5. Open X 数据与跨机体迁移
先修建议
- 已理解 RT-1/RT-2 的动作建模与评测口径。
- 熟悉跨数据集归一化、训练混合与迁移评估的基本概念。
- 了解“机体差异”对观测、动作语义与部署方式的影响。
本节目标
- 明确 Open X 试图回答的核心问题,而不仅是记住数据规模。
- 读懂“粗对齐”为什么足以支撑跨机体联合训练。
- 区分论文已经验证的正迁移证据与尚未解决的开放问题。
Open X-Embodiment 常被简单概括成“一个更大的机器人数据集”,但这不是它最重要的价值。它真正想回答的是一个更基础的问题:当机器人数据在相机视角、动作空间、控制语义上都不统一时,只做粗对齐,是否已经足够支撑跨机体联合训练,并带来可测量的正迁移?
如果把 RT-1 看作“先证明机器人控制可以被稳定地 token 化和规模化训练”,把 RT-2 看作“再把大模型语义能力接进控制”,那么 Open X 更像是在补中间那层基础设施:先把分散在不同机构、不同机器人、不同任务定义里的数据,变成一个能共同训练的底座。
1. Open X 的问题
论文在引言里给出两个非常明确的目标:
- 检验跨机体训练是否会带来正迁移,也就是性能是否能超过“只在本机体数据上训练”的基线。
- 把分散的机器人数据整理成标准化仓库,降低后续跨机体研究的数据工程门槛。
这一定义很重要,因为它决定了本章的阅读重心不在“新模型结构”,而在“数据能否被组织起来并真的产生迁移收益”。
和前两章对照会更清楚:
| 章节 | 核心问题 | 主要增量 |
|---|---|---|
| RT-1 | 机器人控制能否统一建模 | 动作 token 化与可训练闭环 |
| RT-2 | 语义能力能否迁移到控制 | VLM 骨架与联合微调 |
| Open X | 异构机器人数据能否形成共同底座 | 数据仓库、粗对齐与跨机体验证 |
因此,读 Open X 时最该问的不是“它比 RT-2 大多少”,而是:
异构数据不被严格统一的情况下,为什么模型仍然可能学到跨机体可迁移的东西?
2. 为什么先建仓库
在 NLP 和计算机视觉里,大规模预训练已经把“先有共享底座,再做下游适配”变成默认范式。机器人学习长期做不到这一点,根本原因不是模型不够复杂,而是数据太碎:
- 不同实验室使用不同机器人、不同相机布局、不同控制接口。
- 同样是抓取任务,观测格式、动作定义、语言标注方式也可能完全不同。
- 许多数据集只服务某一种算法或某一个实验设置,难以直接拼接训练。
Open X 的第一步不是发明新损失,而是先把这些异构数据收拢到一个可复用仓库里。论文给出的规模如下:
1M+条真实机器人轨迹。22种 robot embodiments。60个已有子数据集。21个机构参与协作,底层数据来自34个研究实验室。- 覆盖
527种技能、160,266个任务描述。
这组数字的意义不只是“大”,而是第一次把“跨机构、跨机器人、跨场景”的异构数据以统一格式组织起来。
先看整体分布,再看细节构成:
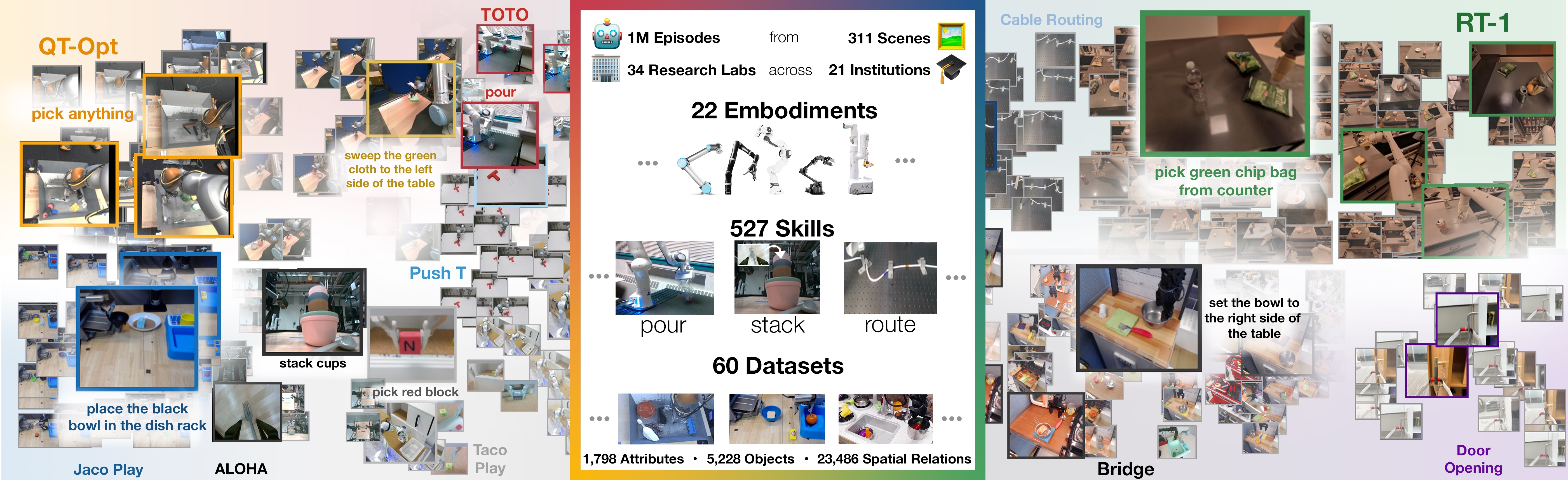
这张图更值得关注的不是总量,而是两点:
- 机体分布高度不均衡,说明这不是一个“均匀采样”的理想数据集。
- 数据来源足够多样,说明它更接近真实研究生态中的长尾数据拼接。
再看技能与对象分布:
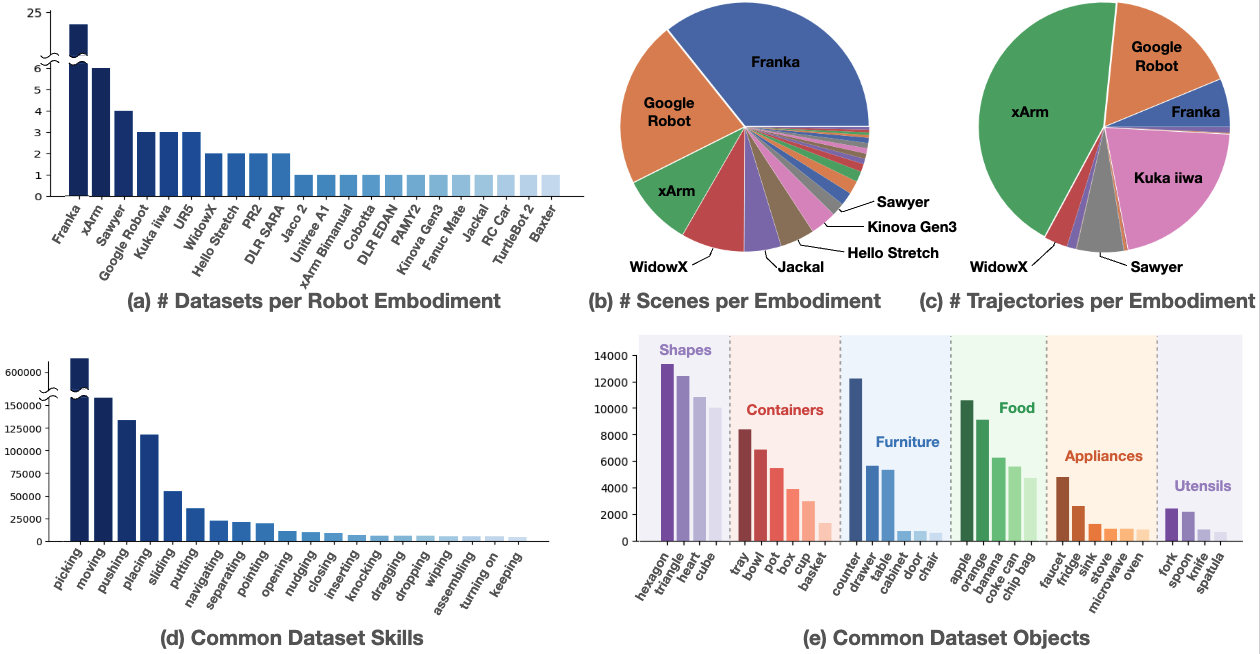
这里可以直接读出 Open X 的基本现实:
- 主体技能仍然集中在 pick-place 家族。
- 但长尾部分已经包含 wiping、assembling 等更复杂行为。
- Franka、xArm、Google Robot 等机体的数据量和场景数差异很大。
所以,Open X 的问题从一开始就不是“如何在理想均匀数据上训练”,而是“如何在真实、不均衡、强异构的数据拼盘上先建立可训练底座”。
3. 粗对齐策略
Open X 最关键的设计不是强行把所有机器人变成一种动作语义,而是采用论文原文所说的 coarsely aligned action and observation space,也就是“粗对齐”。
先看它统一的部分:
- 输入统一成图像历史加语言指令。
- 每个数据集选一个 canonical camera view,统一到相同输入分辨率。
- 动作被转换成
7维末端执行器控制量:x, y, z, roll, pitch, yaw, gripper。 - 训练前先在各自数据集内部做动作归一化,再进行离散化。
再看它刻意保留差异的部分:
- 不对齐不同机器人的坐标系。
- 不强制统一绝对控制和相对控制。
- 不要求所有机器人使用完全相同的物理执行语义。
这可以压缩成一张表来看:
| 统一项 | 保留差异 | 直接后果 |
|---|---|---|
| 图像历史 + 语言指令 | 相机位姿、成像属性不同 | 视觉输入形式统一,但视角语义仍有域差 |
| 7 维末端执行器动作外形 | 坐标系、绝对/相对、位置/速度定义不同 | 动作张量能拼接训练,但同一 token 在不同机体上物理含义不同 |
| 每数据集归一化后离散化 | 各数据集自己的反归一化规则 | 模型先学共享统计结构,再由部署端解释为各自动作 |
这正是 Open X 最值得理解的地方:
它没有试图先消灭 embodiment gap,而是接受 gap 的存在,只要求所有数据至少能进入同一个训练接口。
因此,同一个离散动作 token 在不同机器人上并不保证表示同一种真实运动。模型学到的更像是一种“在该数据集上下文中,这类视觉-语言条件通常对应哪类动作模式”的统计对应关系。部署时,再由各自数据集的反归一化规则把它翻译回该机器人能执行的控制量。
这种设计的优点是工程可落地,缺点是语义并不严格一致。Open X 的贡献恰恰在于:即使只做到这一步,论文实验里依然观察到了正迁移。
4. RT-X 如何使用 Open X
有三个数字在这篇论文里很容易被混淆,最好分开记:
| 数字 | 含义 |
|---|---|
22 | OXE 仓库覆盖的总机体数 |
9 | 论文实验时实际用于 robotics mixture 训练的机体数 |
6 | 真实机器人评测覆盖的机器人数量 |
论文之所以反复说明这一点,是因为数据仓库和实验训练混合并不是一回事。
Open X 仓库在持续增长,但论文实验发生在一个较早时间点,所以真正进入训练的 robotics mixture 只覆盖 9 个机体,而不是仓库里的全部 22 个。
模型设置沿用了前两章已经见过的 RT-1 和 RT-2 路线:
RT-1-X:35M参数,只用 robotics mixture 训练。RT-2-X:建立在 RT-2 的 VLM 骨架上,用 robotics mixture 和原始 vision-language data 共同训练。- RT-2-X 的数据混合比例约为
1:1,也就是机器人数据与原始 VLM 数据大致对半。 - 推理部署频率按机器人需求运行在
3-10 Hz,RT-1-X 本地推理,RT-2-X 通过云端服务推理。
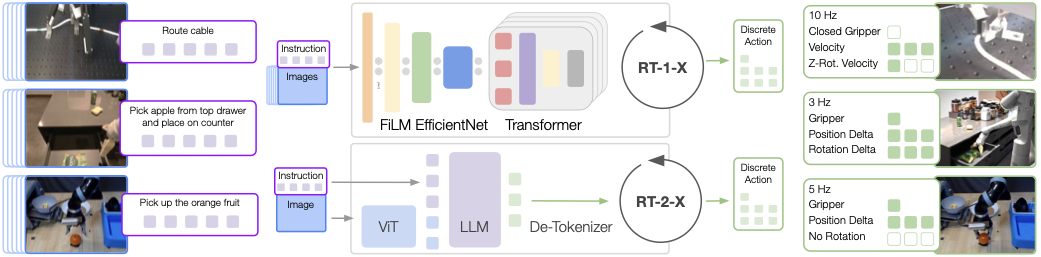
这里最重要的理解不是“Open X 又发明了两个新模型”,而是:
- 它用 RT-1-X 测试“机器人专用中等容量架构”能否吸收多机体数据。
- 它用 RT-2-X 测试“高容量、带 Web 预训练的 VLA”是否更能把跨机体数据转成收益。
也就是说,Open X 的实验设计本身就在回答一个问题:
跨机体训练是否有效,是否取决于模型容量和预训练底座?
5. 关键实验结论
论文总共进行了 3600 次真实机器人试验,覆盖 6 台机器人。结果最好按三个层次来读,而不要只看单个均值。
5.1 小数据域受益
对于 Jaco Play、Cable Routing、NYU Door、UR5、Robot Play 这些相对小规模的数据域,RT-1-X 在 5 个域中有 4 个超过了对应的单域方法。论文给出的总体结论是:RT-1-X 的平均成功率相对 Original Method 和单域 RT-1 提升约 50%。
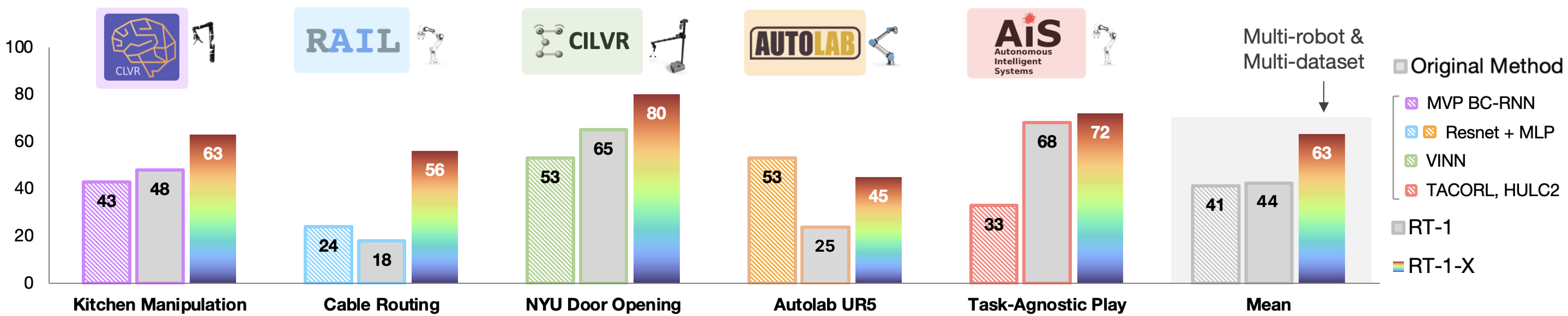
这一组结果说明了第一个核心结论:
当单个机体自身数据不够多时,来自其他机器人和其他场景的数据,确实可能提供有用补充。
5.2 大数据域与容量瓶颈
在 Bridge 和 Google Robot 这类高数据量场景里,情况明显复杂得多:
| 评估场景 | RT-1 | RT-1-X (35M) | RT-2-X (55B) |
|---|---|---|---|
| Bridge (Stanford) | 40% | 27% | 50% |
| Bridge (Berkeley) | 30% | 27% | 30% |
| Google Robot 6 skills | 92% | 73% | 91% |
这张表最重要的信号不是“RT-2-X 最高”,而是:
RT-1-X在大数据域里反而不如单域 RT-1,说明35M这一档容量不足以同时吸收大规模、强异构的机器人数据。RT-2-X在更高容量和 Web 预训练支撑下,开始把跨机体训练的潜力转化为可见收益。
因此,Open X 给出的不是“多机体训练天然更强”这样的简单结论,而是更精确的说法:
跨机体数据可以带来收益,但当数据本身已经很大、异构性也更强时,容量和预训练会变成前提条件。
5.3 最强迁移证据
论文最有说服力的一组实验不是常规 in-distribution 指标,而是 emergent skills evaluation。
这组评测考察的是:
Google Robot 上原本没有的数据技能,是否能因为训练时看到了来自 Bridge 数据集里的 WidowX 经验,而表现出新的能力。
关键结果如下:
- RT-2:
27.3% - RT-2-X:
75.8% - RT-2-X 去掉 Bridge 数据后:
42.8%

这组结果之所以重要,是因为它给出了一条相对明确的证据链:
- 目标技能不在 Google Robot 原始训练数据里。
- 这些技能出现在另一个机器人平台 WidowX 的 Bridge 数据里。
- 加入这些跨机体数据后,Google Robot 上的成功率大幅上升。
- 去掉 Bridge 数据后,收益明显回落。
这比单纯“平均分更高”更接近真正的跨机体知识转移证据。
6. 收益为何不自动出现
Open X 还有一组非常关键的结论,解释了为什么前面的收益并不是“只要把数据堆在一起就会发生”。
论文消融重点比较了四个变量:模型容量、Web 预训练、历史帧输入,以及 co-fine-tuning 和 fine-tuning 的差别。
从结果里可以直接读出下面几条规律:
- 历史帧有效:
5B模型里,history=2明显优于 history=none。 - Web 预训练关键:
5B模型从头训练几乎完全失效,说明机器人数据本身还不足以支撑这类大模型从零学起。 - 容量影响显著:
55B的 RT-2-X 在 emergent skills 上明显高于5B。 - 在 Open X 这组更异构的数据混合下,co-fine-tuning 和 fine-tuning 的差距没有 RT-2 论文里那么大,作者将其归因于机器人数据本身已经更丰富。
这几条结论合在一起,实际上把 Open X 的经验收束成一句话:
数据底座很重要,但只有当模型有足够容量,并且具备足够强的预训练先验时,跨机体数据的价值才更容易被真正吸收。
这也是为什么 Open X 在章节位置上很适合作为 RT-2 和 OpenVLA 之间的过渡。它告诉读者,后续研究不能只讨论“模型有没有更强”,还必须讨论“数据底座是否足够大、足够杂、且能被模型吃进去”。
7. 论文的边界
为了避免过度外推,Open X 的边界同样需要写清楚。
论文明确没有解决以下问题:
- 没有覆盖感知和执行模态差异特别大的机器人族群。
- 没有系统检验对全新机器人平台的泛化能力。
- 没有给出“什么时候会正迁移、什么时候会负迁移”的判定准则。
这意味着本章在解读时要避免三个常见误读:
- 不应把“多机体数据有效”理解成“对所有机器人都自动有效”。
- 不应把“55B 更强”简化成“只要继续增大参数就一定能解决问题”。
- 不应把 Open X 当成已经解决 embodiment gap 的方案;它证明的是“粗对齐也能先工作起来”,不是“gap 已经消失”。
8. 小结与过渡
本章可以收束成三句话:
- Open X 的第一贡献不是新模型,而是把跨机构、跨机器人、跨任务的数据整理成可共同训练的标准化仓库。
- 即使只做粗对齐,跨机体 co-training 也已经能在多个场景里产生正迁移,尤其在小数据域和跨机体技能迁移上证据明确。
- 这种收益不是自动出现的,它强依赖模型容量、预训练底座以及模型是否真的能吸收这类异构数据。
因此,Open X 在 VLA 发展链条里的位置很清楚:
RT-1 证明“控制可以统一建模”,RT-2 证明“语义可以迁移到控制”,而 Open X 进一步证明“异构机器人数据也可以先被组织成一个共同的训练底座”。
下一讲进入 OpenVLA,重点将从“数据底座与跨机体验证”转向“一个开源 VLA 如何在架构、训练接口和工程复现上真正落地”。