cat([cls_tokens, dist_tokens, x], dim=1) # 拼接 CLS + Distill + Patches
cls_output, dist_output = x[:, 0], x[:, 1] # 分别取两个特殊 token 的输出
# 训练时分别计算分类损失和蒸馏损失;推理时取两者预测的平均
3.3.3 训练策略
3.3.3.1 蒸馏损失
蒸馏损失由两部分加权组成:hard loss 是学生预测与真实标签之间的交叉熵;soft loss 是学生与教师的 softmax 输出(经温度 T 软化)之间的 KL 散度,乘以 T² 以补偿梯度缩放。最终损失为 α · hard_loss + (1-α) · soft_loss,其中 α 控制两者的权重比例。
3.3.4 DeiT 成果
| 模型 | ImageNet Top-1 | 参数量 | 训练数据 |
|---|---|---|---|
| DeiT-Ti | 72.2% | 5M | ImageNet-1K |
| DeiT-S | 79.8% | 22M | ImageNet-1K |
| DeiT-B | 81.8% | 86M | ImageNet-1K |
| DeiT-B (蒸馏) | 83.4% | 86M | ImageNet-1K |
3.4 Swin Transformer:层级化与窗口注意力
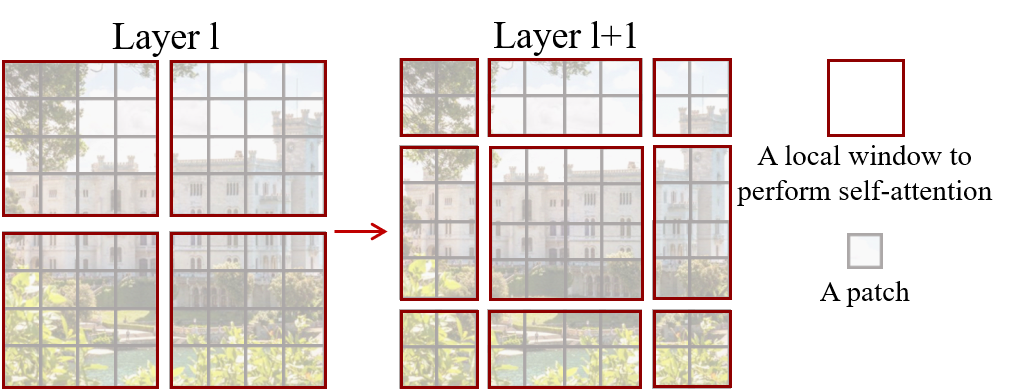
3.4.1 核心创新
Swin Transformer 主要解决了 ViT 的两类问题:
- 使用层级特征图,逐层降采样
- 使用窗口注意力,把复杂度从 O(n²) 降到 O(n)
3.4.2 架构对比
ViT 架构:
输入 → [Patch 196个] → Transformer × 12 → 输出
固定分辨率 全局注意力
Swin Transformer 架构:
输入 → Stage 1 (56×56) → Stage 2 (28×28) → Stage 3 (14×14) → Stage 4 (7×7)
窗口注意力 Patch 合并 窗口注意力 窗口注意力
3.4.3 窗口注意力
# WindowAttention 伪代码
# 1. 将特征图划分为 M×M 的不重叠窗口
# 2. 在每个窗口内独立计算多头自注意力
Q, K, V = linear(x).chunk(3) # 线性投影得到 Q/K/V
attn = softmax(Q @ K.T / sqrt(d) + rel_pos_bias) # 注意力 + 相对位置偏置
out = attn @ V # 加权聚合
# 3. 相邻层交替使用常规窗口和移动窗口(shifted window)
# 移动窗口使不同窗口之间能够交换信息
复杂度对比:
- 全局注意力:O((HW)²)
- 窗口注意力:O(HW × M²),其中 M 为窗口大小
3.4.4 移动窗口
Layer L (常规窗口): Layer L+1 (移动窗口):
┌───┬───┬───┬───┐ ┌─┬───┬───┬───┬─┐
│ 1 │ 1 │ 2 │ 2 │ │ │ │ │ │ │
├───┼───┼───┼───┤ ├─┼───┼───┼───┼─┤
│ 1 │ 1 │ 2 │ 2 │ → │ │ A │ A │ B │ │
├───┼───┼───┼───┤ ├─┼───┼───┼───┼─┤
│ 3 │ 3 │ 4 │ 4 │ │ │ A │ A │ B │ │
├───┼───┼───┼───┤ ├─┼───┼───┼───┼─┤
│ 3 │ 3 │ 4 │ 4 │ │ │ │ │ │ │
└───┴───┴───┴───┘ └─┴───┴───┴───┴─┘
移动 (M/2, M/2)
3.4.5 Patch Merging
Patch Merging 的作用类似于 CNN 中的下采样:它将相邻 2×2 的 Patch 在通道维度上拼接(维度变为 4C),再通过一个线性层降维到 2C,从而使空间分辨率减半、通道数翻倍。这一操作在每个 Stage 之间执行,构建出类似 FPN 的多尺度特征金字塔。
3.4.6 Swin 模型配置
| 模型 | 层数 [C, 隐藏维度] | 参数量 | ImageNet |
|---|---|---|---|
| Swin-T | [2,2,6,2], C=96 | 29M | 81.3% |
| Swin-S | [2,2,18,2], C=96 | 50M | 83.0% |
| Swin-B | [2,2,18,2], C=128 | 88M | 83.5% |
| Swin-L | [2,2,18,2], C=192 | 197M | 86.4% |
3.5 MAE:掩码自编码器
ViT 的基本结构已经清楚了,但结构只是一半——另一半是"如何训练"。DeiT 解决的是有标签数据不足的问题,而现实中更大的瓶颈往往是标注本身:标注数百万张图片耗时费力。自监督预训练提供了另一条路:让模型从无标签图像中自己学习结构性知识。预训练方式决定了 ViT 学到什么类型的特征,这直接影响在 VLA 中的适用性——接下来介绍视觉领域最具影响力的自监督预训练方案 MAE,以及它为何在需要空间细节的机器人任务中格外出色。
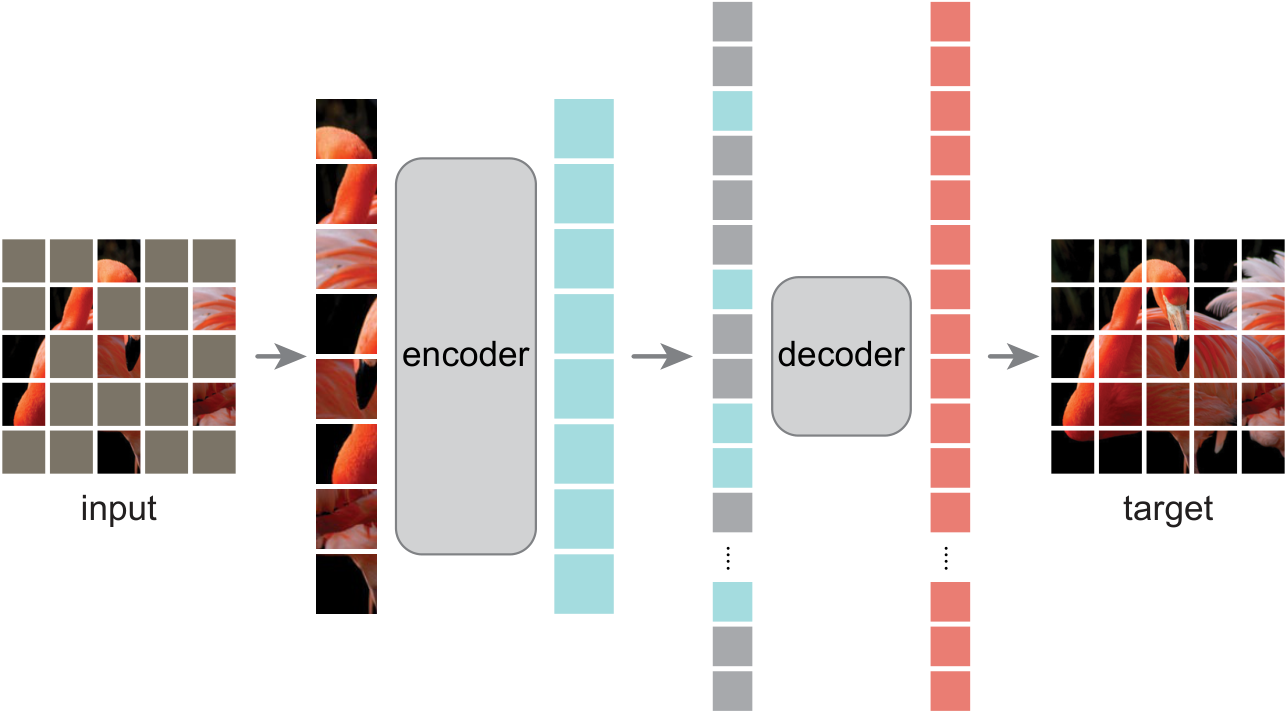
3.5.1 核心思想
MAE 将 NLP 的掩码预训练迁移到视觉领域:
- 随机遮挡 75% 的 Patch
- Encoder 只处理可见 Patch
- Decoder 重建被遮挡的 Patch
3.5.2 为什么 75% 这么高?
| 模态 | 掩码比例 | 原因 |
|---|---|---|
| 文本 (BERT) | 15% | 语言有强语义依赖 |
| 图像 (MAE) | 75% | 图像冗余高,需要更高难度 |
3.5.3 架构设计
原始图像 (196 Patches)
↓
随机遮挡 75% (保留 49 Patches)
↓
┌─────────────────────┐
│ ViT Encoder │ ← 只处理可见 Patch
│ (大,深) │
└─────────────────────┘
↓
添加 Mask Tokens (回到 196)
↓
┌─────────────────────┐
│ 轻量 Decoder │ ← 重建所有 Patch
│ (小,浅) │
└─────────────────────┘
↓
重建像素值
3.5.4 代码实现
# MAE 核心逻辑伪代码
# 1. Random Masking — 随机保留 25% 的 Patch
noise = torch.rand(B, N)
ids_keep = argsort(noise)[:, :N*0.25]
x_visible = gather(patches, ids_keep) # 只保留可见 Patch
# 2. Encoder — 只处理可见 Patch(大幅节省计算)
x_encoded = vit_encoder(x_visible) # 大而深的 ViT Encoder
# 3. Decoder — 补回 mask token,重建所有 Patch
mask_tokens = learnable_mask_token.repeat(N*0.75)
x_full = concat(x_encoded, mask_tokens) # 恢复到完整序列
x_full = reorder(x_full, ids_restore) # 按原始位置排列
x_decoded = lightweight_decoder(x_full) # 小而浅的 Decoder
pixel_pred = linear(x_decoded) # 预测每个 Patch 的像素值
3.5.5 损失函数
MAE 的损失函数为均方误差(MSE),仅在被遮挡的 Patch 位置上计算预测像素值与真实像素值之间的重建误差,可见 Patch 不参与损失计算。
3.5.6 MAE 的优势
| 优势 | 说明 |
|---|---|
| 训练效率高 | 只处理 25% 的 Patch |
| 强表示学习 | 高遮挡率迫使模型学习全局语义 |
| 无需标签 | 自监督预训练,数据成本低 |
| 迁移能力强 | 下游任务微调效果优秀 |
3.6 其他重要变体
3.6.1 CvT(Convolutional Vision Transformer)
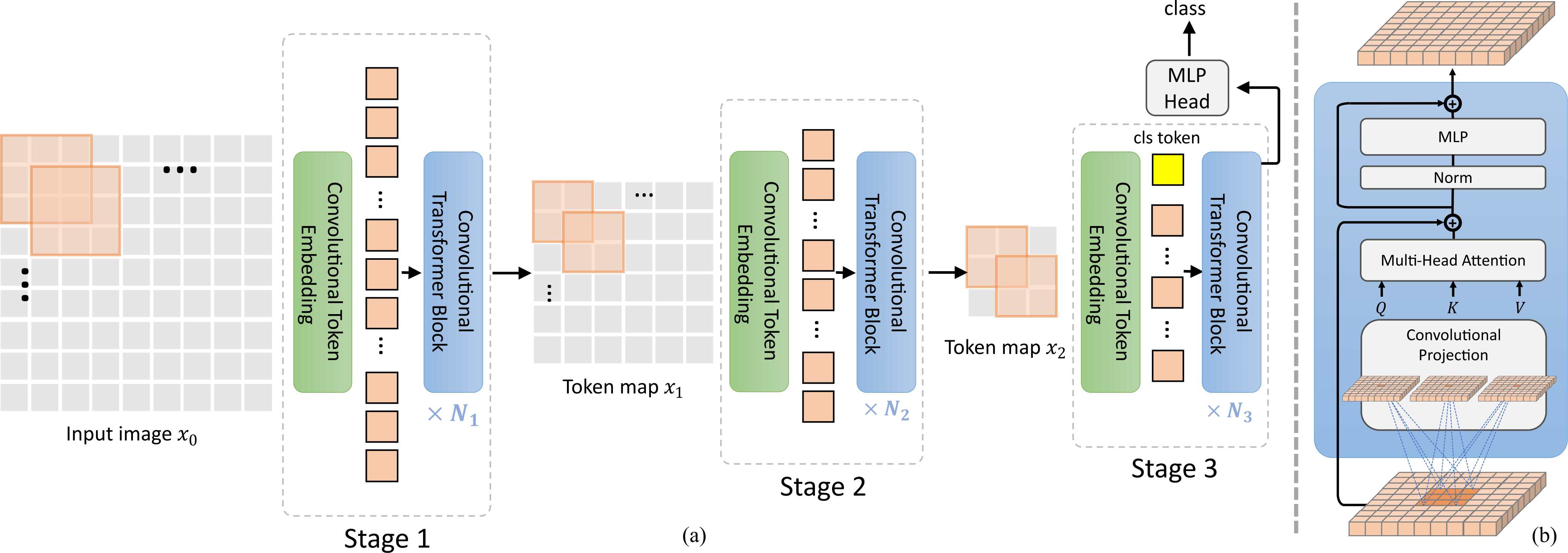
CvT 的核心思路是用卷积替代 ViT 中的线性投影:Patch Embedding 阶段使用多层卷积(如 7×7 + 3×3)逐步降采样,而非一步到位的大 stride 卷积;在注意力模块内部,Q/K/V 的投影也替换为深度可分离卷积(depthwise conv),从而在不增加太多计算量的前提下引入局部归纳偏置。这种设计让 CvT 在小数据集上的表现优于原始 ViT。
3.6.2 PVT(Pyramid Vision Transformer)
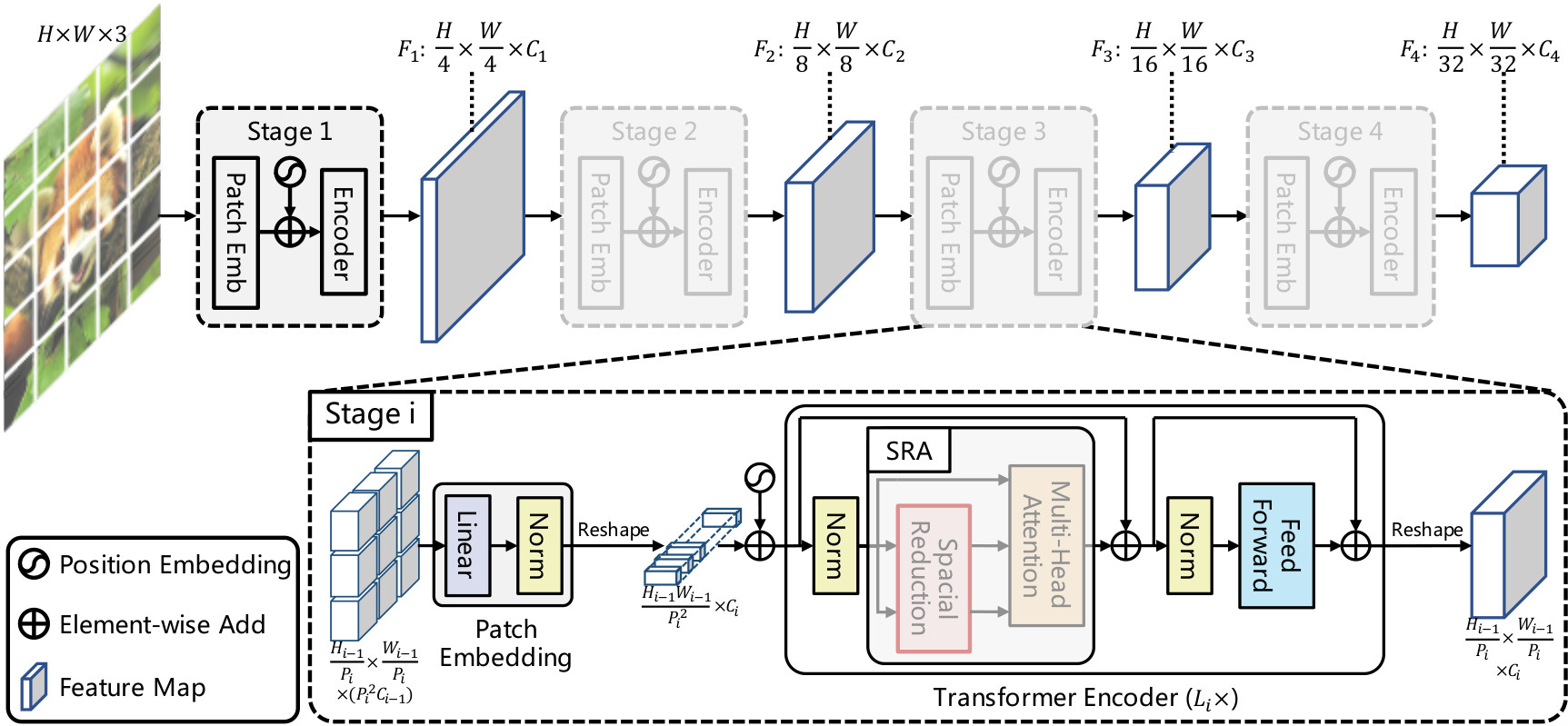
| Stage | 分辨率 | Token 数 | 通道数 |
|---|---|---|---|
| 1 | H/4 × W/4 | 3136 | 64 |
| 2 | H/8 × W/8 | 784 | 128 |
| 3 | H/16 × W/16 | 196 | 320 |
| 4 | H/32 × W/32 | 49 | 512 |
3.6.3 CrossViT
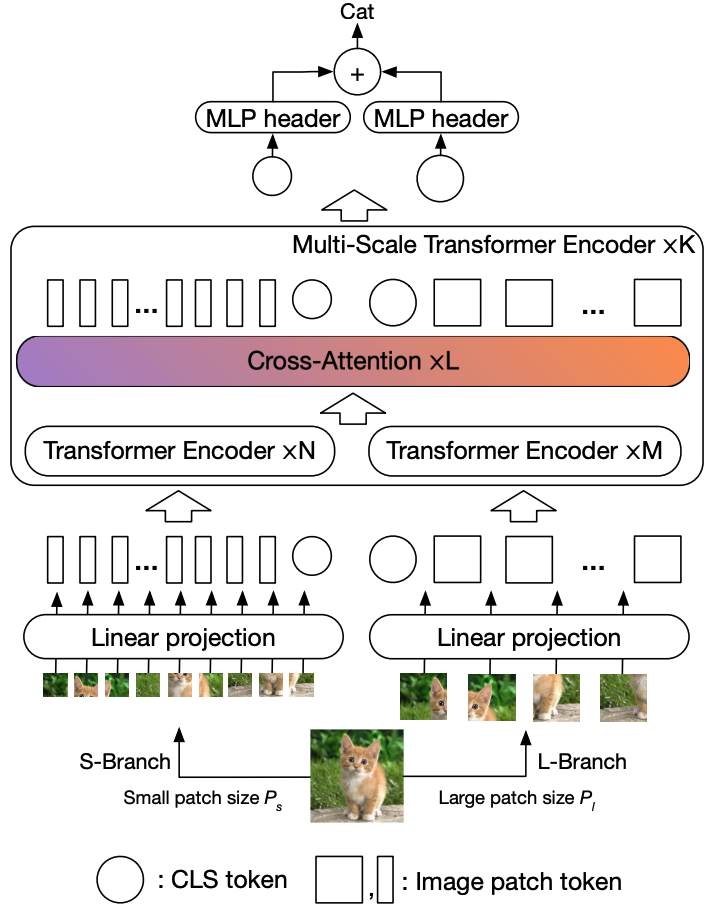
┌─────────────────┐ ┌─────────────────┐
│ 小 Patch 分支 │ │ 大 Patch 分支 │
│ (细粒度特征) │ ←→ │ (粗粒度特征) │
│ Patch=12×12 │ │ Patch=16×16 │
└─────────────────┘ └─────────────────┘
│ │
└──────── CLS 融合 ────┘
3.6.4 BEiT(BERT Pre-training of Image Transformers)
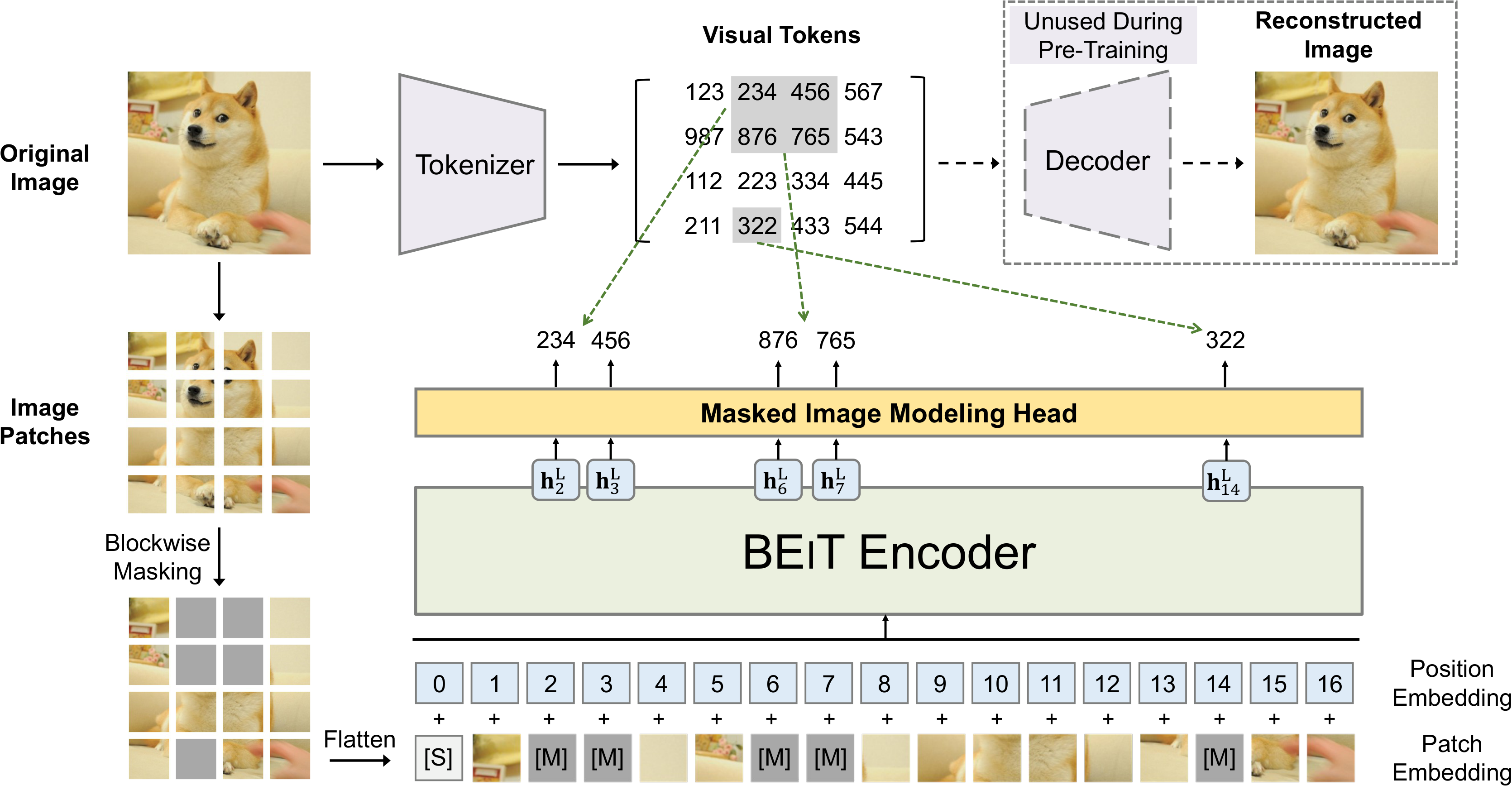
1. 使用 dVAE 将图像编码为离散 Token
2. 随机遮挡部分 Patch
3. 预测被遮挡位置的 dVAE Token(而非像素)
3.7 变体对比总结
| 模型 | 核心创新 | 解决的问题 | 计算复杂度 |
|---|---|---|---|
| ViT | Patch + Transformer | 开创性工作 | O(n²) |
| DeiT | 知识蒸馏 + 数据增强 | 减少数据依赖 | O(n²) |
| Swin | 窗口注意力 + 层级结构 | 高分辨率 + 密集任务 | O(n) |
| MAE | 高比例掩码 + 自监督 | 无标签预训练 | O(n²) |
| PVT | 金字塔特征 | 密集预测任务 | O(n) |
| CvT | 卷积增强 | 引入归纳偏置 | O(n²) |
3.8 如何选择?
| 场景 | 推荐模型 |
|---|---|
| ImageNet 分类 | DeiT / ViT |
| 目标检测 / 分割 | Swin Transformer |
| 自监督预训练 | MAE / BEiT |
| 小数据集 | DeiT (蒸馏) / CvT |
| 高分辨率图像 | Swin / PVT |
4. 与 VLA 的连接
学完整章 ViT,有必要显式地看一下这些知识在具身智能中的落地方式。
ViT 是 VLA 视觉编码器的基础结构。 当前主流视觉编码器——CLIP、SigLIP、DINOv2——全部基于 ViT,它们的区别在于预训练目标,而非网络骨干。理解 ViT 的分块机制、注意力结构和位置编码,是读懂后续 VLM/VLA 论文的前提。
Patch 大小直接影响推理成本。 Patch 大小决定了视觉 token 数量,进而决定 LLM 需要处理的序列长度。以 ViT-L/14 为例,224×224 输入产生 256 个视觉 token;若用 448×448 高分辨率,token 数翻至 1024,LLM 的计算量随之急剧上升。这是 VLA 在部署时必须面对的工程权衡。
CLS token vs 全 patch token。 分类任务只需 CLS token,但 VLA 的操控任务需要精确的空间定位信息(“哪个 patch 对应桌面上的杯子”)。因此 VLA 通常将全部 patch token 送入语言模型,而不只取 CLS——这一设计选择使视觉 token 数量成为系统瓶颈之一。
预训练方式决定特征类型,进而影响任务适配性。 MAE 预训练的 ViT 擅长保留局部空间细节,更适合需要精细操控的机器人任务;CLIP/SigLIP 的对比预训练赋予特征强语义对齐能力,更适合指令理解和跨模态检索。实践中,VLA 往往在 CLIP/SigLIP 编码器上继续用 MAE 风格目标微调,以兼顾语义与空间两类能力。
5. 参考资料
5.1 ViT 与实现
5.2 变体论文
- DeiT: Training data-efficient image transformers
- Swin Transformer
- Masked Autoencoders Are Scalable Vision Learners
- CvT: Introducing Convolutions to Vision Transformers
- PVT: Pyramid Vision Transformer
- CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
- BEiT: BERT Pre-Training of Image Transformers