9. pi0 架构与训练配方
先修建议
- 已完成 RT-1 / RT-2 / ACT / Diffusion Policy 章节阅读,理解离散动作 token 与连续动作生成的差异。
- 熟悉行为克隆(BC)与条件生成模型的基本概念。
- 对 Transformer 的 token、attention mask、KV cache 有基础认识。
本节目标
- 建立 π₀ 的完整问题定义:输入、输出、训练目标与推理方式。
- 看懂 π₀ 为什么采用
VLM 主干 + Action Expert + Flow Matching的三段式设计。 - 理解 π₀ 的训练配方(pre-training / post-training)如何与架构配合。
- 用论文中的实验证据判断 π₀ 的能力边界,而非只看单个 demo。
π₀ 是 Physical Intelligence 提出的通用机器人策略模型。它把互联网规模的视觉语言预训练、跨机体机器人数据、连续动作块生成和分阶段训练配方放进同一套框架,用来处理需要语义理解、灵巧操作和长期执行稳定性的真实机器人任务。
1. pi0 定位
π₀ 关注的核心问题不是“单任务精度再提高一点”,而是:同一套参数如何在跨机体、跨任务条件下保持语义理解与连续控制能力。
论文把 robot foundation model 的难点概括为三类:
- 规模:足够多样的机器人数据才能覆盖不同物体、场景、失败状态和恢复行为。
- 架构:模型既要继承 VLM 的语义能力,又要能表达高频、连续、多峰的动作分布。
- 训练配方:预训练负责广覆盖,后训练负责让策略执行得更流畅、更稳定。
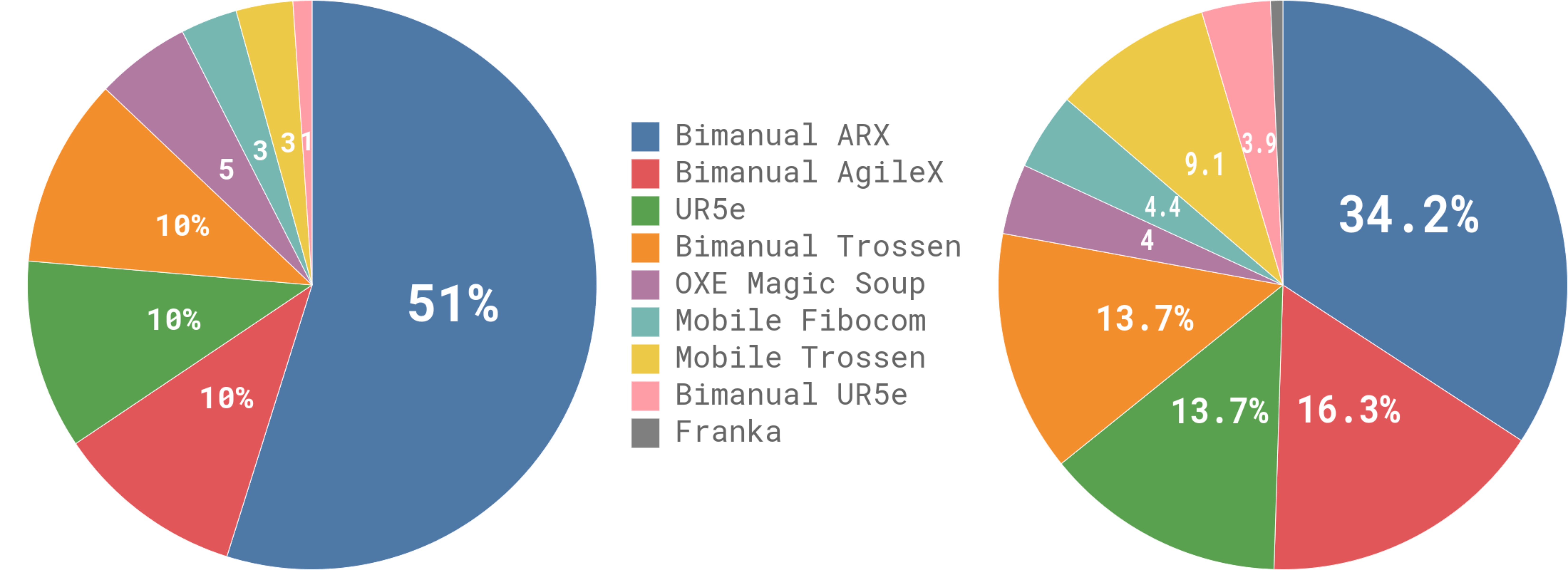
这三点决定了 π₀ 从一开始就不是“单机体策略”,而是“跨机体基础模型”路线。在论文宏定义中,作者自采数据覆盖 7 种机器人配置(\Robots=7)与 68 类任务(\Tasks=68),并叠加 OXE、Bridge、DROID 等开源数据做跨机体训练。
读图重点:下面这张图主要看“机体形态跨度”,不是看某一个单项任务分数。

2. 任务定义
π₀ 的核心建模对象是条件动作块分布:
其中:
- 观测
- 动作块
这一定义有两个直接后果:
- 模型每次不是只预测一步,而是预测一个未来动作块(action chunk)。
- 输出是连续动作分布,不是离散 token 分类。
| 符号 | 含义 |
|---|---|
| 时刻 | |
| 从 | |
| 动作块长度,论文设为 50 | |
| Flow Matching 的时间步,范围 | |
| 推理积分步长,论文设为 0.1(10 步) |
3. 数据体系与训练阶段
π₀ 的训练并非“单阶段端到端”,而是显式分为 pre-training 与 post-training 两阶段。
3.1 Pre-training:先学广覆盖
预训练混合数据由两部分组成:
- 自采高难灵巧操作数据。
- 开源机器人数据(OXE / Bridge / DROID 等)。
论文按 timestep 统计时给出了一些关键口径:
- 预训练混合中约
9.1%来自开源数据。 - 自采数据约
903Msteps,其中单臂约106M、双臂约797M。 - OXE 子集本身包含来自 22 种机器人的数据来源。
预训练阶段的语言标注也不只是任务名。论文同时使用 task name 与 segment annotation:后者是约 2 秒粒度的子轨迹标签,用来描述更细的中间行为。这一点会影响后面的语言跟随实验,因为 π₀ 不只学习“完成一个大任务”,还学习“根据中间语言指令切换子行为”。
读图重点:这张图主要看“数据分布与采样权重”,不是简单看柱状图高低。
3.2 数据对齐与加权策略
为解决跨机体动作空间不一致,论文采用统一表示:
- 配置向量与动作向量统一到 18 维。
- 低维机器人通过 zero-padding 对齐。
- 少于 3 路相机的机体,对缺失图像槽位做 mask。
采样方面,任务-机体组合按
这里的“任务”不是简单的动词-名词组合。例如 bussing task 内部可能包含识别餐具与垃圾、抓取、倾倒、分类放置等多个行为。因此,68 类任务低估了真实行为分布的复杂度。
3.3 Post-training:再学任务质量
post-training 使用更小但更高质量的任务数据集做专项适配。论文给出范围:简单任务约 5 小时,复杂任务可达 100+ 小时。
这套“先广覆盖、再高质量专项”的训练配方与大模型常见的 pretrain / post-train 分工一致:
- pre-training 提供广泛可迁移能力。
- post-training 提供任务执行风格、稳定性与完成质量。
论文特别强调两类数据的互补性:只有高质量数据时,模型很少见到错误与恢复;只有广覆盖预训练数据时,策略又可能缺少高效、流畅的执行风格。π₀ 的训练配方把这两者拆开处理。
4. 模型架构
读图重点:这张图展示的是 π₀ 的整体框架,不是单纯的数据流程图。左侧是预训练数据混合,中间是 VLM Backbone + Action Expert,右侧是同一模型面向不同机体输出连续动作块。
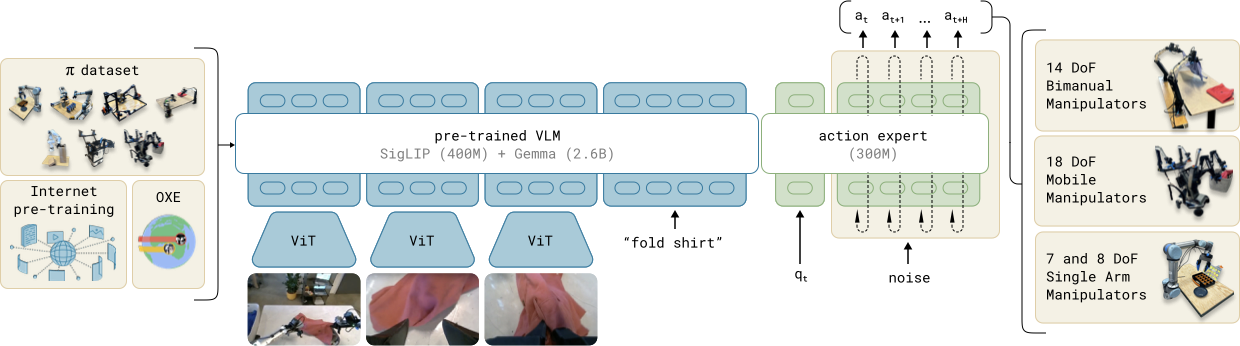
4.1 从 PaliGemma 到 pi0
π₀ 以 PaliGemma 3B 为主干,新增动作专家模块约 300M 参数,总规模约 3.3B。
相对标准 VLM,π₀ 额外引入:
- 本体状态输入
。 - 噪声动作块输入
。 - 对应动作 token 的向量场输出头
。
PaliGemma 在这里不是唯一可选项。论文选择它主要是因为 3B 规模在语义能力与实时控制预算之间比较折中;原则上,这个框架可以替换成其他预训练 VLM。
4.2 Action Expert 与 token 路由
π₀ 可以理解为“单个 Transformer + 两套专家权重”:
- 图像与语言 token 路由到较大的 VLM backbone。
- 本体状态与动作 token 路由到 Action Expert。
- 两套权重主要在 self-attention 层发生交互。
作者将 Action Expert 做了降宽(例如 width=1024, mlp_dim=4096),核心目的是降低多次积分推理时的计算成本。
这部分设计受 Transfusion 类方法启发:同一个 Transformer 序列里既有离散语言 token,也有连续动作 token。语言侧仍保留 VLM 的预训练能力,动作侧则通过 Flow Matching 损失监督。π₀ 的额外变化是给机器人相关 token 单独使用 Action Expert 权重,避免把未在 VLM 预训练中出现过的 state/action token 全部压到原始 VLM 参数里。
4.3 Attention Mask 与
论文附录描述的 mask 机制是 blockwise causal(按 block 的先后做因果屏蔽),并且每个 block 内部是双向注意力:
- block 1:
- block 2:
- block 3:
该设计的工程含义:
- 前缀 block 不看未来 block,减少对 VLM 预训练分布的扰动。
- 状态 block 单独隔离,便于推理阶段缓存对应 KV。
- 动作 block 可看全输入,满足条件生成需要。
Flow timestep
5. Flow Matching 训练机制
5.1 主线版:训练到底在拟合什么
π₀ 使用条件 Flow Matching 损失:
概率路径采用线性高斯形式:
训练时采样
直观上,网络学的是“从带噪动作块回到干净动作块的速度方向”。
5.2 推理版:如何把向量场变成动作
推理从纯噪声动作块开始,按 Euler 规则从
论文设置:
- 共 10 步积分
5.3 可选深入:为什么强调低
附录给出的采样分布并非简单均匀,而是 shifted Beta:
读图重点:图中关注“低
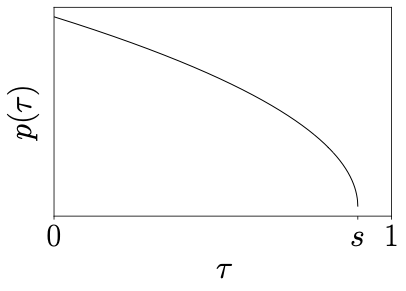
该策略的经验动机是:动作预测任务在高噪声区域往往更难,训练预算向低
6. 推理控制与系统预算
6.1 推理链路
一次动作块推理包含三段计算:
- 图像编码。
- 观测前缀前向(可缓存 KV)。
- 10 次动作后缀前向(Flow 积分步骤)。
附录给出的 RTX 4090 实测时延(3 路相机)如下:
| 模块 | 时延 |
|---|---|
| image encoders | 14 ms |
| observation forward pass | 32 ms |
| x10 action forward pass (flow) | 27 ms |
| network latency(off-board) | 13 ms |
| total on-board | 73 ms |
| total off-board | 86 ms |
这组数字说明:π₀ 的“可部署”不是免费获得的,而是依赖 前缀缓存 + 专家降宽 + 多步后缀复用 的系统优化。
6.2 控制执行策略
虽然模型每次生成
- 20Hz 的 UR5e / Franka:每 0.8s 推理一次(执行 16 步)。
- 50Hz 的其他机器人:每 0.5s 推理一次(执行 25 步)。
此外,作者报告早期尝试过 temporal ensembling,但性能下降,最终采用 open-loop 执行 chunk。
7. 实验结果与能力边界
论文的实验不只是在展示 demo,而是在回答四个问题:
- 只做 pre-training 的 base model 是否具备 out-of-box 能力。
- VLM 初始化是否改善语言跟随。
- 预训练对新任务微调是否有帮助。
- pre-train + post-train 是否能支撑复杂多阶段任务。
除非特别说明,论文中的真实机器人评估通常按每个任务、每个方法 10 次试验取平均,并使用部分完成分数。例如 bussing 类任务按正确分类/放置的物体数量计分,而不是只记录全成败。
7.1 Out-of-box 基础能力
论文在 pre-training 后直接评估 base model(不做 post-training),并与 OpenVLA、Octo 以及不使用 VLM 初始化的 π₀-small 对比。
评测任务包括 shirt folding、bussing easy、bussing hard、grocery bagging、toast out of toaster。这些任务都可以直接用语言命令触发,用来测试 base model 是否已经学到可迁移的基础能力。

读图重点:关注“full π₀ 与 compute-parity π₀”都能超过对比方法这一点。compute-parity π₀ 只训练 160k steps,用来对齐 OpenVLA / Octo 的训练更新量;完整 π₀ 训练 700k steps。
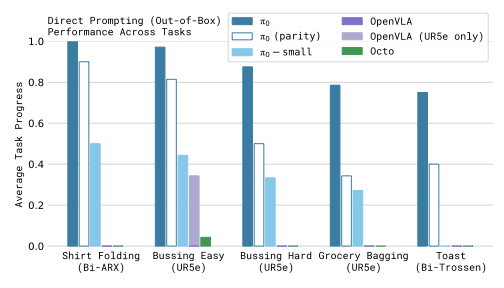
这组实验里有两个关键解释:
- OpenVLA 使用自回归离散动作,不支持高频 action chunk,因此在这些灵巧任务上吃亏。
- Octo 支持类似扩散的动作生成,但模型容量与语义主干弱于 π₀。
π₀-small 也优于部分基线,但它不是完全公平的“只去掉 VLM 初始化”消融:论文说明它参数量约 470M,同时架构也有若干调整。因此,这里更适合把它理解为“没有互联网 VLM 语义底座的小模型参照”。
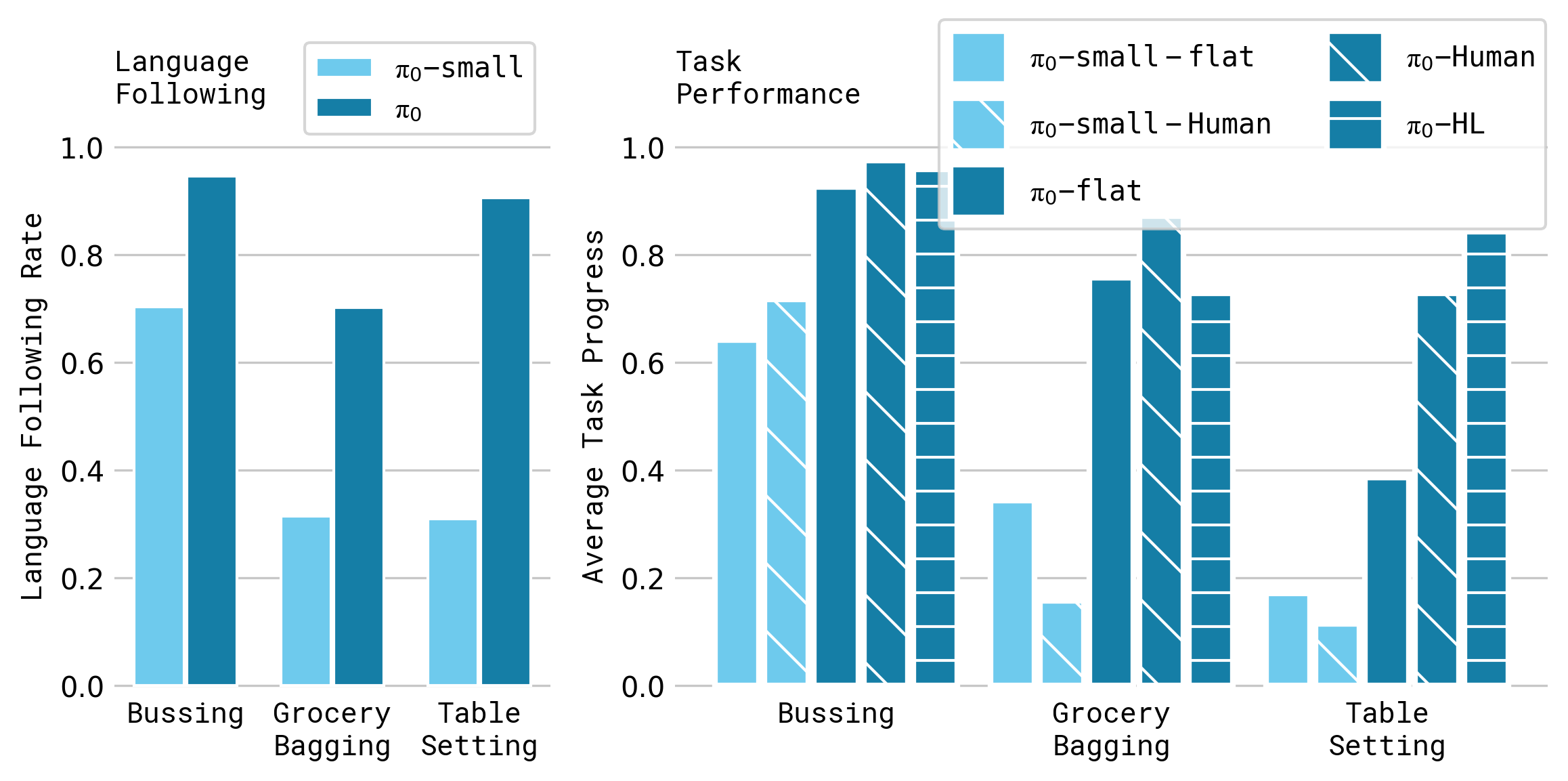
7.2 语言跟随能力
语言实验比较了多种条件:
-flat:只给高层任务描述。-human:给中间子任务语言指令。-HL:由高层 VLM 生成中间指令。
实验任务包括 bussing、table setting、grocery bagging。每个完整任务由多个约 2 秒粒度的语言标注片段组成,模型需要根据中间指令选择正确物体和目标位置。

结果显示,使用 VLM 初始化的 π₀ 在语言跟随准确性上显著优于 π₀-small,且这种差异会转化为复杂任务中的执行收益。尤其是 -human 与 -HL 的对比说明:中间指令本身有用,但前提是底层策略能可靠理解这些指令。
读图重点:看“同一任务下,语言条件变化带来的性能分化”。
7.3 新任务微调与预训练收益
在若干与预训练数据分布差异较大的下游任务中,论文比较了:
- 从预训练 π₀ 继续微调。
- 同架构从零训练。
- 其他已有方法的微调或训练方案。
论文把这些新任务按与预训练分布的距离分成不同难度层级:stack bowls 与 towel folding 更接近预训练任务;Tupperware in microwave 引入未见过的微波炉元素;paper towel replacement 与 Franka items in drawer 则需要新的物体、动作或机体组合。

论文报告的趋势是:
- 与预训练更相近的任务,迁移收益更明显。
- 在小样本微调设置下,预训练版本常显著优于非预训练版本,部分任务可达约 2x 量级改进。
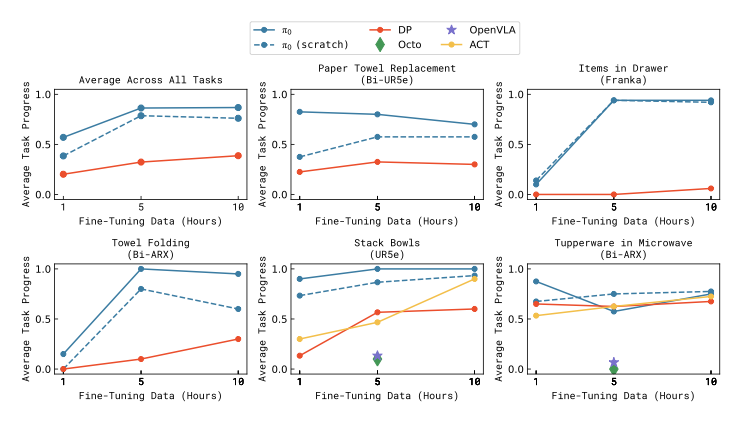
需要注意的是,ACT 与 Diffusion Policy 在这组实验中只使用目标任务数据训练;OpenVLA 与 Octo 使用公开预训练 checkpoint 后再微调。π₀ 的比较目标不是证明某个单点任务一定更优,而是说明“大模型语义初始化 + 连续动作块生成 + 跨机体预训练”组合起来更适合这类真实灵巧操作。
7.4 复杂多阶段任务
作者还评估了 laundry folding、table bussing、box building、packing eggs 等更长时序任务。报告结论显示:完整的 pre-train + post-train 配方通常优于去除预训练或仅靠下游数据从零训练的变体。
这些任务往往持续 5 到 20 分钟,包含几十个子行为。例如 table bussing 不只是“把东西放进箱子”,还要求识别餐具/垃圾、在遮挡和密集杂乱中抓取、按类别放置。box building 则需要双臂协同折纸箱,并在失败折叠后重新调整。

读图重点:这里看“完整 pre-train + post-train 是否稳定超过 ablation”,不只看单步动作精度。部分任务在 pre-training 中出现过,部分任务没有出现过;这正好用来观察预训练是否能提供可迁移的恢复与组合能力。
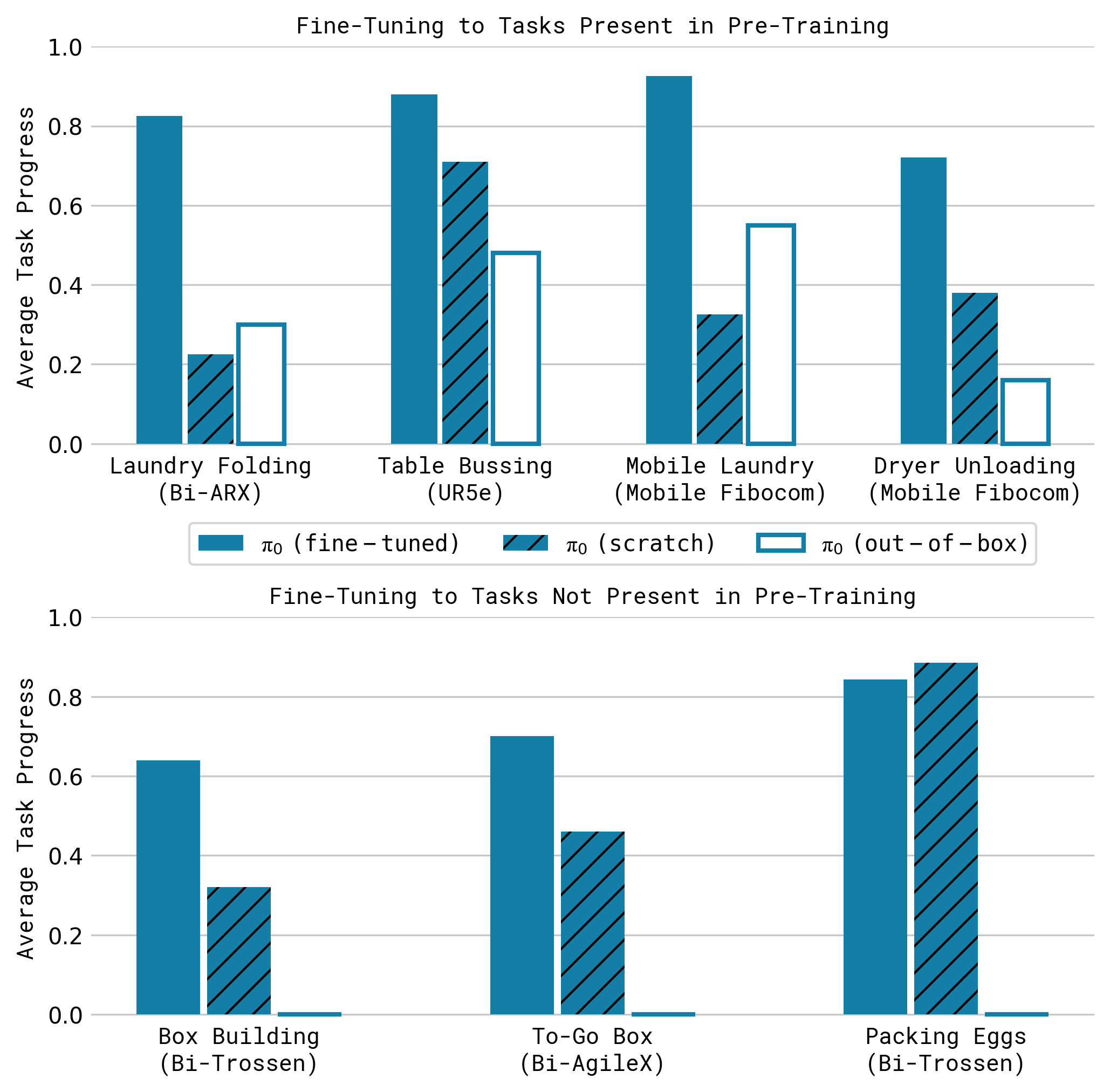
7.5 能力边界(基于实验与讨论)
从主文与讨论段落可以提炼出三条边界:
- 任务成功率仍随任务难度与数据覆盖度显著波动。
- 预训练数据“如何组成最优配方”仍是开放问题。
- 跨任务、跨机体的正迁移虽然存在,但其适用范围还未被系统刻画。
8. 局限与过渡
π₀ 的关键价值在于把三件事放进同一框架并跑通:
- 用预训练 VLM 提供语义底座。
- 用 Action Expert 与连续动作块建模高频控制。
- 用可部署的推理策略把多步 Flow Matching 落到真实系统。
同时,论文也明确保留了后续研究空间:
- 数据配比与混合策略仍有较大优化空间。
- 复杂任务的稳定性与可预测性仍需提升。
- 模型的“通用性”是否能扩展到更远域(如导航、驾驶、腿足)尚无定论。
这也是下一讲的自然过渡点:在已有跨机体能力基础上,进一步讨论 open-world 场景中的泛化与长期执行稳定性问题。