6. 从 VLM 到 VLA
本章不再重复"视觉编码器如何工作"或"图文如何对齐",而是聚焦 VLA 的三个增量能力:动作表示、时序建模、策略学习。主线目标只有一个:把"看懂并回答"过渡到"理解并执行"。
1. 问题背景:从理解到执行
你现在已有的资料已经能回答下面三个问题:
- 图像如何变成 token
- 视觉特征如何接入 LLM
- 图像和语言如何对齐
但 VLA 比普通 VLM 多出来的关键问题是:
- 模型输出的不再是自然语言,而是机器人动作
- 当前一帧通常不够,模型需要利用历史观测与时序信息
- 训练目标不只是"回答对",而是"动作可执行、轨迹稳定、误差不累积"
2. VLM 与 VLA 的能力边界
| 维度 | VLM | VLA |
|---|---|---|
| 输入 | 图像 + 文本 | 图像/多帧 + 文本 + 可选状态 |
| 输出 | 文本 token | 动作 token 或连续动作 |
| 目标 | 看懂、描述、问答 | 决策、控制、执行 |
| 关键难点 | 多模态对齐 | 动作表示 + 时序建模 + 策略学习 |
可以把关系理解成:
VLM 解决"能不能理解图像和指令"
VLA 还要解决"接下来该怎么动"
因此学习 VLA 时,除了视觉编码器和 LLM 主干,还必须同时关注动作头与时序窗口设计。
3. 动作表示:从"文本输出"到"控制输出"
3.1 动作表示的重要性
VLA 的输出不是一句文本,而是机器人控制量,例如:
- 机械臂末端位姿增量
- 抓手开合
- 多步动作序列
动作表示方式会直接影响:
- 能否复用 LLM 的生成能力
- 控制精度够不够
- 训练是否稳定
3.2 三类常见方案
| 方案 | 核心思想 | 代表方向 | 优点 | 局限 |
|---|---|---|---|---|
| 动作 token 化 | 把连续动作离散成 token | RT-2、OpenVLA | 直接复用 LLM 序列建模 | 有量化误差 |
| 连续回归头 | 在主干后直接回归动作值 | 部分 VLA / policy 方法 | 精度更高 | 不能完全复用 LLM 词表 |
| 分布式动作建模 | 用 chunk 或扩散方式建动作分布 | ACT、Diffusion Policy、Octo 风格方法 | 更适合多峰动作与长时序 | 结构更复杂 |
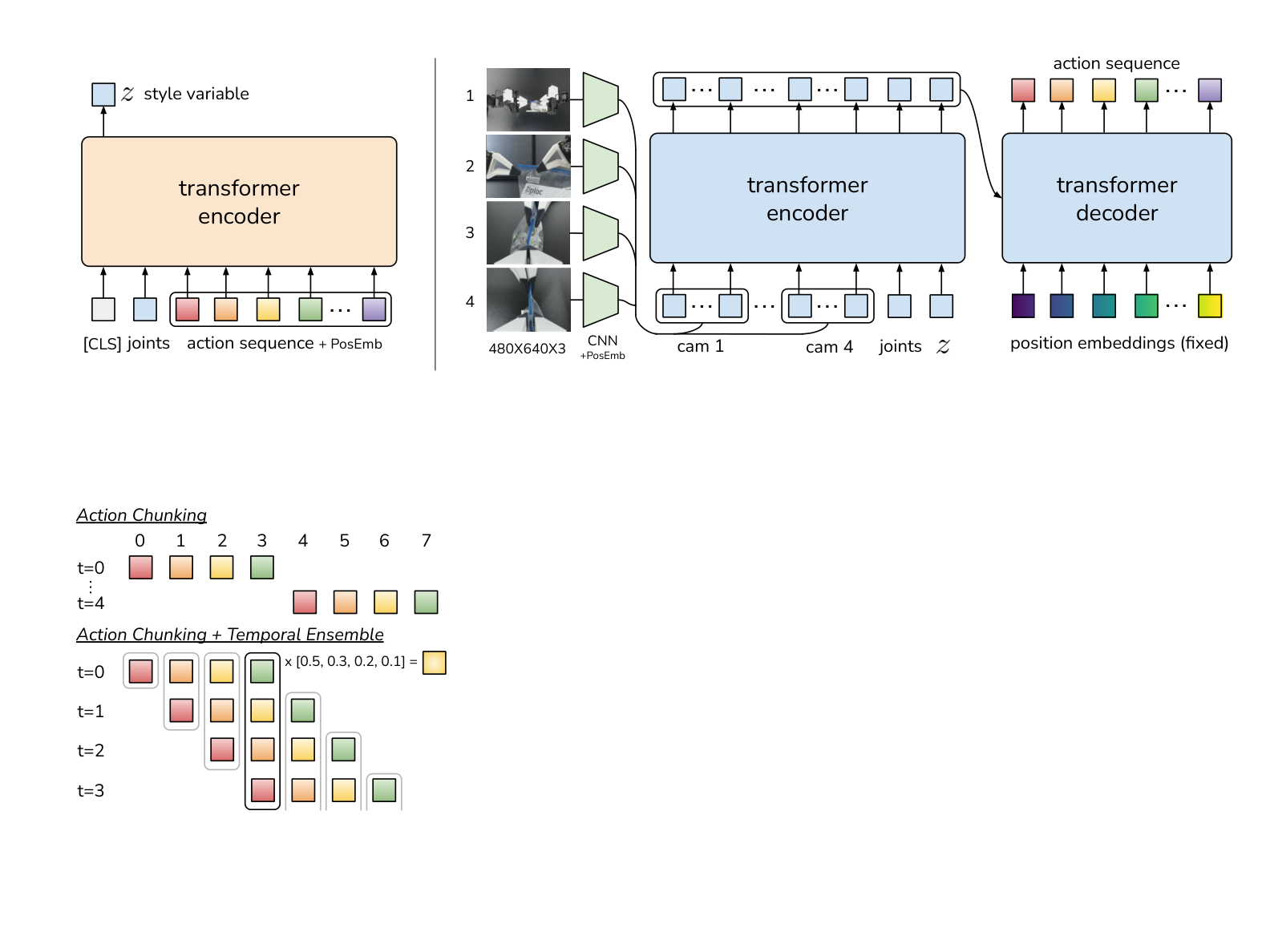
3.3 ACT:多步动作预测的稳定化方案
ACT 严格说不是典型 VLM,也不是标准 VLA 主干,但它精准回答了 VLA 训练中的一个关键问题:
如果动作是连续的,而且一步一步预测会累积误差,
那能不能一次预测一小段动作?
一步一预测的误差累积机制
想象机器人要把杯子从 A 移到 B,需要 20 步动作:
理想轨迹:A → p1 → p2 → p3 → ... → B
一步一预测的问题:
步骤1:预测 p1,有小误差 → 实际到达 p1'(偏了一点)
步骤2:以 p1' 为输入预测 p2,误差叠加 → 到达 p2''(偏更多)
步骤3:误差继续累积...
步骤20:可能已经完全偏离目标
ACT 的解决方案:Action Chunking(动作分块)
输入:当前观测 + 历史 K 帧
↓
Transformer 编码器
↓
一次输出:未来 K 步动作序列 [a_t, a_{t+1}, ..., a_{t+K-1}]
- 每次预测一个"动作块"(chunk),而不是单步动作
- 执行完这 K 步后,再重新观测、重新预测
- 误差不会在 K 步内累积,因为每 K 步都会"重置"
CVAE 结构:风格编码与动作还原
ACT 的核心模型结构是一个条件变分自编码器(CVAE),它由编码器和解码器两部分组成,理解这两个部分是理解 ACT 的关键。
编码器的作用:压缩"风格信息"
训练阶段,编码器接收专家演示中的完整动作序列作为输入,将其压缩为一个隐变量
训练阶段(编码器路径):
专家动作序列 [a_0, a_1, ..., a_K]
↓
Transformer 编码器
↓
隐变量 z(均值 μ 和方差 σ,即 KL 正则化的瓶颈)
编码器通过 KL 散度约束,把
解码器的作用:根据观测还原动作序列
解码器(实际上是一个 Transformer)接收两个输入:
- 当前观测(图像特征 + 机器人关节状态)
- 隐变量 z(从编码器获取,或推理时随机采样)
然后输出未来 K 步的完整动作序列:
推理阶段(解码器路径):
当前观测(图像 + 关节角度)+ z ~ N(0, I)
↓
Transformer 解码器(交叉注意力融合观测与 z)
↓
预测动作序列 [â_0, â_1, ..., â_K]
整个 CVAE 结构让 ACT 能够在推理时对多种合理动作进行隐式采样,而不是只回归一个均值动作。
时序集成(Temporal Ensembling):平滑多次预测
ACT 还提出了一种在执行阶段的技巧:时序集成。
由于 ACT 每隔一个 chunk 才重新预测,在相邻 chunk 之间存在"跳跃感"。时序集成的做法是:
- 每个时间步都运行一次 ACT,得到一组预测动作序列
- 对当前时刻,把多次预测中该时刻的动作加权平均(越新的预测权重越高)
- 用加权平均值作为最终执行的动作
时刻 t 的实际执行动作 = 加权平均(
在 t-K+1 时刻预测的 a_t,
在 t-K+2 时刻预测的 a_t,
...
在 t 时刻预测的 a_t,
权重递增(越新的预测权重越大)
)
这种方法的好处是:即使单次预测存在抖动,多次预测的加权平均会更平滑、更稳定,机械臂的运动会更连贯自然。
ACT 前向流程伪代码
# ACT 推理阶段前向流程(简化版)
def act_inference(image_obs, joint_state, chunk_size=50):
# 1. 视觉编码:将图像转为视觉特征 token
visual_tokens = vision_encoder(image_obs) # [N_patch, D]
# 2. 构建观测 token:拼接视觉特征与关节状态
joint_token = linear_proj(joint_state) # [1, D]
obs_tokens = concat([visual_tokens, joint_token]) # [N+1, D]
# 3. 从先验分布采样风格隐变量 z(推理时无专家动作)
z = sample_from_normal(mean=0, std=1) # [D_z]
# 4. 构建解码器输入:chunk_size 个动作查询 + z 嵌入
action_queries = learned_embeddings(chunk_size) # [K, D]
z_embed = linear_proj(z).unsqueeze(0) # [1, D]
decoder_input = concat([z_embed, action_queries]) # [K+1, D]
# 5. Transformer 解码器:以观测 token 为 key/value 做交叉注意力
decoded = transformer_decoder(
query=decoder_input,
key=obs_tokens,
value=obs_tokens
) # [K+1, D]
# 6. 输出层:将解码结果映射到动作空间
pred_actions = action_head(decoded[1:]) # [K, action_dim]
return pred_actions # 返回未来 K 步动作序列
ACT 与普通行为克隆(BC)的关键区别
普通行为克隆(Behavior Cloning, BC)的做法是:把专家演示当作监督数据,让模型在每个时刻直接回归专家的单步动作。这种方式有两个根本缺陷:一是单步预测在闭环执行中会迅速累积误差;二是面对多峰分布时会输出"平均动作",即哪种方案都不像的折中结果。
ACT 通过两个机制解决了这两个问题:动作分块让每 K 步重置一次误差,CVAE 的隐变量让模型能够学习风格多样的动作分布而非简单地回归均值。换句话说,ACT 不是在问"在这个状态下该怎么动",而是在问"我这次选择什么风格的动作策略,然后在这个风格下接下来 K 步该怎么动"——这是一个更符合人类操作直觉的建模框架。
3.4 Diffusion Policy:多峰动作分布建模
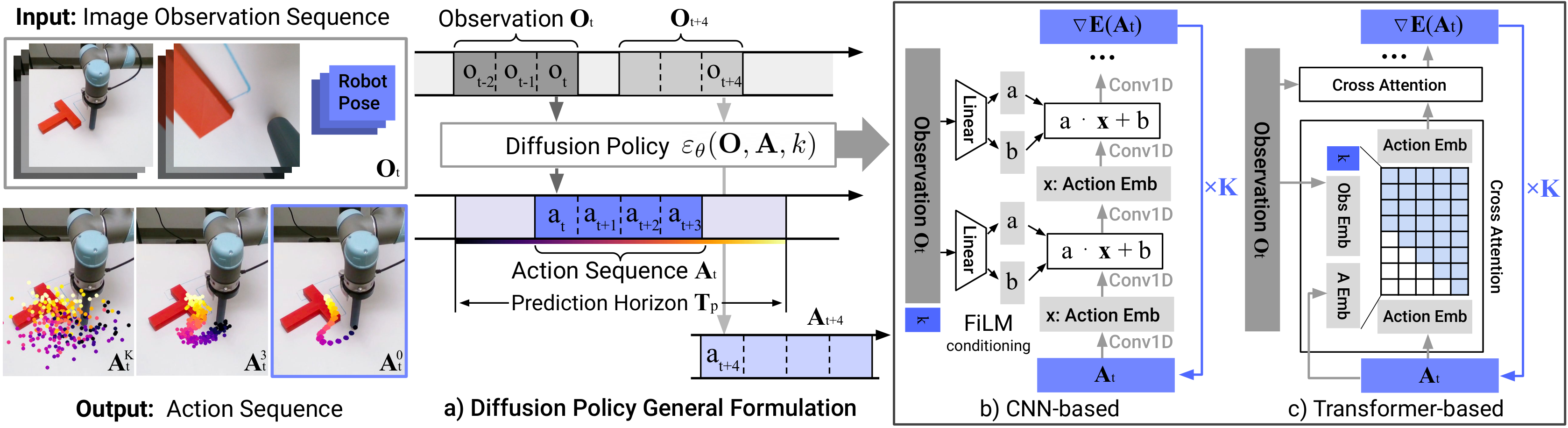
Diffusion Policy 也不属于传统 VLM 结构,但它提供了另一条非常重要的动作建模路径。
单点动作回归的局限
同一个场景下,可能存在多种合理的动作方式:
场景:桌上有一个杯子,指令"抓起杯子"
合理动作 A:从左边接近,正手抓
合理动作 B:从右边接近,反手抓
合理动作 C:从正面接近,双指捏
这三种都是正确的,但如果模型只输出一个动作值,
它会"平均"这三种方案 → 得到一个哪种都不像的奇怪动作
这就是多峰分布问题:动作空间不是单峰的(只有一个最优解),而是多峰的(多种合理方案)。
扩散过程的直觉说明
扩散模型分为两个过程,理解这两个方向是理解 Diffusion Policy 的关键:
正向过程(Forward Process):训练时加噪
训练阶段,我们有专家的真实动作序列。扩散模型的正向过程是把这个真实动作序列逐步加噪,直到它变成纯高斯噪声:
真实动作 a_0
↓ 加一点噪声
a_1(轻微扭曲的动作)
↓ 继续加噪
a_2(更模糊的动作)
↓ ...
a_T(几乎完全是随机噪声)
在每个噪声水平,模型学习预测"当前的动作被加了多少噪声",也就是学习去噪函数。注意,这里的条件输入(当前观测图像 + 语言指令)在整个加噪/去噪过程中始终作为额外信息输入,指导模型理解"该往哪个方向去噪"。
反向过程(Reverse Process):推理时去噪
推理阶段,我们不再有专家动作,只有当前的观测。此时:
从纯随机噪声出发:a_T ~ N(0, I)
↓ 去噪一步(条件:当前图像 + 语言指令)
a_{T-1}(稍微像个动作了)
↓ 继续去噪
a_{T-2}(越来越接近合理动作)
↓ ...
a_0(最终的预测动作序列)
为什么这天然支持多峰分布?
关键在于起点的随机性。每次推理时,我们从不同的随机噪声
噪声起点 z_1 → 去噪 → 从左边接近、正手抓(动作方案 A)
噪声起点 z_2 → 去噪 → 从右边接近、反手抓(动作方案 B)
噪声起点 z_3 → 去噪 → 从正面接近、双指捏(动作方案 C)
普通回归模型每次输出的是唯一的均值,而 Diffusion Policy 每次采样到不同的合理动作,三种动作方案都是"正确的",模型不会强迫自己取平均。
条件化机制:观测如何指导去噪
Diffusion Policy 的核心是条件去噪:去噪的每一步,都以当前观测(图像 token + 语言嵌入)为条件。实现上,通常有两种方式:
- 拼接条件:把图像特征和语言特征编码后,与噪声动作拼接在一起,送入去噪网络(U-Net 或 Transformer)
- 交叉注意力条件:去噪网络通过交叉注意力机制,在每一层都"查询"观测特征
两种方式的效果相近,但交叉注意力更自然地契合 Transformer 架构,因此在与 VLM 结合时更为常见。
去噪步骤 t 的条件化过程:
输入:
- 当前噪声动作 a_t (随噪声水平变化的动作)
- 噪声水平 t (告知模型当前"模糊程度")
- 观测编码 c = f(图像, 语言) (固定的条件信息)
去噪网络:
ε_θ(a_t, t, c) → 预测噪声 ε
更新:
a_{t-1} = 去噪更新(a_t, ε) (DDPM/DDIM 调度器)
均值回归 vs 分布采样:一个具体例子
假设机器人面前有两条路可以绕过障碍物——左边和右边都是正确的。
-
普通回归模型看了大量演示(50% 走左边,50% 走右边),最终输出"往正前方走"——这是两种策略的均值,但实际上这会撞上障碍物。模型"平均"了两种策略,得到了一个在现实中完全错误的动作。
-
Diffusion Policy 面对同样的数据,每次从不同随机噪声出发:一半情况去噪到"走左边",一半情况去噪到"走右边"。两种输出都是可执行的合理策略,模型不会"折中"出一个撞墙动作。
这个例子说明:分布采样相对于均值回归的优势,在多峰数据下尤为明显。
去噪过程文字示意图
推理阶段 Diffusion Policy 去噪流程:
观测输入(固定):
┌─────────────────────────────────┐
│ 图像 token + 语言嵌入(条件 c) │
└─────────────────────────────────┘
│
▼ 条件化(贯穿全程)
┌──────────────────────────────────────────────┐
│ │
│ a_T(纯随机噪声) │
│ │ │
│ ▼ 去噪步骤 T→T-1(去噪网络 + 条件 c) │
│ a_{T-1}(轮廓隐约可辨的动作序列) │
│ │ │
│ ▼ 去噪步骤 T-1→T-2 │
│ a_{T-2}(动作方向更清晰) │
│ │ │
│ ▼ ... 重复 T 步 ... │
│ │ │
│ ▼ 去噪步骤 1→0 │
│ a_0(最终预测:可执行的动作序列) │
│ │
└──────────────────────────────────────────────┘
这能帮助你理解为什么后续很多 VLA 或 policy 模型会采用更强的动作头,而不是只靠离散 token 或简单回归。
4. 时序建模:让模型理解"过程"
4.1 单帧输入的局限
只看当前一帧,很多任务根本无法判断该怎么做。以下是几个典型的失败场景:
场景一:物体在视野外
机器人正在执行"把红色杯子放到架子上"的任务。当机械臂举起杯子向上运动时,摄像头视野里可能只看到机械臂和杯子,架子已经不在画面中了。这时候单帧输入根本不知道"架子在哪",更无法判断当前是在接近还是远离目标位置。必须结合历史帧,才能知道"我刚才看到架子在左上方,现在应该继续向左上运动"。
场景二:运动方向判断
同一帧图像下,机械臂可能正在"接近杯子",也可能正在"远离杯子"——二者的静态姿态完全相同,区别只在于运动方向。如果没有相邻帧的对比,模型完全无法判断当前是哪种情况,也就无法做出正确的决策。
场景三:任务完成度判断
任务是"把三块积木叠起来"。完成第一步后(叠了两块),当前帧看到的是"两块叠在一起"。但模型需要知道:这是任务刚开始的状态,还是已经叠了一块正准备叠第二块?没有历史信息,模型无法知道自己处于任务的哪个阶段,也就不知道下一步该做什么。
场景四:抓取是否成功
机器人尝试抓杯子,下一步动作依赖于"有没有抓到"。但单帧图像里,抓手闭合的姿态和抓住了物体的姿态非常相似,必须结合力反馈或历史图像变化,才能判断是否成功。
这些例子说明:时序信息不是锦上添花,而是让任务可解的基础条件。
4.2 常见时序处理方式
| 方式 | 思路 | 代表现象 |
|---|---|---|
| 帧拼接 | 直接把多帧视觉 token 拼起来 | 实现简单,RT-2 常见 |
| 带时序编码的多帧输入 | 给不同时间帧加时间位置信息 | 更适合统一序列建模 |
| 动作 chunk | 一次生成多个未来动作 | ACT 风格,减轻逐步累积误差 |
| 分布式时序策略 | 建模未来动作轨迹分布 | Diffusion Policy / Octo 风格 |
方案详解
帧拼接(Frame Stacking)
最直觉的做法:把过去 N 帧的图像特征 token 全部拼接在一起,作为序列的一部分送入 Transformer。实现上极为简单,几乎不需要修改现有的 VLM 架构——只是让 context 变长了。
但代价是:token 数量随帧数线性增长。如果每帧产生 256 个视觉 token,历史 4 帧就是 1024 个 token,这对推理时延和显存都是压力。此外,帧拼接默认所有帧的权重相同,没有显式的时序先验——模型需要从位置编码中隐式学习时间顺序,效果不如带时序编码的方案稳定。
带时序编码的多帧输入
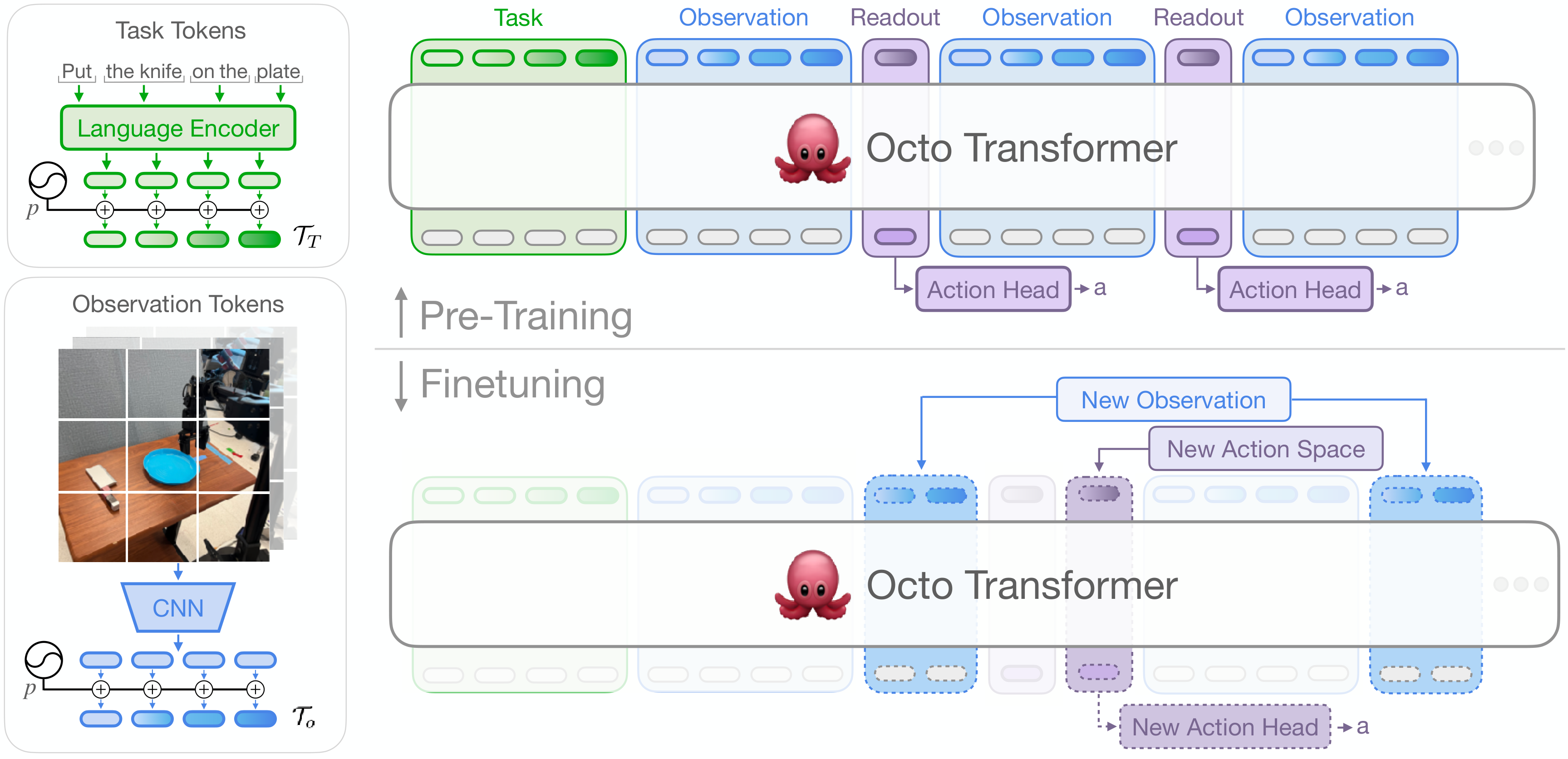
在帧拼接的基础上,给每一帧的视觉 token 加上时间步位置编码(类似 Transformer 中的位置编码,但编码的是"这是第几帧"而不是"这是第几个 patch")。这样模型能明确知道哪些 token 来自最近的帧,哪些来自更早的帧,时序信息从隐式变为显式。Octo 模型中就采用了类似的"observation token"加时序标识的方式,让 Transformer 能更好地理解时序关系。
历史动作作为上下文
除了历史图像,历史动作序列也是重要的上下文信息。把过去执行的动作
动作 Chunk(一次预测多步)
ACT 风格的方案,已在 Section 3.3 详细介绍。核心思路是:与其在每个时刻都重新决策,不如一次规划出未来 K 步,然后执行。这既减少了重复推理的开销,也避免了单步误差在闭环中的快速累积。
分布式时序策略(Trajectory-level Modeling)
Diffusion Policy 和 Octo 的做法更激进:直接对未来整条动作轨迹的分布建模,而不是只预测单个 chunk。这让模型能捕捉到轨迹级别的长程依赖,比如"前 5 步调整姿态、后 5 步精确插入"这类需要前后协调的任务模式。代价是模型结构更复杂,训练和推理成本也更高。
4.3 学习时序建模应优先抓住什么
第一轮学习不需要穷尽所有时序方法,但至少要牢固掌握下面两点:
- 历史观测是动作决策不可缺少的上下文
- 一步一预测容易在闭环执行中积累误差
5. 策略学习视角:统一理解 BC / ACT / Diffusion
5.1 VLA 的本质仍是策略学习
不管外面包了多少视觉和语言模块,最后 VLA 本质上仍然在学习一个策略:
观测 + 指令 + 历史 -> 动作
所以你需要理解最基本的策略学习视角:
- Behavior Cloning:直接学专家动作
- ACT:用 chunk 改善多步动作预测
- Diffusion Policy:学习动作分布
5.2 三类方法如何形成同一条技术线
三类方法并不是并列的"三种选择",而是有清晰的演进关系:每一种方法都是在前一种方法的缺陷上发展出来的。
第一步:Behavior Cloning(BC)—— 最简单的起点
BC 的思路最直接:收集专家演示数据,把它当成监督学习问题,让模型学会在每个观测下输出专家的动作。从 VLA 的角度看,这就是:把视觉编码器和 LLM 主干产生的隐藏状态,接一个线性层输出动作,用 MSE Loss 回归专家动作。
BC 的问题有两个:
- 协变量偏移(Covariate Shift):训练时都是专家的状态分布,执行时一旦犯错偏离,就到了从未见过的状态,后续决策会雪崩。
- 多峰问题:MSE 回归只能输出均值,面对多种合理动作时会输出"折中"的错误动作。
第二步:ACT —— 解决误差累积和分布学习
ACT 在 BC 基础上做了两个关键改进:
- 用动作分块解决协变量偏移——每 K 步重置一次,误差在小块内被隔离
- 用 CVAE 的隐变量隐式学习动作分布,避免直接回归均值
ACT 的局限:CVAE 的隐变量是低维的,能捕捉的分布复杂度有限;动作分块的 chunk 长度 K 也需要人工选择,太小效果差,太大执行灵活性低。
第三步:Diffusion Policy —— 用扩散过程建模完整分布
Diffusion Policy 将整个动作序列的生成视为一个去噪过程,用高维噪声空间代替 CVAE 的低维瓶颈,能够捕捉任意复杂的多峰分布。同时,由于去噪过程是迭代的,每一步都以观测为条件,模型可以对轨迹级别的长程依赖建模。
它的代价是推理时需要运行 T 次(通常 10~100 次)去噪步骤,延迟比 ACT 高。DDIM 等加速采样方法可以缓解这个问题,但在实时控制场景下依然是挑战。
| 方法 | 解决的核心问题 | 引入的新代价 |
|---|---|---|
| Behavior Cloning | VLA 训练最常见的基本范式 | 多峰问题、协变量偏移 |
| ACT | 动作分块 + CVAE 缓解上述两个问题 | 分布表达能力有限、K 需调 |
| Diffusion Policy | 完整的多峰分布建模,轨迹级依赖 | 推理延迟高、结构更复杂 |
它们不是多模态模型的"旁枝",而是 VLA 动作层的主线方法,理解这条演进线是读懂任何新 VLA 论文动作头设计的基础。
6. 从现有资料到 VLA 的学习路径
6.1 现有资料各自解决什么问题
| 当前资料 | 解决的问题 | 对 VLA 的作用 |
|---|---|---|
1.transformer.md | 注意力如何工作、Transformer 如何构成 | 建立 VLA 主干的统一计算范式 |
2.llm_and_generation.md | LLM 如何逐 token 生成 | 理解动作 token 化与自回归预测 |
3.vit_and_visual_representation.md | 图像如何切分与序列化 | 理解视觉 token 的来源与组织方式 |
4.visual_encoders_and_alignment.md | 视觉特征如何抽取并与语言空间对齐 | 理解 CLIP / SigLIP / DINOv2 与对齐机制 |
5.multimodal_fusion_and_vlm.md | 视觉如何接入 LLM 并完成跨模态融合 | 理解 projector / cross-attn / Q-Former 到 VLA 的输入接口 |
| 本文 | 动作和时序如何接进来 | 理解 VLM 到 VLA 的增量能力 |
6.2 一条更适合进入 VLA 论文的主线

Transformer
-> ViT
-> CLIP / SigLIP / DINOv2
-> LLaVA / Flamingo / BLIP-2
-> 动作 token / 连续动作 / action chunk / diffusion action
-> RT-2 / OpenVLA / Octo
7. VLA 论文阅读指南
7.1 阅读新 VLA 论文时先问的四个问题
读任何一篇新的 VLA 论文,只要能回答以下四个问题,就能快速建立起对这个模型的结构认知,而不会迷失在大量技术细节中。
问题一:视觉编码器用的是什么?
是 ViT-B/L、ViT-G,还是 SigLIP、DINOv2?是冻结(frozen)还是微调(fine-tuned)?冻结编码器能保留预训练的通用视觉表征,但可能缺乏对机器人场景的适应性;微调编码器表达能力更强,但需要更多数据和更高计算成本。
问题二:视觉与语言的融合方式是什么?
是用 projector(线性层或 MLP)把视觉 token 投影到语言空间,还是用 Q-Former 压缩视觉信息,还是用交叉注意力在每一层都融合?不同融合方式的计算量和效果差异显著。
问题三:动作表示是什么?
是把连续动作离散化为 token(能复用 LLM 的生成能力)、直接回归连续值(精度高但不能用 LLM 词表)、还是用 action chunk / diffusion 建模动作分布(更适合多峰和长时序)?这决定了模型的控制精度上限和训练难度。
问题四:时序信息如何处理?
输入是单帧还是多帧?历史帧如何融合(拼接 / 带时序编码 / 循环结构)?是否把历史动作也作为输入?这些选择决定了模型能否捕捉任务进展和运动方向。
7.2 用四个问题分析 RT-2
RT-2(Robotic Transformer 2,Google DeepMind,2023)是将大规模 VLM 直接迁移到机器人控制的代表性工作。
视觉编码器: RT-2 使用 PaLI-X 或 PaLM-E 的视觉主干(ViT 系列),并与语言主干一起在机器人数据上联合微调。这种做法使视觉编码器能够适应机器人场景,但计算成本极高,需要大规模 TPU 集群支持。
融合方式: RT-2 继承了 PaLI 的架构,视觉 token 直接与文本 token 拼接,共同送入统一的 Transformer 主干。没有额外的 projector 或 Q-Former,整体是一个端到端的序列到序列模型。
动作表示: 这是 RT-2 最具代表性的设计——把机器人的连续动作离散化为 256 个 bin 的 token,用 LLM 词表中已有的 token 表示(例如直接复用数字 token "0"~"255")。推理时 LLM 输出动作 token,再解码回连续控制量。这样完全复用了 LLM 的自回归生成能力,无需修改 LLM 主干。
时序建模: RT-2 主要以单帧图像为输入,时序信息较为有限,这是其主要局限之一。动作预测也是单步的,没有使用 action chunk,因此在精细操作任务上表现不如 ACT 等方案。
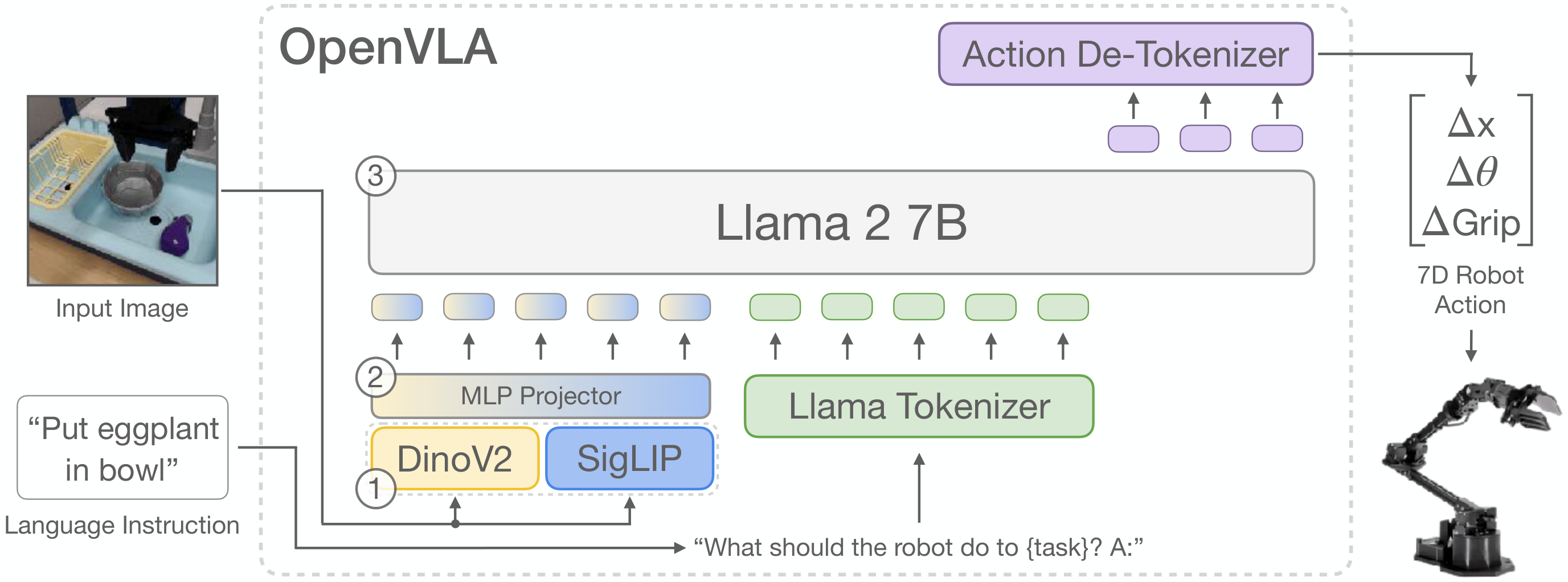
7.3 用四个问题分析 OpenVLA
OpenVLA(斯坦福 + UC Berkeley,2024)是开源 VLA 的代表,基于 LLaVA 架构构建,提供了完整的训练代码和权重。
视觉编码器: OpenVLA 使用 SigLIP + DINOv2 的双编码器组合,分别提取语义特征(SigLIP)和细粒度空间特征(DINOv2),然后拼接后送入 projector。这与 RT-2 的单一 ViT 相比,视觉表征更丰富,对精细操作任务有明显帮助。
融合方式: 采用 LLaVA 风格的线性 projector,将拼接后的视觉特征投影到语言空间,然后与语言 token 一起输入 LLM(Llama 2-7B)。这是最简单的融合方式,但在开源环境下已经取得了不错的效果。
动作表示: 与 RT-2 类似,OpenVLA 也将连续动作离散化为 token,每个动作维度量化为 256 个 bin,用 LLM 词表中未使用的特殊 token 表示(不直接复用数字 token,而是保留专用 token 空间)。这比 RT-2 的做法更干净,减少了语言 token 和动作 token 之间的干扰。
时序建模: OpenVLA 使用单帧图像输入,同样没有显式的时序建模。这是 OpenVLA 的主要局限,社区已有后续工作(如 OpenVLA-OFT)在此基础上加入了多帧输入和 action chunk,显著提升了精细操作能力。
通过对比 RT-2 和 OpenVLA 的四个问题答案,你可以清晰地看到:两者的动作表示哲学相似(都是 token 化),但视觉编码策略不同(单编码器 vs 双编码器),时序处理都是短板(都是单帧)。这种结构化对比,是快速理解新论文贡献的最高效方式。
8. 学习取舍建议
8.1 第一轮建议重点掌握
- Transformer
- ViT
- CLIP
- SigLIP
- DINOv2
- LLaVA
- Flamingo
- BLIP-2 / Q-Former
- ACT
- Diffusion Policy
- RT-2
- OpenVLA
- Octo
8.2 第一轮只需案例化了解
- Qwen-VL
- InternVL
- LLaVA-NeXT
- 各类更细的视觉 backbone 变体
这些模型值得知道,但不适合作为第一轮主线,因为它们更多是在已有路线上的工程增强或产品化扩展。
9. 融会贯通:从 Transformer 到 VLA 的完整知识链条
学完这个系列的全部 6 章,你已经积累了从底层计算原语到顶层系统架构的完整知识体系。现在让我们用一个具体任务把所有模块串联起来,看看每一章的知识在实际 VLA 系统中扮演什么角色。
任务:机器人抓起桌上的红色杯子
假设我们有一台搭载摄像头和机械臂的机器人,操作者对它说:"把桌上的红色杯子拿给我。"下面是一个完整的 VLA 系统如何处理这个任务的全流程:
第一步:图像变成 token(ViT 的工作)
摄像头拍到的 RGB 图像先被切成 16×16 的小 patch,每个 patch 通过线性映射变成一个向量,加上位置编码后组成 patch token 序列。这是第 3 章(ViT)的内容——把图像空间问题转化为序列建模问题,让 Transformer 能够处理图像。
第二步:视觉特征与语言语义对齐(CLIP/SigLIP 的工作)
光有 patch token 还不够,这些 token 需要能"理解"语言指令的含义——"红色"和"杯子"分别对应图像的哪些区域?这需要第 4 章(视觉编码器与对齐)介绍的对比学习预训练:CLIP 或 SigLIP 通过大规模图文对训练,让视觉空间和语言空间在同一个特征空间里对齐。这样,"红色杯子"这个语言查询,就能在视觉特征中找到对应的空间位置。
第三步:视觉 token 进入 LLM(LLaVA 式融合的工作)
对齐后的视觉特征还需要"送进"LLM 的注意力机制里,让 LLM 能同时处理图像信息和语言指令。第 5 章(多模态融合与 VLM)介绍了三种融合方式:projector(最简单)、Q-Former(压缩视觉信息)、交叉注意力(最深度融合)。LLaVA 用的是 projector——把视觉 token 投影到语言 embedding 空间,然后与语言 token 拼接。LLM 的注意力机制(第 1 章,Transformer)把"图像 token + 指令 token"作为一个统一序列来处理。
第四步:利用历史帧判断当前状态(时序建模的工作)
机器人开始移动手臂去抓杯子。随着手臂运动,当前帧的图像在不断变化,但单帧图像无法告诉模型"手臂是在接近还是远离杯子"。本章 Section 4(时序建模部分)介绍了如何把历史帧和历史动作编码后输入模型——结合过去 3 帧的图像变化,模型能判断手臂当前的运动趋势,并据此调整策略。
第五步:LLM 输出转为机械臂控制量(动作表示的工作)
LLM 处理完"视觉 + 语言 + 历史"的上下文后,需要输出控制信号。本章介绍了三种方案:动作 token 化(RT-2 风格)、连续回归头、以及 action chunk / diffusion。这些动作表示的选择决定了控制精度和训练稳定性。
第六步:稳定的多步动作规划(ACT/Diffusion 的工作)
与其一步一步地控制,ACT 一次预测未来 50 步的动作序列:手腕如何旋转、手指何时闭合、力度如何控制……执行这 50 步后再重新观测。Diffusion Policy 则从噪声出发,以当前视觉观测为条件,去噪出一条完整的抓取轨迹——能自然地选择"从哪个方向抓"这类多峰决策。
整体系统的一次推理流程:
摄像头图像(当前帧 + 历史 3 帧)
↓ ViT(第 3 章)
视觉 patch token
↓ SigLIP 对齐(第 4 章)
对齐后的视觉特征
↓ LLaVA projector(第 5 章)
视觉 token + 语言 token ["把桌上的红色杯子拿给我"] + 历史动作 token
↓ LLM Transformer 主干(第 1、2 章)
上下文融合后的隐藏状态
↓ 动作头(本章 Section 3)
未来 K 步动作序列(关节角度增量 × K 步)
↓ 执行器
机械臂完成抓取动作
这条链路里,每一个环节都对应你在这个系列中学过的一章内容。理解了这条链路,你就真正具备了阅读和理解任意 VLA 论文的基础——因为所有 VLA 论文,本质上都是在这个框架的某个或某几个环节上做出改进。
10. 学完本章后应具备的能力
读完本章,你应能明确回答:
- VLM 与 VLA 的能力边界与差异
- 动作表示方式如何影响性能上限
- ACT / Diffusion Policy 在动作层的核心定位
- BC → ACT → Diffusion Policy 的演进逻辑和各自解决的问题
- 阅读 VLA 论文时应同时检查的四个关键问题
- 用"机器人抓杯子"任务串联本系列全部知识点
11. 下一步阅读建议
完成这篇之后,再回头去看具体 VLA 模型,只需要盯四件事:
- 用什么视觉编码器
- 用什么融合方式
- 用什么动作表示
- 用什么时序建模
能把这四件事讲清楚,后续读大多数 VLA 论文就不会乱。
12. 本章小结
本章解决的问题: VLM 和 VLA 的本质区别,以及动作表示、时序建模、策略学习这三个 VLA 特有的核心问题。
在"抓杯子"任务中的作用: 动作头把 LLM 的隐藏状态转化为机械臂的关节角度;时序建模让模型能利用历史帧判断手臂当前状态;ACT 的 action chunk 让动作更稳定,不会因为单步误差累积而偏离轨道;Diffusion Policy 让模型能够从多种合理抓取方式中采样,而不是输出一个"折中"的错误动作。
在整个知识体系中的位置: 本章是系列的终章。它的作用不只是介绍 VLA,而是把前 5 章的所有内容——Transformer 注意力机制、LLM 生成、ViT 图像序列化、CLIP 对齐、多模态融合——整合成一个完整的、可以执行任务的系统。理解了这个系统,你就真正从"会看 VLM 论文"升级到了"能看懂 VLA 论文"。
后续学习建议: 现在你已经理解了从 Transformer 到 VLA 的完整技术栈。推荐按以下顺序阅读具体模型论文:
- RT-2(动作 token 化的代表)
- OpenVLA(开源 VLA 的代表)
- ACT(action chunk 的代表)
- Diffusion Policy(分布式动作建模的代表)
- π0(结合 VLM 和 Diffusion Policy 的新一代 VLA)